wangyueyiiiiiii/ContextDialog
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/wangyueyiiiiiii/ContextDialog
下载链接
链接失效反馈官方服务:
资源简介:
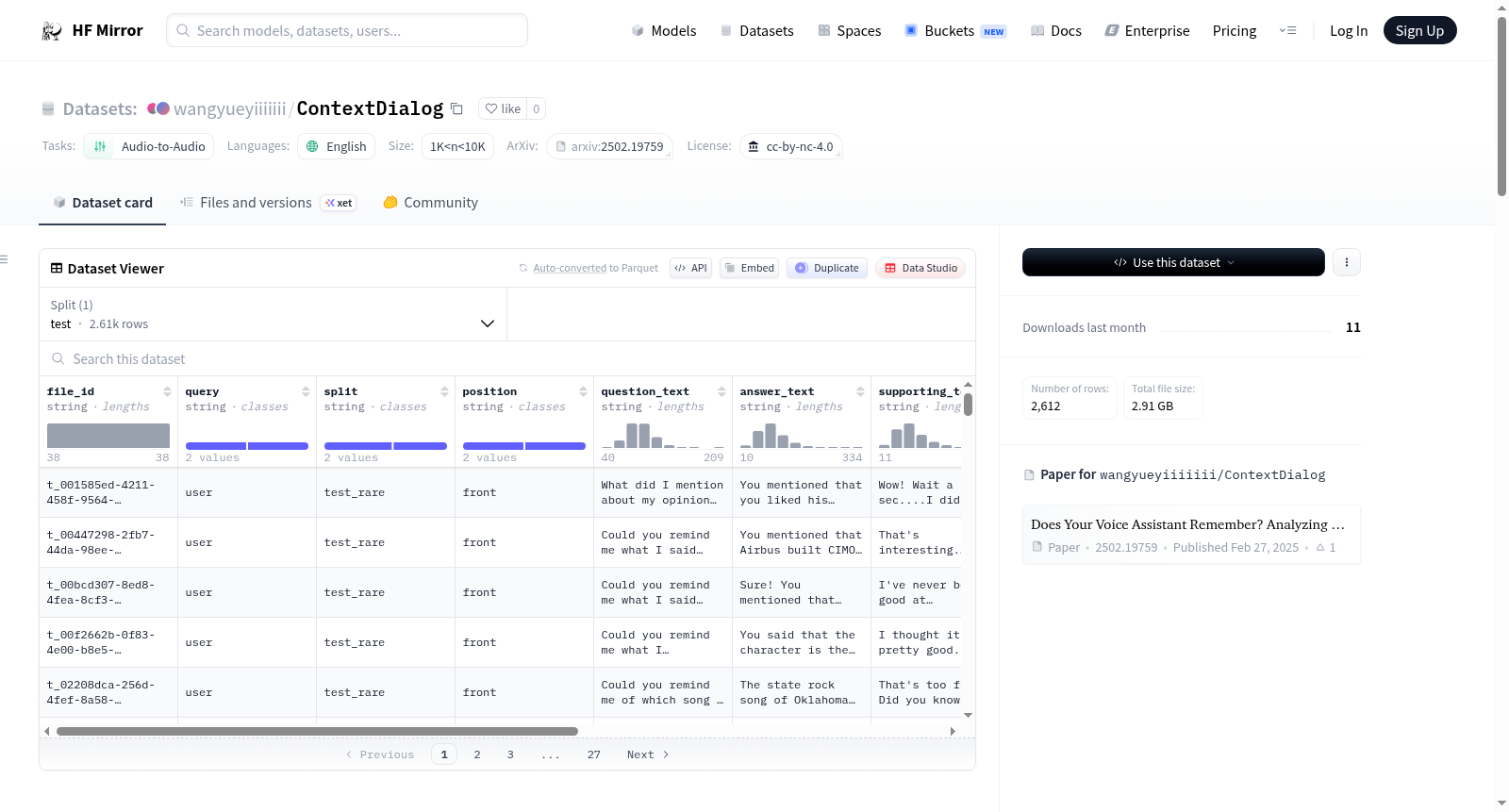
ContextDialog是一个全面的基准测试,旨在评估语音交互模型在多轮对话中参与、保留和利用相关信息的能力,反映现实世界中人们经常忘记和重新访问过去交流的场景。该数据集基于MultiDialog构建,包含约340小时的数据,涉及12位发言者,每段对话至少10轮。数据集包含测试集,分为test_freq和test_rare两个子集,分别包含363和290段对话,以及1,452和1,160个问答对。数据集的字段包括文件ID、位置、查询类型、分割类型、问题音频、回答音频、问题文本、回答文本和支持文本等。
ContextDialog is a comprehensive benchmark designed to evaluate a voice interaction model’s ability to engage in, retain, and leverage relevant information throughout multi-turn conversations, reflecting real-world scenarios where people often forget and revisit past exchanges. ContextDialog is constructed using MultiDialog, a spoken dialog corpus featuring conversations between two speakers, comprising approximately 340 hours of data with at least 10 turns per conversation from 12 speakers. The dataset includes a test set divided into test_freq and test_rare subsets, containing 363 and 290 dialogues, and 1,452 and 1,160 QA pairs, respectively. The datasets fields include file_id, position, query, split, question_audio, answer_audio, question_text, answer_text, and supporting_text.
提供机构:
wangyueyiiiiiii
搜集汇总
数据集介绍
构建方式
ContextDialog基准数据集基于多轮对话语料库MultiDialog构建,该语料库收录了12位说话者之间进行的自然对话,共计约340小时语音数据,且每段对话至少包含10轮交互。为了系统评估语音交互模型在复杂对话中回忆与利用上下文信息的能力,研究者从MultiDialog的测试集中筛选并精心构造了问题-答案对,其中问题均涉及对话历史中曾出现的具体内容。每个样本均标注了问题与答案的文本转录及对应音频、支持性原文、问题来源(用户或系统)以及信息在对话中的位置(前端或后端)等信息,从而构成了一个覆盖常见与罕见测试场景的综合性评测资源。
特点
该数据集最显著的特点在于其专注于评估语音交互模型的多轮对话上下文记忆与运用能力,填补了现有基准测试在这一关键维度的空白。ContextDialog包含两个子集:test_freq(363段对话、1452个问答对)和test_rare(290段对话、1160个问答对),分别对应常见与罕见上下文引用场景,从而能够细致测度模型在不同难度下的表现。所有样本均包含高质量的音频与文本对齐数据,问题与答案的时长分布合理,支持性原文的提供更使得错误分析成为可能。数据集采用CC-BY-NC-4.0许可协议,确保学术研究的合规使用。
使用方法
用户可通过HuggingFace Datasets库直接加载ContextDialog数据集,调用load_dataset('ContextDialog/ContextDialog')即可获取测试集。加载后的数据集以字典形式组织,每个样本包含file_id、position、query、split等元数据字段,以及question_audio、answer_audio这类音频特征(内含音频数组、路径与采样率)和对应的文本转录字段。例如,用户可通过索引访问样本的question_audio['array']得到问题语音数组,或读取question_text获取转录文本。该设计使得研究者能够灵活地进行基于语音或文本的模型评测,并利用supporting_text字段追溯模型回答的依据,便于深入分析模型在上下文记忆任务中的表现优劣。
背景与挑战
背景概述
上下文记忆能力是智能对话系统迈向自然交互的核心瓶颈之一。现有语音交互模型虽能处理单轮指令,却在多轮对话中频繁出现信息遗忘与上下文断裂问题。ContextDialog数据集由研究团队于2025年构建,相关论文被ACL 2025 Findings接收,旨在系统评估语音助手在多轮对话中的语境保留与利用能力。该数据集基于MultiDialog口语对话语料库,涵盖12名说话人、约340小时音频数据,每段对话至少包含10轮交互,并通过精心设计的问答对检测模型对用户及系统历史发言的回忆准确度。ContextDialog的提出为语音对话领域的上下文建模提供了标准化评估基准,推动了语音助手从短时响应向持久记忆的演进。
当前挑战
ContextDialog所解决的领域问题核心在于:多轮语音对话中,模型需克服语音表达的非结构化与信息稀疏性,跨轮次准确关联并利用历史语境。现有模型普遍缺失明确的时间戳标记与动态记忆机制,导致长程依赖下的回忆准确率骤降。构建过程中,团队面临两大挑战:其一,如何从自然口语对话中提取具有诊断价值的上下文问答对,需兼顾问题对历史信息的精准映射与语音自然度;其二,必须平衡测试样本的频次分布,通过test_freq与test_rare划分模拟信息重现的常规与稀有场景,从而全面暴露模型在多样对话结构下的记忆短板。
常用场景
经典使用场景
ContextDialog数据集专为评估语音交互模型在多轮对话中的上下文记忆与利用能力而设计。其经典使用场景聚焦于衡量模型能否从长达十轮以上的自然口语对话中精准提取历史信息,并基于用户或系统过往的陈述回答听觉查询。通过构建涉及‘频繁’与‘罕见’两种对话分割的问答对,该数据集模拟了真实交流中信息遗忘与回溯的复杂情境,为语音助手、人机对话系统等提供了严谨的基准测试框架。研究者借助该数据集可系统性地检验模型对对话历史的编码、检索与推理效能,推动语音交互模型从短时响应向长程认知能力的演进。
衍生相关工作
ContextDialog数据集已催生一系列具有启发性的衍生工作。其构建方法直接借鉴了多轮口语语料库MultiDialog,并在此基础上创新性地提出了基于‘说话者视角’(query字段区分用户与系统历史发言)的评估范式。该数据集支撑了提交至ACL 2025 Findings的里程碑式研究《Does Your Voice Assistant Remember?》,该工作系统揭示了现有语音模型在长程上下文调用中的系统性缺陷。此外,ContextDialog的评估框架已被后续多模态对话模型所采用,衍生出面向跨模态记忆检索、动态对话状态追踪等子问题的专项研究,推动了语音交互领域评价体系的标准化与深化。
数据集最近研究
最新研究方向
ContextDialog数据集聚焦于评估语音交互模型在多轮对话中的上下文记忆与利用能力,其研究前沿紧扣语音助手的长程对话理解与个性化交互需求。随着大语言模型与语音技术的深度融合,如何让模型在自然流畅的语音对话中准确追溯并引用先前的用户表述或系统回复,成为提升交互智能与用户粘性的关键热点。该数据集通过构建包含稀有与常见上下文记忆的问答对,揭示了现有模型在跨轮次信息召回与语义关联上的显著短板,为推动语音对话系统从简单响应向具有持久记忆的智能体演进提供了系统性评测基准,其影响深远,有望催生更注重对话连贯性与上下文感知的新一代语音助手架构。
以上内容由遇见数据集搜集并总结生成


