library-seating
收藏Hugging Face2024-12-19 更新2024-12-20 收录
下载链接:
https://huggingface.co/datasets/davnas/library-seating
下载链接
链接失效反馈官方服务:
资源简介:
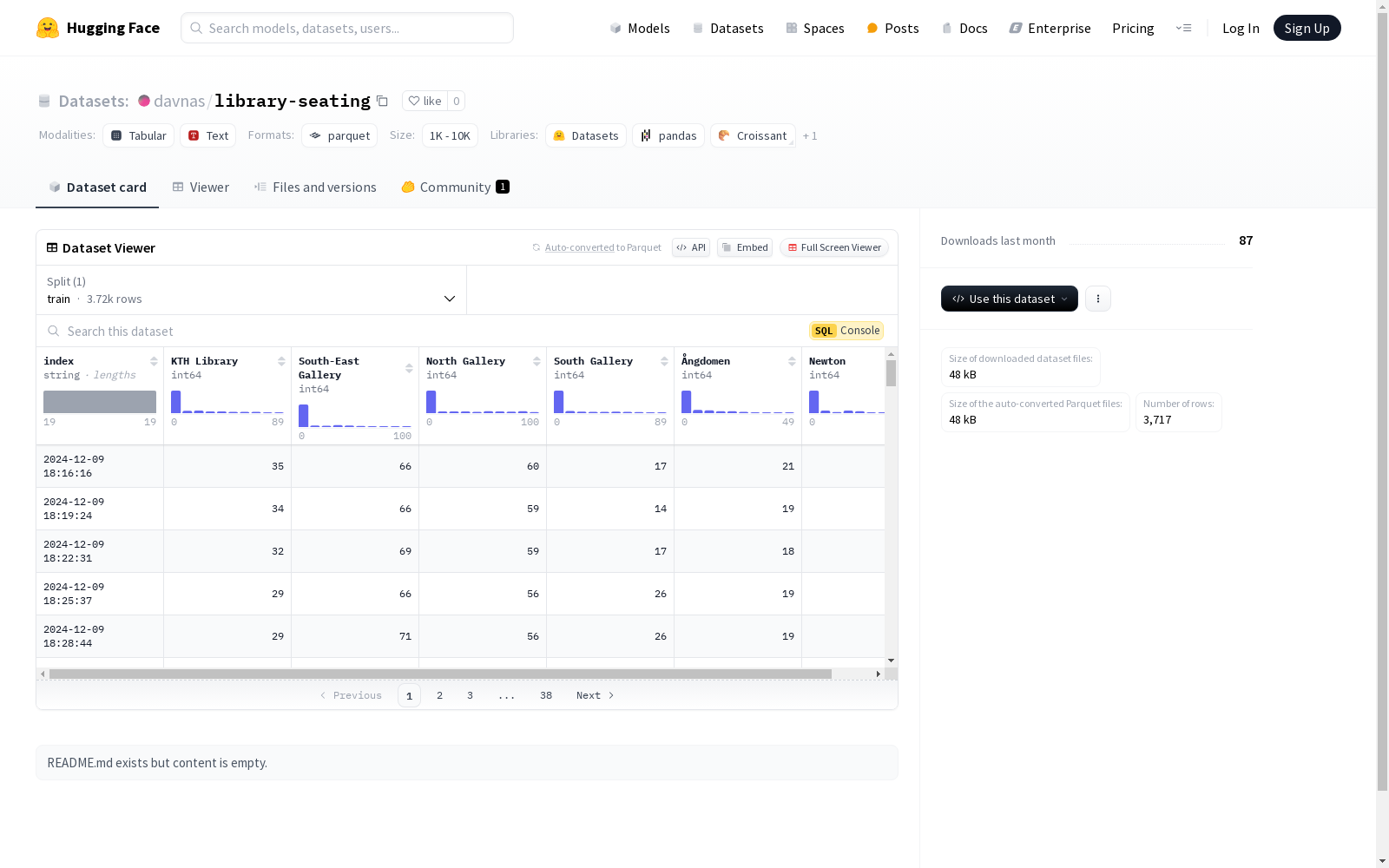
该数据集包含多个字段,如'index'、'KTH Library'、'South-East Gallery'等,分别表示不同的特征。数据集被分割为训练集,包含3557个样本,总大小为252547字节。数据集的下载大小为46420字节。
This dataset contains multiple fields, such as 'index', 'KTH Library', 'South-East Gallery', etc., which respectively represent different features. The dataset is split into the training set, which includes 3557 samples with a total size of 252547 bytes. The download size of the dataset is 46420 bytes.
创建时间:
2024-12-12
原始信息汇总
数据集概述
数据集信息
-
特征:
index: 类型为stringKTH Library: 类型为int64South-East Gallery: 类型为int64North Gallery: 类型为int64South Gallery: 类型为int64Ångdomen: 类型为int64Newton: 类型为int64
-
数据分割:
train: 包含 3707 个样本,占用 263197 字节
-
下载大小: 47954 字节
-
数据集大小: 263197 字节
配置
- 配置名称:
default- 数据文件:
train: 路径为data/train-*
- 数据文件:
搜集汇总
数据集介绍
构建方式
library-seating数据集的构建基于对图书馆内不同区域座位使用情况的详细记录。该数据集通过收集和整理图书馆内各个区域的座位占用情况,形成了包含多个特征的数据集。具体而言,数据集记录了KTH Library、South-East Gallery、North Gallery、South Gallery、Ångdomen和Newton等区域的座位占用数量,每个区域的座位占用情况以整数形式表示。数据集的构建过程确保了数据的准确性和完整性,为后续的分析和研究提供了坚实的基础。
使用方法
library-seating数据集的使用方法相对直接。研究者可以通过加载数据集的训练部分,利用其中的座位占用数据进行分析或建模。数据集的特征包括各个区域的座位占用数量,这些特征可以作为输入变量,用于预测未来的座位使用情况或分析座位使用的时空分布。此外,数据集的结构设计使得其易于与其他数据集或模型结合使用,进一步拓展其应用范围。
背景与挑战
背景概述
library-seating数据集由KTH皇家理工学院的研究团队创建,旨在研究图书馆内不同区域的座位使用情况。该数据集收集了多个图书馆区域(如KTH图书馆、东南画廊、北画廊等)的座位占用数据,时间跨度涵盖了多个工作日和时间段。通过分析这些数据,研究者能够深入理解图书馆用户的座位偏好和行为模式,从而为图书馆的空间管理和资源优化提供科学依据。该数据集的创建不仅为图书馆管理领域提供了宝贵的实证数据,也为相关领域的研究者提供了一个标准化的数据集,用以验证和开发新的座位预测和管理模型。
当前挑战
library-seating数据集在构建过程中面临多项挑战。首先,数据采集需要在图书馆的多个区域进行,确保数据的全面性和代表性,这要求研究团队具备高效的数据采集和处理能力。其次,座位占用状态的实时更新和准确记录是数据集质量的关键,任何数据丢失或错误都可能影响后续分析的准确性。此外,如何处理和分析大规模的座位使用数据,以提取有用的模式和趋势,也是该数据集面临的重要挑战。最后,数据集的隐私和伦理问题也不容忽视,确保用户隐私不被侵犯是数据集构建过程中必须严格遵守的原则。
常用场景
经典使用场景
在图书馆管理领域,library-seating数据集的经典使用场景主要集中在座位占用率的实时监控与预测。通过分析不同区域如KTH Library、South-East Gallery等的座位占用情况,该数据集能够帮助图书馆管理者优化座位分配策略,提升空间利用效率。此外,该数据集还可用于开发智能推荐系统,为读者提供即时的座位可用性信息,从而提升用户体验。
解决学术问题
library-seating数据集解决了图书馆管理中的多个学术研究问题,特别是在空间资源优化与用户行为分析方面。通过提供详细的座位占用数据,研究者可以深入探讨读者行为模式,如高峰时段的座位需求预测、不同区域的座位偏好等。这些研究不仅有助于提升图书馆的服务质量,还为相关领域的空间管理理论提供了实证支持。
实际应用
在实际应用中,library-seating数据集被广泛用于开发智能图书馆管理系统。例如,通过集成该数据集,图书馆可以实现座位的动态分配与预约功能,减少读者寻找座位的时间。此外,该数据集还可用于构建预测模型,帮助图书馆在特定时间段内提前调整座位布局,以应对突发的客流高峰,从而提升整体运营效率。
数据集最近研究
最新研究方向
在图书馆管理与用户体验优化领域,library-seating数据集的最新研究方向聚焦于通过精细化数据分析提升座位利用率与用户满意度。该数据集详细记录了不同区域如KTH Library、South-East Gallery等的座位占用情况,为研究者提供了宝贵的实证数据。当前,研究热点集中在利用机器学习算法预测座位需求高峰,优化座位分配策略,以及通过数据可视化技术提升用户导航体验。这些研究不仅有助于提高图书馆的空间管理效率,还能显著增强用户的访问体验,对现代图书馆管理实践具有深远的指导意义。
以上内容由遇见数据集搜集并总结生成


