Tridis
收藏Hugging Face2024-12-06 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/magistermilitum/Tridis
下载链接
链接失效反馈官方服务:
资源简介:
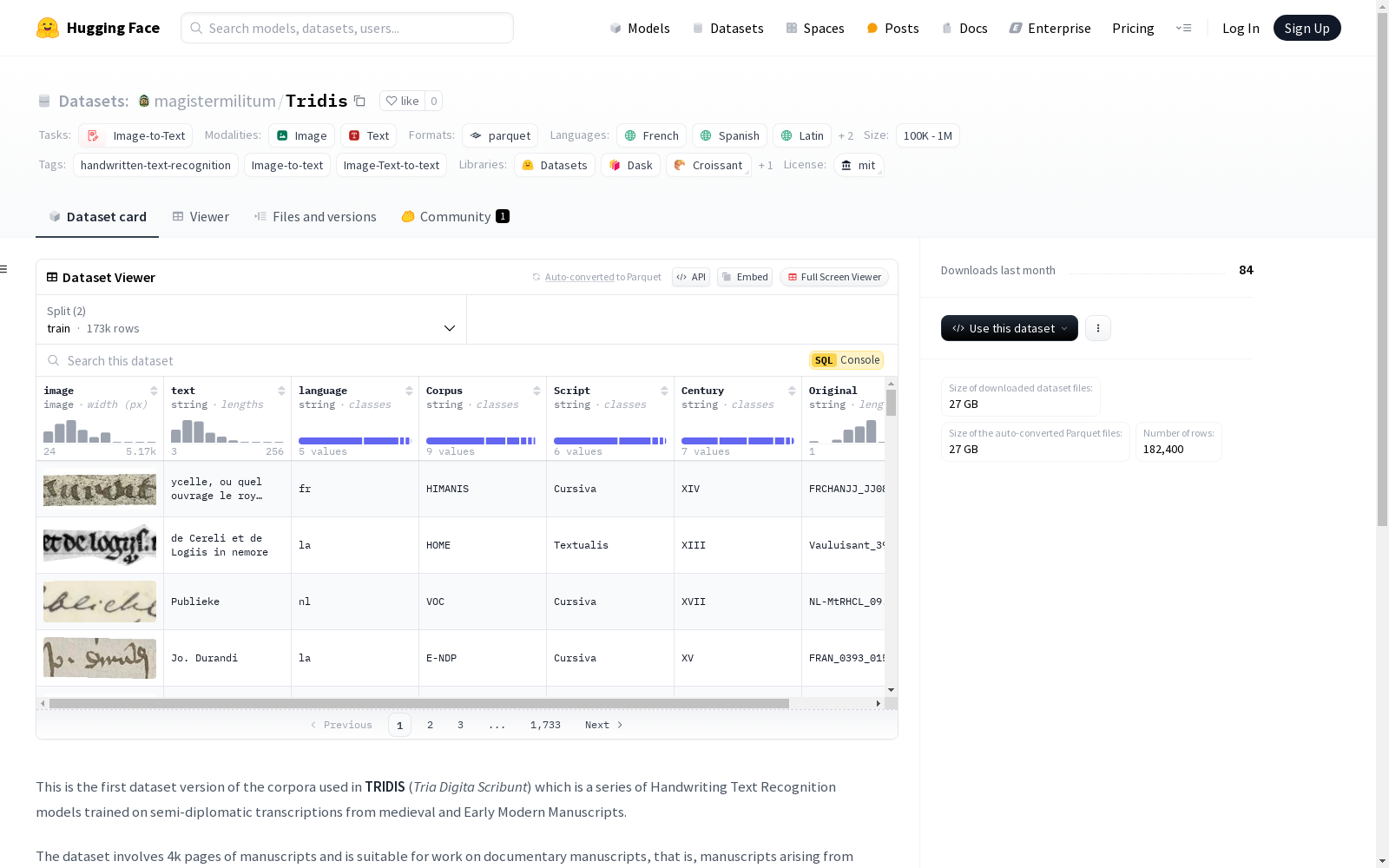
TRIDIS数据集包含4000页的中世纪和早期现代手稿,适用于法律、行政和纪念性实践的手稿,如登记册、封建书、特许状、诉讼程序、会计等。数据集的特征包括图像、文本、语言、语料库、脚本、世纪和原始信息。数据集分为训练集和验证集,分别包含173280和9120个样本。数据集的下载大小为27038197883字节,总大小为27043411358字节。数据集适用于手写文本识别、图像到文本和图像文本到文本的任务。数据集的语言包括法语、西班牙语、拉丁语、德语和荷兰语。原始语料库可从多个在线资源中获取。
The TRIDIS Dataset consists of 4000 pages of medieval and early modern manuscripts for legal, administrative and commemorative practices, including registers, feudal books, charters, judicial proceedings, accounting records and other relevant documents. Key features of the dataset include images, text, language, corpus, script, manuscript century and original information. The dataset is split into training and validation subsets, which contain 173280 and 9120 samples respectively. The download size of the dataset is 27038197883 bytes, with a total storage size of 27043411358 bytes. This dataset is applicable to tasks such as handwritten text recognition, image-to-text and image-text-to-text. The languages covered by the dataset are French, Spanish, Latin, German and Dutch. The original corpus can be accessed from multiple online resources.
创建时间:
2024-12-05
原始信息汇总
Tridis 数据集概述
数据集信息
特征
- image: 图像数据
- text: 文本数据
- language: 语言
- Corpus: 语料库
- Script: 脚本
- Century: 世纪
- Original: 原始数据
数据分割
- train: 训练集,包含173280个样本,大小为25684445379字节
- validation: 验证集,包含9120个样本,大小为1358965979字节
数据集大小
- download_size: 27038197883字节
- dataset_size: 27043411358字节
配置
- config_name: default
- data_files:
- train: data/train-*
- validation: data/validation-*
- data_files:
标签
- handwritten-text-recognition
- Image-to-text
- Image-Text-to-text
任务类别
- image-to-text
语言
- fr: 法语
- es: 西班牙语
- la: 拉丁语
- de: 德语
- nl: 荷兰语
数据集名称
- pretty_name: Tridis
数据集规模
- size_categories: 100M<n<1B
数据集描述
- TRIDIS 数据集包含4000页手稿,适用于文档手稿的工作,如法律、行政和纪念性实践中的登记册、封建书籍、宪章、诉讼、会计等,主要来自中世纪晚期(13世纪及以后)。
原始语料库
- Alcar-HOME database (HOME): https://zenodo.org/record/5600884
- e-NDP corpus (E-NDP): https://zenodo.org/record/7575693
- Himanis project (HIMANIS): https://zenodo.org/record/5535306
- Königsfelden Abbey corpus (Konigsfelden): https://zenodo.org/record/5179361
- 6000 ground truth of VOC and notarial deeds (VOC): https://zenodo.org/records/4159268
- Bullinger, Ruolph Gwalther: https://zenodo.org/records/4780947
- CODEA: https://corpuscodea.es/
- Monumenta Luxemburgensia (MLH): www.tridis.me
搜集汇总
数据集介绍
构建方式
Tridis数据集的构建基于中世纪和近代早期手稿的半外交转录文本,涵盖了法律、行政和纪念性实践的文档手稿,如登记簿、封建书、契约、诉讼记录和会计记录等。数据集整合了多个在线资源库的原始数据,包括Alcar-HOME数据库、e-NDP语料库、Himanis项目、Königsfelden Abbey语料库等,确保了数据的多样性和广泛性。这些资源经过精心筛选和处理,形成了包含4000页手稿的高质量数据集,为手写文本识别模型提供了丰富的训练和验证材料。
特点
Tridis数据集的显著特点在于其专注于手写文本识别领域,特别是中世纪和近代早期的手稿文本。数据集不仅包含了图像和对应的文本,还提供了语言、语料库、书写系统、世纪和原始信息等多维度元数据,使得研究者能够进行更深入的分析和模型训练。此外,数据集的多样性体现在其涵盖了多种语言和书写系统,如法语、西班牙语、拉丁语、德语和荷兰语等,为跨语言和跨文化的研究提供了可能。
使用方法
Tridis数据集适用于手写文本识别、图像到文本转换以及图像文本到文本转换等任务。研究者可以通过加载数据集的训练和验证分割,利用图像和文本对进行模型训练和评估。数据集的元数据信息可以用于进一步的分析和模型优化,例如根据不同的语言或书写系统进行细粒度的模型调整。此外,数据集的开放性和多样性使其成为跨学科研究的宝贵资源,特别是在历史文献学和计算机视觉的交叉领域。
背景与挑战
背景概述
Tridis数据集,源自**TRIDIS**项目(*Tria Digita Scribunt*),是一个专注于手写文本识别(Handwriting Text Recognition, HTR)的开创性数据集。该项目由一系列基于中世纪和近代早期手稿的半外交转录文本训练的模型构成。Tridis数据集包含了来自多个在线资源库的4000页手稿,这些手稿主要来源于法律、行政和纪念性实践,如登记簿、封建书籍、契约、诉讼记录和会计记录,尤其集中于中世纪晚期(13世纪及以后)。该数据集的创建不仅为手写文本识别领域提供了丰富的资源,还为研究中世纪和近代早期的历史文献提供了宝贵的数据支持。
当前挑战
Tridis数据集在构建过程中面临了多重挑战。首先,手写文本识别本身就是一个复杂的问题,尤其是处理中世纪和近代早期的手稿,这些手稿往往具有复杂的字体、模糊的笔迹和不一致的格式。其次,数据集的构建需要从多个在线资源库中整合和标注大量的手稿页面,这一过程不仅耗时且需要高度的专业知识。此外,确保数据集的多样性和代表性也是一个重要挑战,因为不同地区和时期的手稿在风格和内容上存在显著差异。最后,如何有效地处理和利用这些数据进行模型训练,以提高手写文本识别的准确性和鲁棒性,也是该数据集面临的关键问题。
常用场景
经典使用场景
Tridis数据集在手写文本识别领域展现了其经典应用场景,特别适用于中世纪和近代早期手稿的半外交转录。该数据集通过结合图像与文本信息,为研究者提供了丰富的手稿页面数据,使其能够训练和优化手写文本识别模型,从而在历史文献的数字化和自动化处理方面发挥重要作用。
解决学术问题
Tridis数据集通过提供高质量的手稿图像和对应的文本转录,解决了手写文本识别领域中的关键学术问题。它不仅促进了历史文献的数字化进程,还为跨语言和跨文化的文本识别研究提供了宝贵的资源,推动了手写文本识别技术在历史学、语言学等领域的应用和发展。
衍生相关工作
基于Tridis数据集,研究者们开发了多种手写文本识别模型,并在多个国际会议和期刊上发表了相关研究成果。这些工作不仅提升了手写文本识别的准确性和效率,还推动了跨语言和跨文化文本识别技术的发展。此外,该数据集还激发了对手稿数字化和自动化处理技术的进一步研究,为文化遗产保护和历史研究提供了新的工具和方法。
以上内容由遇见数据集搜集并总结生成


