挑战性相似主题数据集
收藏arXiv2024-11-27 更新2024-11-29 收录
下载链接:
https://github.com/wtybest/EnMMDiT
下载链接
链接失效反馈官方服务:
资源简介:
本文未提及具体的数据集名称、创建机构、数据集大小、数据量、Tokens数、数据来源、创建过程和应用领域。因此,无法提供详细的数据集描述。
This paper does not mention the specific dataset name, creating institution, dataset size, data volume, number of Tokens, data source, creation process, and application fields. Therefore, a detailed dataset description cannot be provided.
提供机构:
南洋理工大学
创建时间:
2024-11-27
搜集汇总
数据集介绍
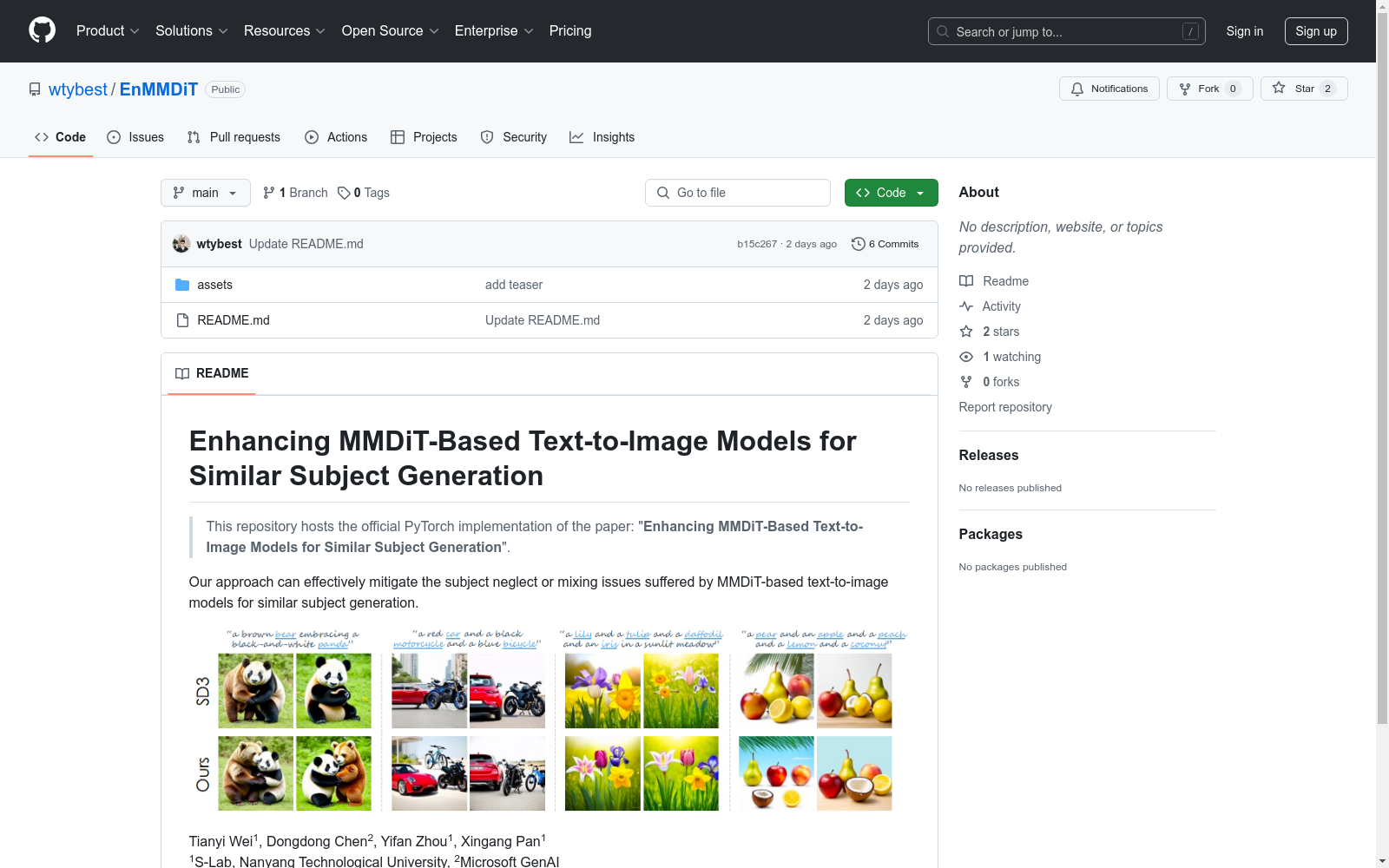
构建方式
挑战性相似主题数据集的构建旨在评估多模态扩散变换器(MMDiT)模型在处理相似主题生成任务时的性能。该数据集由涵盖动物、植物、水果、车辆等多个类别的相似主题文本描述组成,包括两、三和四个相似主题的提示。通过ChatGPT生成的30个提示,每个类别分别生成30个提示,总计90个提示。这些提示旨在测试模型在处理相似主题时的生成能力和准确性。
特点
挑战性相似主题数据集的主要特点在于其高度相似的主题设计,这使得模型在生成过程中容易出现主题混淆或忽视的问题。数据集涵盖了多种类别的相似主题,包括动物、植物、水果和车辆等,确保了测试的全面性和多样性。此外,数据集的构建方式确保了每个提示的复杂性和挑战性,从而能够有效评估模型在处理复杂文本生成任务时的性能。
使用方法
挑战性相似主题数据集主要用于评估和改进基于MMDiT的文本到图像生成模型。研究人员可以通过该数据集测试模型在处理相似主题生成任务时的表现,识别并解决模型在生成过程中可能出现的主题混淆或忽视问题。此外,该数据集还可用于训练和验证新的模型改进算法,以提高模型在处理复杂文本生成任务时的准确性和多样性。
背景与挑战
背景概述
近年来,文本到图像生成模型取得了显著进展,其中多模态扩散变换器(MMDiT)作为最新的技术代表,极大地缓解了先前模型中存在的生成问题。然而,当输入文本提示包含多个语义或外观相似的主体时,MMDiT模型仍面临主体忽视或混合的问题。为了解决这一问题,南洋理工大学的S-Lab和微软GenAI的研究团队提出了一种新的方法,通过在早期去噪步骤中进行测试时优化,动态修复潜在的模糊性。该研究不仅揭示了MMDiT架构中存在的三种可能的模糊性,还设计了三种损失函数来针对性解决这些问题,从而显著提高了生成质量和高成功率。
当前挑战
构建挑战性相似主题数据集的主要挑战在于处理输入文本中多个语义或外观相似主体的生成问题。具体挑战包括:1) 在生成过程中,MMDiT模型在早期去噪步骤中难以准确识别和区分相似主体,导致主体忽视或混合;2) 文本编码器之间的不一致性,使得生成的图像与输入文本的语义对齐存在偏差;3) 相似主体本身的语义模糊性,使得模型在早期阶段难以清晰区分这些主体。此外,构建过程中还需克服数据集多样性和复杂性的问题,确保数据集能够有效验证和提升模型的生成能力。
常用场景
经典使用场景
挑战性相似主题数据集在文本到图像生成模型中被广泛用于评估和改进模型处理相似主题的能力。该数据集通过包含多个相似语义或外观的主题,如'一朵百合、郁金香、水仙和鸢尾花在阳光下的草地上',来测试模型在生成过程中避免主题混淆或忽视的能力。这种经典使用场景帮助研究者识别和解决模型在处理复杂文本提示时的局限性,从而提升生成图像的质量和准确性。
解决学术问题
挑战性相似主题数据集解决了文本到图像生成模型在处理相似主题时常见的主题忽视或混淆问题。通过提供包含多个相似主题的文本提示,该数据集帮助研究者识别模型内部的模糊性问题,如块间模糊性、文本编码器模糊性和语义模糊性。这些问题的解决不仅提升了模型的生成质量,还为相关生成和编辑工作提供了新的研究方向和方法。
衍生相关工作
挑战性相似主题数据集的提出激发了一系列相关研究工作,特别是在文本到图像生成模型的改进和优化方面。例如,一些研究通过引入新的损失函数,如块对齐损失、文本编码器对齐损失和重叠损失,来解决模型在生成相似主题时的模糊性问题。此外,还有研究提出了在线重叠检测和返回起点采样策略,以进一步提高生成图像的质量和成功率。这些衍生工作不仅提升了模型的性能,还为未来的研究提供了新的思路和方法。
以上内容由遇见数据集搜集并总结生成


