taln-ls2n/inspec
收藏Hugging Face2022-07-21 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/taln-ls2n/inspec
下载链接
链接失效反馈官方服务:
资源简介:
Inspec是一个用于基准测试关键词提取和生成模型的数据集。该数据集包含2000篇从Inspec数据库中收集的科学论文摘要,关键词由专业索引员在不受控环境中标注。数据集分为训练、验证和测试三个部分,并提供了每个部分的文档数量、单词数量、关键词数量及其分类统计。数据集的文本预处理使用了spacy和nltk工具,关键词分类采用了PRMU方案。
Inspec is a dataset for benchmarking keyword extraction and generation models. This dataset contains 2000 scientific paper abstracts collected from the Inspec database, with keywords annotated by professional indexers in an unconstrained environment. The dataset is split into three subsets: training, validation, and test, and provides the counts of documents, words, and keywords, as well as their categorical statistics for each subset. The text preprocessing of the dataset uses spaCy and NLTK tools, and the PRMU scheme is employed for keyword classification.
提供机构:
taln-ls2n
原始信息汇总
Inspec Benchmark Dataset for Keyphrase Generation
概述
Inspec是一个用于基准测试关键短语提取和生成模型的数据集。该数据集包含2,000篇科学论文的摘要,来自Inspec数据库。关键短语由专业索引员在非受控环境中标注,不限于主题词表条目。
内容和统计
数据集分为三个部分:
| Split | # documents | #words | # keyphrases | % Present | % Reordered | % Mixed | % Unseen |
|---|---|---|---|---|---|---|---|
| Train | 1,000 | 141.7 | 9.79 | 78.00 | 9.85 | 6.22 | 5.93 |
| Validation | 500 | 132.2 | 9.15 | 77.96 | 9.82 | 6.75 | 5.47 |
| Test | 500 | 134.8 | 9.83 | 78.70 | 9.92 | 6.48 | 4.91 |
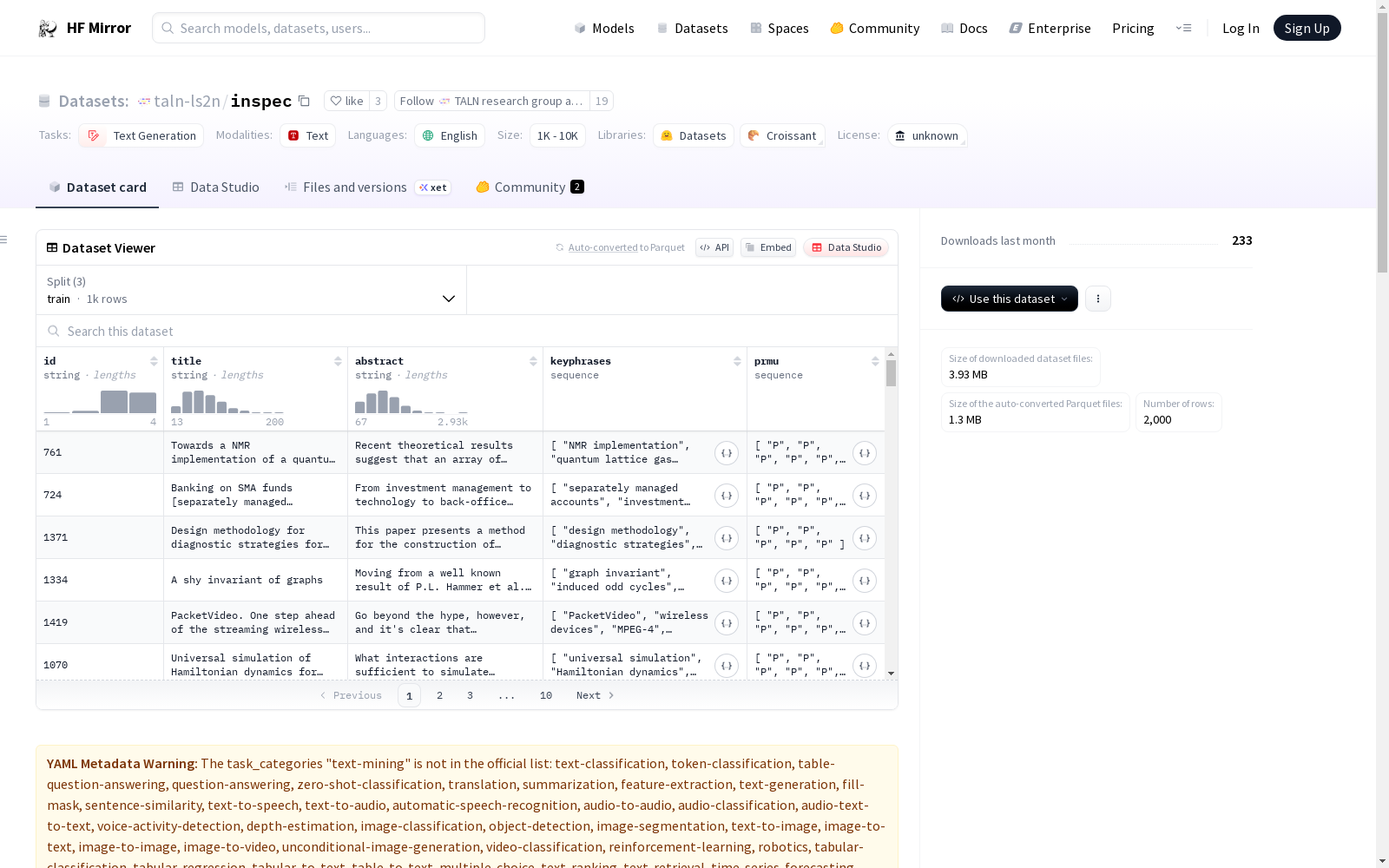
数据集包含以下字段:
- id: 文档的唯一标识符。
- title: 文档标题。
- abstract: 文档摘要。
- keyphrases: 参考关键短语列表。
- prmu: 参考关键短语的<u>P</u>resent-<u>R</u>eordered-<u>M</u>ixed-<u>U</u>nseen类别列表。
参考文献
- Hulth, A. (2003). Improved automatic keyword extraction given more linguistic knowledge. In Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing, pages 216-223.
- Boudin, F., & Gallina, Y. (2021). Redefining Absent Keyphrases and their Effect on Retrieval Effectiveness. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4185–4193, Online. Association for Computational Linguistics.
搜集汇总
数据集介绍
构建方式
Inspec数据集的构建,以科学论文摘要为基石,精选自Inspec数据库中的2000篇摘要。构建过程中,依托专业索引员在不受控的环境中标注关键词,确保了标注的多样性和真实性。文本预处理采用`spacy`模型进行分词,并特别制定规则以避免拆分带有连字符的单词。在匹配参考关键词前,使用Porter词干提取算法对文本进行词干提取,以优化匹配精度。
特点
Inspec数据集的特点在于其专注于关键短语提取和生成模型的基准测试。数据集涵盖了单语种英文文本,并按照PRMU分类方案对参考关键词进行分类,为评估模型在不同类型关键词上的表现提供了可能。此外,数据集分为训练集、验证集和测试集,各部分统计数据详尽,包括文档数量、单词数、关键词数及其分布比例,为研究者提供了丰富的实验材料。
使用方法
使用Inspec数据集,研究者可以便捷地加载包含文档唯一标识符、标题、摘要、参考关键词及其PRMU分类的字段。这些数据字段为关键短语提取和生成任务提供了必要的输入,用户可通过对应的数据处理脚本进行加载和预处理,进而用于模型训练、验证和测试。数据集的使用不仅有助于模型的评估,也便于不同研究之间的比较和复现。
背景与挑战
背景概述
Inspec数据集,作为文本挖掘领域的一项重要资源,专为关键短语提取与生成模型的基准测试而构建。该数据集的创建可追溯至2003年,由Anette Hulth在其研究中提出,收集了2000篇科学论文的摘要,源自Inspec数据库。Inspec数据集的构建旨在提升自动关键词提取的准确性,通过引入更多的语言学知识。此数据集在学术界产生了广泛影响,为关键短语提取领域的研究提供了宝贵的实验基础。
当前挑战
Inspec数据集在构建和应用过程中面临的挑战主要包括:首先,数据集的构建依赖于专业索引人员的标注,这种无控制环境的标注可能引入主观偏差;其次,数据集中的关键短语分布不均,存在一定比例的未出现(Absent)关键短语,这对于模型的泛化能力提出了挑战;再者,数据集的预处理和匹配过程中,如词语的断词和词干提取等步骤,可能影响关键短语的识别效果。这些挑战对于提升关键短语提取模型的性能和鲁棒性具有重要意义。
常用场景
经典使用场景
在文本挖掘领域,Inspec数据集被广泛用于评估关键短语提取与生成模型的性能。该数据集包含2000篇科学论文摘要,其关键短语由专业索引人员在非受控环境下标注,为研究者提供了一个理想的实验平台,以测试和改进他们的算法模型。
衍生相关工作
基于Inspec数据集,研究者们已经衍生出了一系列相关工作,如关键短语的自动生成、文本分类和情感分析等。这些研究进一步拓展了Inspec数据集的应用范围,并在自然语言处理领域产生了深远的影响。
数据集最近研究
最新研究方向
在文本挖掘领域,关键词提取与生成为研究者们所关注。taln-ls2n/inspec数据集作为评价关键词提取与生成模型性能的基准数据集,汇集了2000篇科学论文摘要。近期研究聚焦于该数据集在关键词标注质量、模型泛化能力以及标注体系对模型性能的影响等方面。Boudin和Gallina在2021年的工作中对缺失关键词进行了重新定义,并探讨了其对检索效果的影响,为关键词研究提供了新的视角。该数据集的研究不仅推动了文本挖掘技术的进步,也对科学文献的快速检索与理解具有重要意义。
以上内容由遇见数据集搜集并总结生成


