jewish-museum-and-tolerance-center_collection
收藏Hugging Face2025-12-22 更新2025-12-23 收录
下载链接:
https://huggingface.co/datasets/kulyatinakatya/jewish-museum-and-tolerance-center_collection
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是通过解析犹太博物馆和宽容中心的官方网站形成的。数据集包含了来自'收藏'部分的物品描述。为了方便分析,数据被分为单独的字段,对应于网站上的标题(或HTML标记中的标签名称)。数据以表格形式呈现。数据集可用于研究犹太历史,或作为插图材料(例如,用于创建交互式时间线)。数据集包括一个CSV文件(包含文物及其描述)、一个用于获取数据的Python代码文件以及README文件。CSV文件中的列包括:'链接'(物品标识符)、'名称'(物品名称)、'类型'(物品类型,如文件和照片、生活用品、绘画等)、'描述'(物品描述)、'起源地'(物品的地理起源信息)、'日期'(物品创建日期)、'材料'(物品材料)、'技术'(制作技术)、'主题'(物品所属的主题组)、'作者'(作者)和'时期'(物品创建时期)。
创建时间:
2025-12-12
原始信息汇总
数据集概述
基本信息
- 数据集名称: Коллекция Еврейского музея
- 作者: E.O.Кулятина
- 创建目的: 作为俄罗斯高等经济大学学生Кулятиной Екатерины的课程作业。
- 学科领域: Digital Humanities(数字人文)
- 许可证: mit
- 语言: 俄语 (ru)
数据来源与构成
- 数据来源: 通过解析“犹太博物馆和宽容中心”官方网站的“馆藏”栏目获取。
- 数据格式: 表格形式。
- 数据集文件:
jewish-museum-and-tolerance-center_collection.csv— 包含文物及其描述的列表。code-for-pasing.py— 用于获取数据的Python代码。README.md— 说明文件。
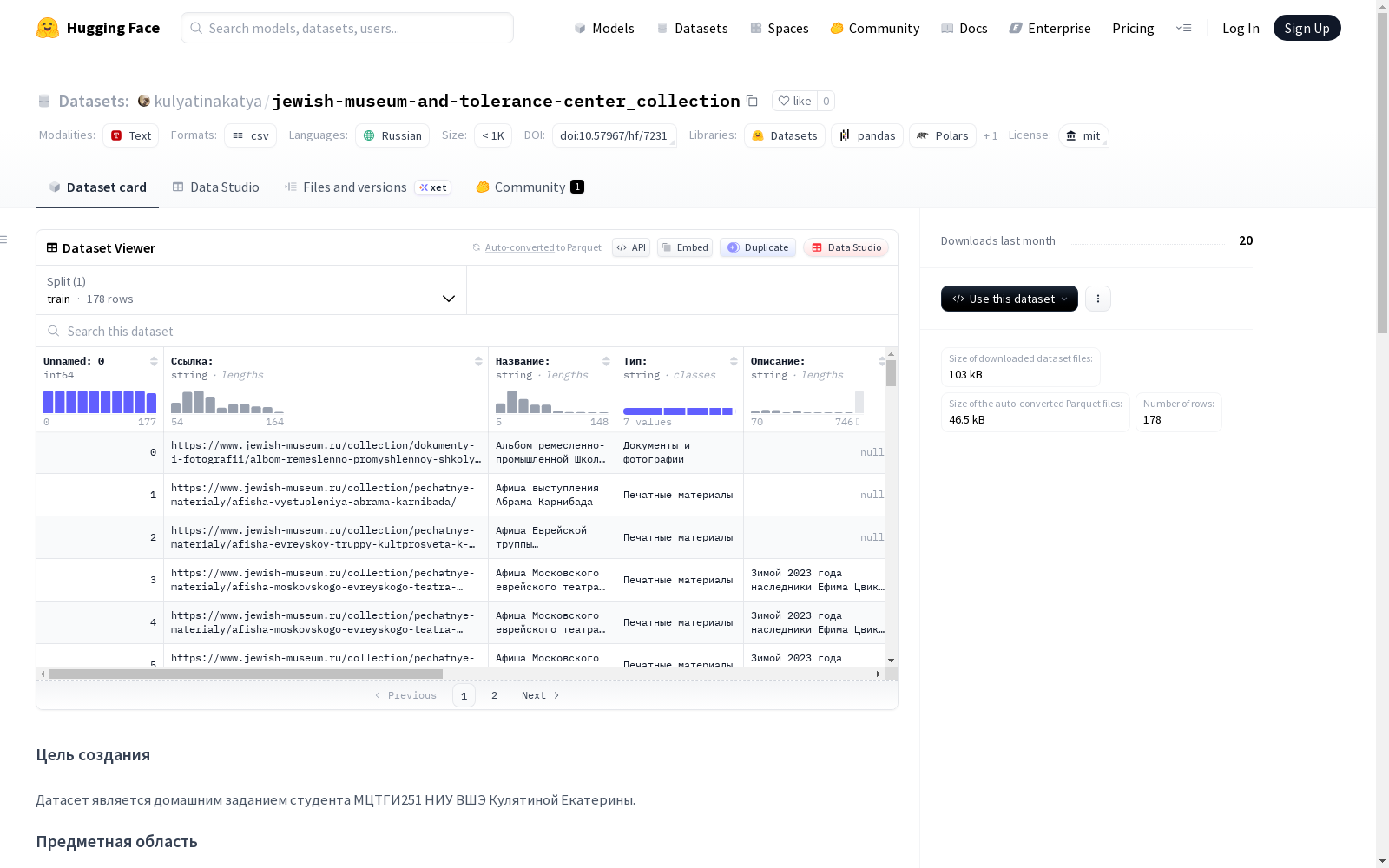
数据结构 (jewish-museum-and-tolerance-center_collection.csv)
数据字段对应于网站标题或HTML标签,具体列如下:
Ссылка— 物品标识符。Название— 物品名称。Тип— 物品类型(如:文档和照片、生活用品、绘画),对应网站收藏搜索过滤器。Описание— 物品描述。Место происхождения— 物品的地理来源信息。Дата— 物品的创作日期。Материал— 物品材质。Техника— 物品的制作工艺。Темы— 物品所属的主题类别(用于高级搜索)。Автор— 作者。Период— 物品的创作时期。
潜在用途
- 可用于犹太历史研究。
- 可作为插图材料,例如用于创建交互式时间线。
版本历史
- V1 (2025年12月12日): 首次发布。
- V2 (2025年12月22日): 第二版(预计为最终版),添加了网站在过去10天内上传的新文物。
相关资源
- 所有源文件和用于构建数据集的代码位于:https://huggingface.co/datasets/kulyatinakatya/jewish-museum-and-tolerance-center_collection
搜集汇总
数据集介绍
构建方式
在数字人文领域,数据集的构建往往依赖于对文化遗产资源的系统化整理。本数据集通过解析犹太博物馆与宽容中心官方网站的“收藏”栏目,自动化提取了各类文物的详细信息。采用Python编写的爬虫脚本,从网页的HTML标记中精准捕获了包括标题、描述、材质、年代等关键字段,并将其结构化为表格形式,确保了数据的完整性与可分析性。
特点
该数据集涵盖了犹太博物馆收藏的多样文物,如文献、摄影、生活用品及绘画等,每件物品均附有详尽的元数据,包括创作时间、地理来源、材质技术和主题分类。这些结构化字段不仅支持多维度的学术查询,也为可视化时间线或交互式探索提供了丰富素材,凸显了其在文化历史研究中的实用价值。
使用方法
研究者可直接加载CSV文件,利用其清晰的列结构进行数据挖掘或统计分析,例如按时期、类型或主题筛选文物。附带的Python解析代码允许用户复现或扩展数据收集过程。数据集适用于犹太历史、艺术史或数字人文项目,作为基础资料库或教学案例,促进文化遗产的数字化研究。
背景与挑战
背景概述
在数字人文领域,文化遗产的数字化与结构化是连接历史研究与现代技术的关键桥梁。jewish-museum-and-tolerance-center_collection数据集由俄罗斯高等经济大学学生E.O.Кулятина于2025年12月创建,作为一项学术项目。该数据集通过解析犹太博物馆与宽容中心的官方网站,系统性地收录了馆藏物品的描述信息,涵盖文档、照片、生活用品及绘画等多种类型。其核心研究问题在于如何将非结构化的博物馆藏品信息转化为可供计算分析的结构化数据,从而为犹太历史、文化研究以及互动时间线等可视化应用提供基础资源。这一工作体现了数字人文项目中数据采集与整理的初步实践,对推动文化遗产的开放获取与跨学科研究具有示范意义。
当前挑战
该数据集旨在解决数字人文领域内文化遗产数据的标准化与可计算化问题,其核心挑战在于如何从异构的网页内容中准确提取并规范化描述信息,以支持后续的学术分析与应用。在构建过程中,面临多重具体困难:首先,网站HTML结构的动态性与非一致性可能导致数据解析的完整性与准确性受损;其次,藏品描述中的多语言元素、历史日期格式的多样性以及缺失字段的处理,均对数据清洗与归一化提出较高要求;此外,确保数据在伦理与版权框架下的合规使用,亦是文化遗产数据集构建中不可忽视的挑战。这些因素共同制约了数据集在更广泛研究场景中的直接适用性与深度挖掘潜力。
常用场景
经典使用场景
在数字人文研究领域,该数据集为学者提供了系统化的犹太历史与文化物质遗产数据。研究者可借助其结构化字段,如物品类型、描述、日期与主题,深入探索犹太社群的艺术创作、日常生活及历史变迁。通过分析物品的材质、技术与地理分布,能够揭示特定时期的社会经济状况与文化互动模式,为跨学科的历史研究奠定数据基础。
实际应用
在实际应用中,该数据集可作为教育资源,用于开发博物馆的在线展览或教育课程,增强公众对犹太历史的理解。同时,文化遗产机构可借鉴其数据模型,优化自身藏品的数字化编目流程。此外,数据支持创意产业制作基于史实的多媒体内容,如纪录片或互动应用程序,促进文化记忆的当代传播。
衍生相关工作
围绕该数据集,已衍生出多项经典工作,包括利用其字段结构开发自动分类模型,以识别物品的历史时期或主题类别。亦有研究基于地理与时间数据,构建犹太文化物品的时空分布图谱,分析移民与贸易路线。这些工作不仅拓展了数字人文的技术边界,也为跨文化比较研究提供了新的方法论启示。
以上内容由遇见数据集搜集并总结生成


