douban_faces
收藏Hugging Face2026-05-10 更新2026-05-11 收录
下载链接:
https://huggingface.co/datasets/ayase-kakurazaka/douban_faces
下载链接
链接失效反馈官方服务:
资源简介:
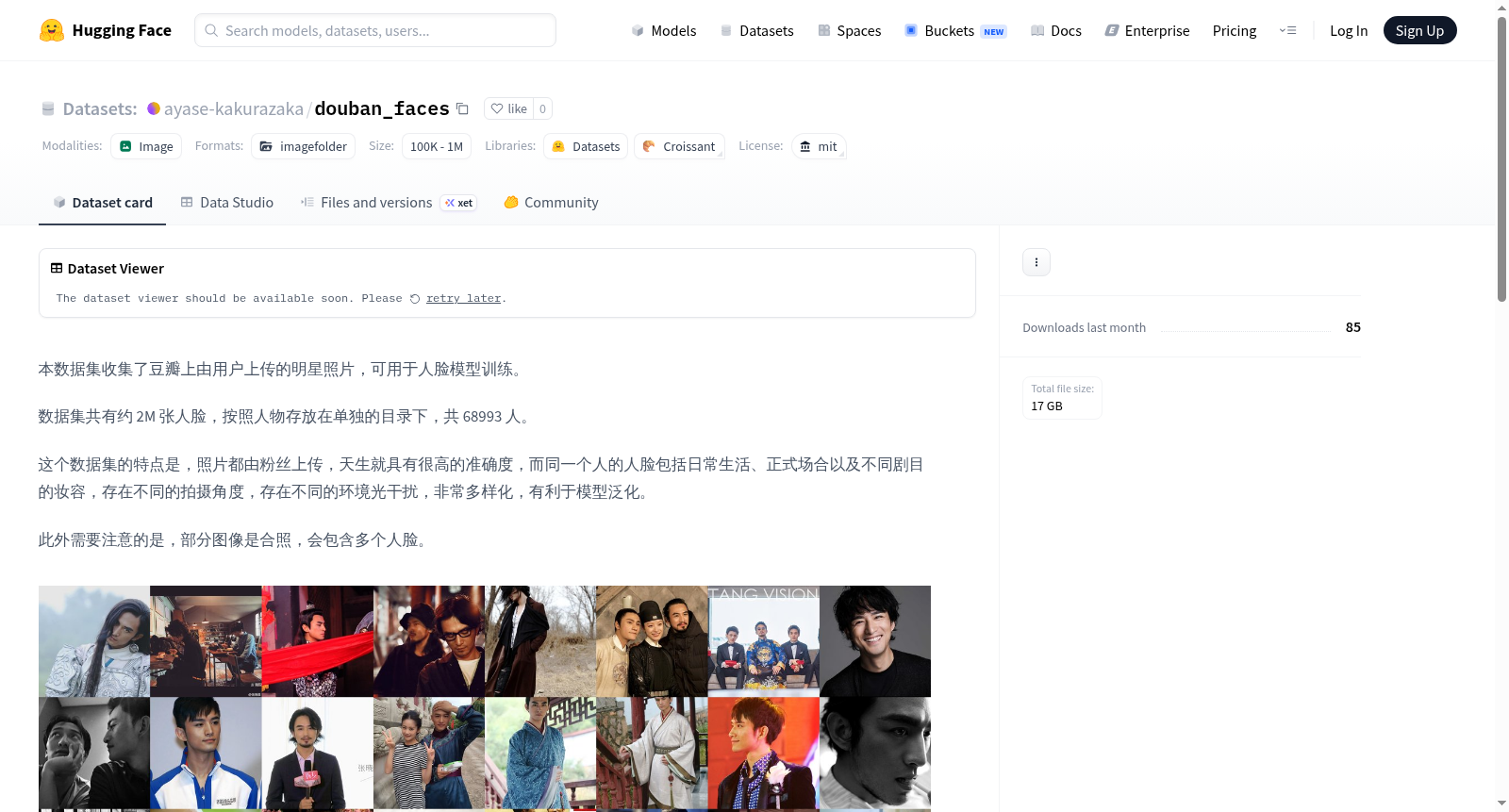
本数据集收集了豆瓣用户上传的明星照片,专为人脸模型训练而设计。数据集包含约200万张人脸图像,涵盖68,993位不同人物,每位人物的图像均存储在独立目录中。该数据集的显著特点在于所有照片均由粉丝上传,具有天然的高准确度。图像内容包含同一人物的多样化场景:日常生活照、正式场合照片以及不同影视剧中的造型,涵盖了多种拍摄角度、环境光线条件和妆容变化,这种多样性有助于提升模型的泛化能力。需要注意的是,部分图像为多人合照,可能包含多张人脸。数据集适用于人脸识别、人脸特征分析等计算机视觉任务。
This dataset collects celebrity photos uploaded by Douban users, specifically designed for face model training. It contains approximately 2 million face images, covering 68,993 different individuals, with each persons images stored in a separate directory. The notable feature of this dataset is that all photos are uploaded by fans, ensuring natural high accuracy. The image content includes diverse scenarios of the same person: daily life photos, formal occasion photos, and various looks from different film and television dramas, covering multiple shooting angles, ambient lighting conditions, and makeup changes. This diversity helps improve the generalization ability of models. It should be noted that some images are group photos and may contain multiple faces. The dataset is suitable for computer vision tasks such as face recognition and face feature analysis.
创建时间:
2026-05-09
原始信息汇总
数据集概述:douban_faces
基本信息
- 数据集名称:douban_faces
- 许可证:MIT
- 数据规模:约 200 万张人脸图片
- 人物数量:68,993 人
数据内容
- 来源:豆瓣平台上用户上传的明星照片
- 组织方式:按人物分别存放在独立的目录下
数据特点
- 高准确性:照片均由粉丝上传,天然具有较高准确度
- 高度多样化:
- 包含日常生活、正式场合、不同剧目妆容等多种场景
- 存在不同的拍摄角度
- 存在不同的环境光干扰
- 有利于提升模型泛化能力
注意事项
- 部分图像为合照,可能包含多个人脸
示例图片

搜集汇总
数据集介绍
构建方式
在互联网时代,人脸识别模型的性能高度依赖于训练数据的多样性与质量。douban_faces数据集正是基于此理念而构建,它从豆瓣平台收集了由用户上传的明星照片,旨在为面部识别任务提供丰富的训练素材。该数据集共包含约200万张人脸图像,覆盖68993个不同身份。其构建方式遵循人物维度的分类逻辑,将同一个人不同场景下的照片归入独立目录,形成结构清晰、便于索引的数据组织体系。这种收集与整理策略确保了数据集的内在一致性,同时天然地利用粉丝群体对照片准确性的自发把关,降低了人工标注的负担与误差。
特点
douban_faces数据集最显著的特点在于其数据来源的社区驱动属性,所有图像均由粉丝自愿上传,这赋予了数据集极高的标注准确性与真实性。此外,数据集展现了极佳的多样性,单人图像涵盖了日常休闲、正式场合到影视剧角色等多种妆容、服饰与拍摄角度,还包含了复杂的环境光照变化。这种丰富的变化有助于提升模型对不同领域偏移的泛化能力。值得注意的是,数据集中部分图像为合照,内含多个人脸,这虽然增加了任务复杂度,但也模拟了更贴近真实应用的多目标场景,有利于训练更鲁棒的检测与识别算法。
使用方法
针对douban_faces数据集的使用,研究者可以将其直接应用于训练端到端的人脸识别模型,或作为预训练数据进行迁移学习。由于数据已按人物名称分目录存放,用户无需额外的解析步骤即可快速按身份索引图像。在使用时需注意,对于包含多张人脸的合照,建议先采用人脸检测算法(如MTCNN或RetinaFace)进行裁剪与对齐,以确保训练数据中每张图像对应单一身份。此外,由于数据集以MIT许可证开放,其具有高度的商业与研究友好性,可直接集成到深度学习框架(如PyTorch或TensorFlow)的数据管道中进行批量加载与增强操作。
背景与挑战
背景概述
该数据集由独立研究者ayase-kakurazaka创建于2023年,旨在为中国影视明星人脸识别研究提供大规模、高多样性的训练资源。douban_faces数据集汇聚了来自豆瓣社区的约200万张明星人脸图像,涵盖68993个身份类别,每张图像均源自真实粉丝上传,确保了标注的高准确度。其核心研究价值在于,这些图像跨越了日常生活、正式场合、不同影视剧妆容等多种场景,并包含多角度与复杂光照条件,为提升人脸识别模型的泛化能力提供了天然优势。该数据集的发布填补了中文娱乐圈人脸识别领域大规模、高质量公共数据集的空白,对推动亚洲人脸识别技术发展具有重要影响力。
当前挑战
领域层面,尽管该数据集解决了传统人脸数据集在种族与场景多样性上的不足,但其面对的核心挑战在于如何有效处理旷日持久的面部特征演变、复杂多变的遮挡条件以及跨年龄识别等问题。构建过程中,首要挑战在于数据清洗与自动标注:从用户上传的海量合影中准确提取多个人脸并进行身份关联,需要高精度的检测与聚类算法,以避免噪声和错误标注。此外,合照中包含的多张面孔带来边界模糊的标签归属问题,而明星在不同妆容、发型下的巨大外观差异也对模型的特征提取能力提出了严峻考验。
常用场景
经典使用场景
在计算机视觉与人脸识别领域,douban_faces数据集凭借其高度多样化和真实场景下的明星面部图像,成为训练人脸识别与验证模型的经典资源。该数据集囊括近七万人的约两百万张面孔,覆盖日常生活、正式场合及不同剧目妆容等多维场景,同时包含丰富的拍摄角度与环境光照变化,显著提升了模型在实际应用中的鲁棒性与泛化能力。研究者常利用该数据集微调大规模预训练模型,以应对复杂姿态、遮挡及光照条件下的身份识别挑战。
衍生相关工作
源于douban_faces数据集的经典工作包括人脸聚类与去重算法、轻量化人脸识别网络,以及针对域泛化的面部表征学习研究。部分学者基于其多人物、多场景特性,开发了用于跨域人脸匹配的对抗训练框架;另一些工作则利用该数据集中包含的合照场景,深入研究了多人面部检测与分组技术。这些衍生研究不仅扩展了人脸理解的前沿边界,也为后续如情感计算、生物特征安全等交叉领域提供了高质量的数据基石与实验基准。
数据集最近研究
最新研究方向
douban_faces数据集凭借其约200万张涵盖68,993位明星的多样化人脸图像,正成为人脸识别与生成领域的前沿研究基石。这些由粉丝上传的照片天然具备高标注准确度,且囊括日常、正式场景及影视妆容下的不同角度与光照条件,极大提升了模型对真实世界复杂变异的泛化能力。当前热点方面,该数据集被用于推动对抗生成网络在人脸编辑中的鲁棒性训练,以及探索明星身份保护与深度伪造检测的技术平衡。其影响力在于,为开放环境下的细粒度人脸分析提供了高质量基准,尤其助力了低分辨率或遮挡场景下的识别性能突破,同时促进了针对伦理合规的数据集构建范式。
以上内容由遇见数据集搜集并总结生成


