MultiBLiMP 1.0
收藏arXiv2025-04-04 更新2025-04-08 收录
下载链接:
https://huggingface.co/datasets/jumelet/multiblimp
下载链接
链接失效反馈官方服务:
资源简介:
MultiBLiMP 1.0是由格罗宁根大学和德克萨斯大学奥斯汀分校的研究人员创建的一个大规模多语言语料库,包含101种语言,6种语言现象,超过125,000个最小对立体。该数据集通过利用Universal Dependencies和UniMorph的大规模语言资源,采用全自动管道创建。它不仅是一个评估基准,还是一个可以自动创建高度多语言基准的管道,可扩展到更多的句法现象。该数据集主要用于评估大型语言模型在多语言环境下的语言能力,并揭示了当前最先进技术在处理低资源语言方面的不足。
MultiBLiMP 1.0 is a large-scale multilingual corpus developed by researchers from the University of Groningen and The University of Texas at Austin, which covers 101 languages, 6 linguistic phenomena, and over 125,000 minimal pairs. This dataset was built through a fully automated pipeline that leverages large-scale linguistic resources from Universal Dependencies and UniMorph. It not only acts as an evaluation benchmark but also provides a pipeline for automatically generating highly multilingual benchmarks that can be expanded to cover more syntactic phenomena. This dataset is mainly used to assess the linguistic abilities of large language models in multilingual scenarios, and exposes the deficiencies of current state-of-the-art technologies in handling low-resource languages.
提供机构:
格罗宁根大学, 德克萨斯大学奥斯汀分校
创建时间:
2025-04-04
搜集汇总
数据集介绍
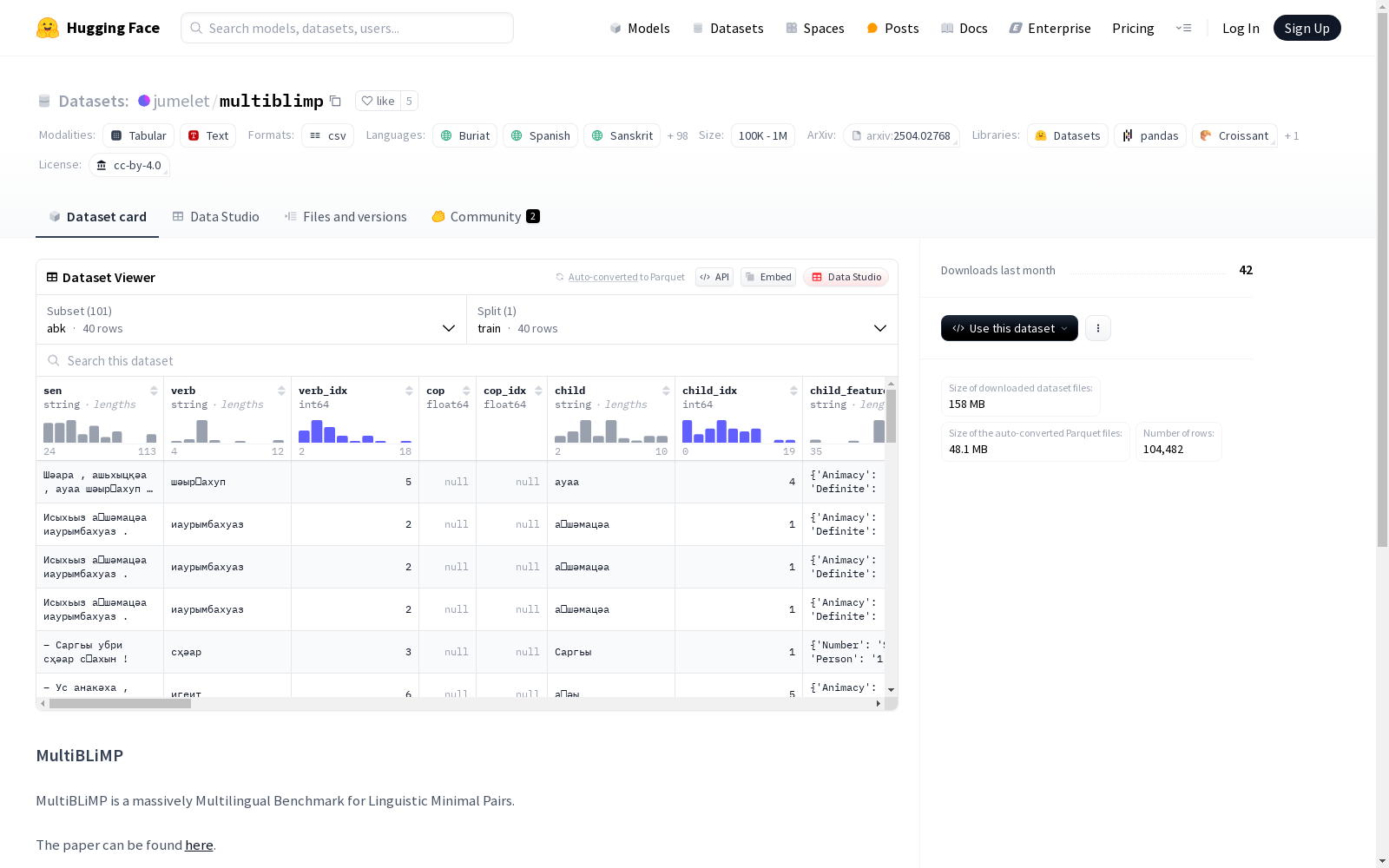
构建方式
MultiBLiMP 1.0的构建采用了全自动化的流程,充分利用了Universal Dependencies和UniMorph两大语言学资源。通过从Universal Dependencies的依存分析树中提取候选句子,并基于UniMorph进行词形变化,生成语法正确的句子及其对应的语法错误版本。这一流程确保了数据集的多样性和广泛覆盖,涵盖了101种语言和6种语言现象。
特点
MultiBLiMP 1.0的特点在于其大规模多语言覆盖和精细的语言现象标注。数据集包含超过125,000个最小对,每个对均由语法正确和错误的句子组成,差异仅在于单一语法特征。此外,数据集通过平衡不同语言和语法现象的样本,确保了评估的全面性和公正性。
使用方法
MultiBLiMP 1.0主要用于评估大型语言模型在多语言环境下的语法能力。研究人员可以通过比较模型对语法正确和错误句子的概率分配,量化模型的语法理解能力。此外,数据集还可用于跨语言语法现象的对比研究,为语言模型的改进和语言学理论研究提供数据支持。
背景与挑战
背景概述
MultiBLiMP 1.0是由荷兰格罗宁根大学和美国德克萨斯大学奥斯汀分校的研究人员Jaap Jumelet、Leonie Weissweiler和Arianna Bisazza于2025年推出的一个大规模多语言语言学最小对基准数据集。该数据集覆盖了101种语言,包含超过125,000个最小对,重点关注六种语言现象,特别是主谓一致性问题。MultiBLiMP 1.0的创建基于Universal Dependencies和UniMorph两大语言学资源,通过全自动化流程生成,旨在评估大型语言模型(LLMs)在多语言环境下的形式语言能力。该数据集的推出填补了多语言语法评估的空白,为语言模型的跨语言比较和定量类型学研究提供了统一框架。
当前挑战
MultiBLiMP 1.0面临的挑战主要包括两个方面:首先,在解决领域问题方面,该数据集旨在评估语言模型对低资源语言的语法规则掌握能力,但模型表现严重受限于训练数据中语言的频率分布,如何平衡不同语言的评估效果成为关键难题;其次,在构建过程中,研究人员需要克服多语言形态句法标注不一致、语言现象验证困难等挑战,特别是对于主谓一致等语法现象在不同语言中的表现形式差异较大,需设计语言无关的验证机制。此外,自动生成的语法错误对需确保其语言学有效性,这对低资源语言的标注质量提出了更高要求。
常用场景
经典使用场景
MultiBLiMP 1.0作为大规模多语言语言学最小对基准,其经典使用场景在于评估大型语言模型(LLMs)在101种语言中对6种语言现象的语法敏感性。通过125,000余组最小对,研究者能够系统测试模型在主语-动词一致性(如数、人称、性别)等核心语法结构上的表现。该数据集特别适用于分析模型在低资源语言中的语法能力缺陷,为跨语言语法习得研究提供了标准化框架。
实际应用
在实际应用中,MultiBLiMP 1.0被广泛用于指导多语言模型的优化方向。科技公司可依据其评估结果调整tokenizer策略以改善低资源语言处理,教育机构则利用其构建区域性语言模型的训练基准。该数据集还能辅助语言学家开展定量类型学研究,例如通过模型在不同语序语言中的一致性错误率,验证语法现象的普遍性假设。
衍生相关工作
该数据集催生了多项重要研究,包括Brinkmann等(2025)关于跨语言语法表征共享的神经机制探索,以及Wendler等(2024)对LLMs内部枢纽语言现象的发现。其方法论启发CLiMP(Xiang et al., 2021)等单语基准的构建,而Goldfish模型的对比实验则衍生出数据均衡性与模型性能的深度讨论。后续工作正扩展至非印欧语系特有的语法现象评估。
以上内容由遇见数据集搜集并总结生成


