hyeminboo/HARDBench
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/hyeminboo/HARDBench
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-sa-4.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
- split: realx
path: data/realx-*
- split: vstar
path: data/vstar-*
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
- name: image
dtype: string
- name: data_source
dtype: string
- name: is_unanswerable
dtype: bool
- name: original_question
dtype: string
- name: modifications
dtype: string
- name: pair_id
dtype: float64
splits:
- name: train
num_bytes: 3224134
num_examples: 10000
- name: validation
num_bytes: 92257
num_examples: 200
- name: test
num_bytes: 238390
num_examples: 500
- name: realx
num_bytes: 26869
num_examples: 82
- name: vstar
num_bytes: 138203
num_examples: 382
download_size: 1456890
dataset_size: 3719853
task_categories:
- visual-question-answering
- image-to-text
language:
- en
tags:
- multimodal
- refusal
- unanswerable
- visual-reasoning
- tool-use
- agent
size_categories:
- 10K<n<100K
---
# HARDBench: High-resolution, systematically Altered, Refusal-Demanding Benchmark
HARDBench is a benchmark and training dataset introduced in the paper **"Rotus: Calibrated Refusal Optimization for Multimodal Tool-Use Agents"**.
It is designed to train and evaluate **refusal calibration** in multimodal tool-use agents — specifically, whether agents can appropriately abstain from answering when visual evidence is insufficient, rather than generating overconfident or hallucinated responses.
📄 Paper (coming soon) | 💻 [GitHub](https://github.com/ewha-mmai/rotus)
---
## Overview
State-of-the-art multimodal agents finetuned with reinforcement learning often lose the ability to refuse unanswerable questions — even when their own tool outputs fail to provide sufficient evidence. HARDBench addresses this gap by providing systematically constructed unanswerable questions paired with real, high-complexity visual scenarios.
Unlike prior benchmarks that rely on artificially manipulated images or narrow visual domains, HARDBench generates unanswerability by modifying **semantic components** of real questions — specifically **Objects, Relations, and Attributes (ORA)** — through a structured three-step pipeline.
---
## Dataset Splits and Composition
| Split | Source | # Samples |
|-------|--------|-----------|
| Train | PixMo Counting, TallyQA, ArxivQA, MM-adaptive-CoF RL | 10,000 |
| Test (In-domain) | PixMo Counting, TallyQA, ArxivQA, MM-adaptive-CoF RL | 500 |
| Test (HARDBench-RealX) | RealX-Bench | 82 |
| Test (HARDBench-V*) | V*Bench | 382 |
- Training set maintains a **3:1 ratio** of answerable to unanswerable questions.
- Test sets contain equal distributions of answerable and unanswerable questions.
---
## Data Sources & Licenses
HARDBench questions reference images from the following source datasets.
Images must be downloaded separately:
| Dataset | Link | License |
|---------|------|---------|
| ArxivQA | [MMInstruction/ArxivQA](https://huggingface.co/datasets/MMInstruction/ArxivQA) | CC-BY-SA-4.0 |
| MM-adaptive-CoF RL | [xintongzhang/CoF-RL-Data](https://huggingface.co/datasets/xintongzhang/CoF-RL-Data) | SA-1B Dataset Research License |
| PixMo-Count | [allenai/pixmo-count](https://huggingface.co/datasets/allenai/pixmo-count) | ODC-BY-1.0 |
| TallyQA | [tallyqa.zip](https://github.com/manoja328/tallyqa) | Apache License 2.0 |
| RealXBench | [glowol/RealXBench](https://huggingface.co/datasets/glowol/RealXBench) | Apache License 2.0 |
| V*Bench | [craigwu/vstar_bench](https://huggingface.co/datasets/craigwu/vstar_bench) | SA-1B Dataset Research License |
---
## Citation
```bibtex
coming soon
```
提供机构:
hyeminboo
搜集汇总
数据集介绍
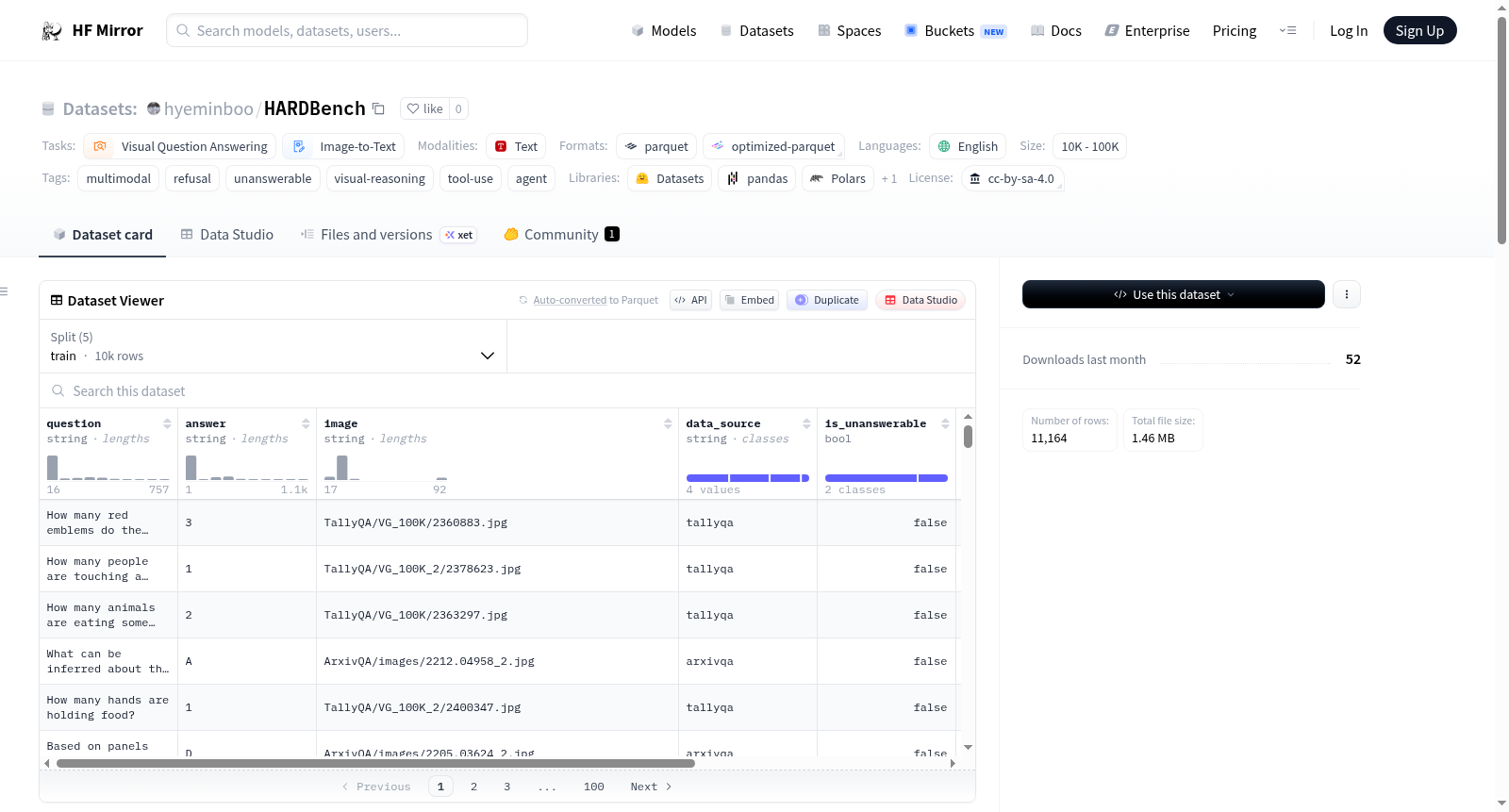
构建方式
在视觉问答领域,HARDBench的构建遵循一套严谨的三步流程。该数据集从PixMo Counting、TallyQA、ArxivQA及MM-adaptive-CoF RL等多个高质量视觉数据源中选取真实、高复杂度的视觉场景作为基础。其核心创新在于通过系统性地修改原始问题中的语义成分——即对象、关系和属性,从而生成一系列无法仅凭给定图像信息回答的问题。训练集精心维持了可回答问题与不可回答问题之间三比一的比例,确保了模型在学习拒绝与回答之间取得平衡。
特点
HARDBench的显著特征在于其专注于评估多模态工具使用代理的拒绝校准能力。与以往依赖人工合成图像或狭窄视觉领域的基准不同,该数据集通过语义层面的系统性修改来创造不可回答性,从而更贴近真实世界的复杂性。数据集提供了多个精心划分的测试子集,包括用于域内评估的标准测试集,以及源自RealX-Bench和V*Bench的外部测试集HARDBench-RealX与HARDBench-V*,旨在全面检验模型的泛化与鲁棒性。
使用方法
使用HARDBench时,研究者需首先从其列出的各个源数据集分别下载对应的图像文件。数据集本身以标准化的分割形式提供,包含训练集、验证集和多个测试集。用户可加载这些分割,利用其中的问题、答案、图像路径及不可回答性标签等特征,对多模态代理模型进行微调或评估。其核心应用场景是训练模型在面对视觉证据不足时,能够恰当地拒绝回答,而非产生过度自信或幻觉式的响应,从而提升模型的安全性与可靠性。
背景与挑战
背景概述
在人工智能多模态交互领域,视觉问答系统的可靠性评估面临关键瓶颈,即模型在面对证据不足的视觉场景时,往往倾向于生成过度自信或虚构的答案。为应对这一挑战,HARDBench数据集应运而生,其作为《Rotus: Calibrated Refusal Optimization for Multimodal Tool-Use Agents》论文的核心贡献,由研究团队系统构建,旨在专门训练和评估多模态工具使用代理的拒绝校准能力。该数据集通过整合PixMo Counting、TallyQA、ArxivQA及MM-adaptive-CoF RL等多个高质量视觉数据源,并采用基于对象、关系和属性的语义修改策略,创造性地生成了大量不可回答的问题对,从而填补了现有基准在真实复杂视觉场景下系统性评估模型拒绝行为方面的空白,对推动多模态代理的稳健性与可信赖性研究具有重要影响。
当前挑战
HARDBench数据集致力于解决多模态视觉问答中模型拒绝校准的核心问题,其挑战首先体现在领域层面:如何确保代理在视觉证据不充分时能准确识别并拒绝回答,而非产生幻觉响应,这要求模型具备深层次的语义理解与逻辑推理能力。在构建过程中,数据集面临多重技术挑战,包括从异构数据源中协调图像与问题的语义一致性,通过结构化三步骤流程系统性地修改原始问题以生成不可回答样本,同时维持训练集中可回答与不可回答问题之间3:1的平衡比例,以及确保测试集在真实场景与合成数据上均具有广泛的覆盖性和评估效力。
常用场景
经典使用场景
在视觉问答领域,HARDBench数据集被广泛应用于训练和评估多模态工具使用代理的拒绝校准能力。该数据集通过系统性地构建不可回答的问题,结合真实高复杂度的视觉场景,为研究者提供了一个标准化的测试平台。其经典使用场景在于模拟现实世界中代理面对视觉证据不足时的决策过程,从而优化代理在不确定情境下的响应策略,避免产生过度自信或幻觉性答案。
衍生相关工作
HARDBench数据集衍生了多项经典研究工作,特别是在多模态拒绝校准领域。基于该数据集,研究者开发了如Rotus等校准拒绝优化框架,进一步探索了代理在工具使用中的置信度管理。相关工作还扩展到了视觉语言模型的可靠性评估,促进了如RealXBench和V*Bench等基准的集成应用,为多模态代理的拒绝行为建模提供了新的方法论和评估标准。
数据集最近研究
最新研究方向
在视觉问答与多模态工具使用代理领域,HARDBench数据集聚焦于拒绝校准的前沿探索。该数据集通过系统性地修改真实高复杂度视觉场景中问题的语义成分,构建了不可回答的样本对,旨在训练和评估代理在视觉证据不足时恰当拒绝回答的能力,而非产生过度自信或幻觉响应。这一研究方向紧密关联当前多模态大模型在安全性与可靠性方面的热点议题,其构建方法超越了依赖人工操纵图像的传统基准,为代理的拒绝行为提供了更贴近真实场景的校准框架,对推动负责任人工智能发展具有重要影响。
以上内容由遇见数据集搜集并总结生成


