speech31/commonvoice_tamil_ipa
收藏Hugging Face2024-02-21 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/speech31/commonvoice_tamil_ipa
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: path
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 48000
- name: sentence
dtype: string
- name: phonetic_codes
dtype: string
- name: ipa
dtype: string
splits:
- name: train
num_bytes: 1580430907.016
num_examples: 44839
- name: validation
num_bytes: 374494166.834
num_examples: 12049
- name: test
num_bytes: 478122660.264
num_examples: 12114
download_size: 2619234407
dataset_size: 2433047734.114
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
提供机构:
speech31
原始信息汇总
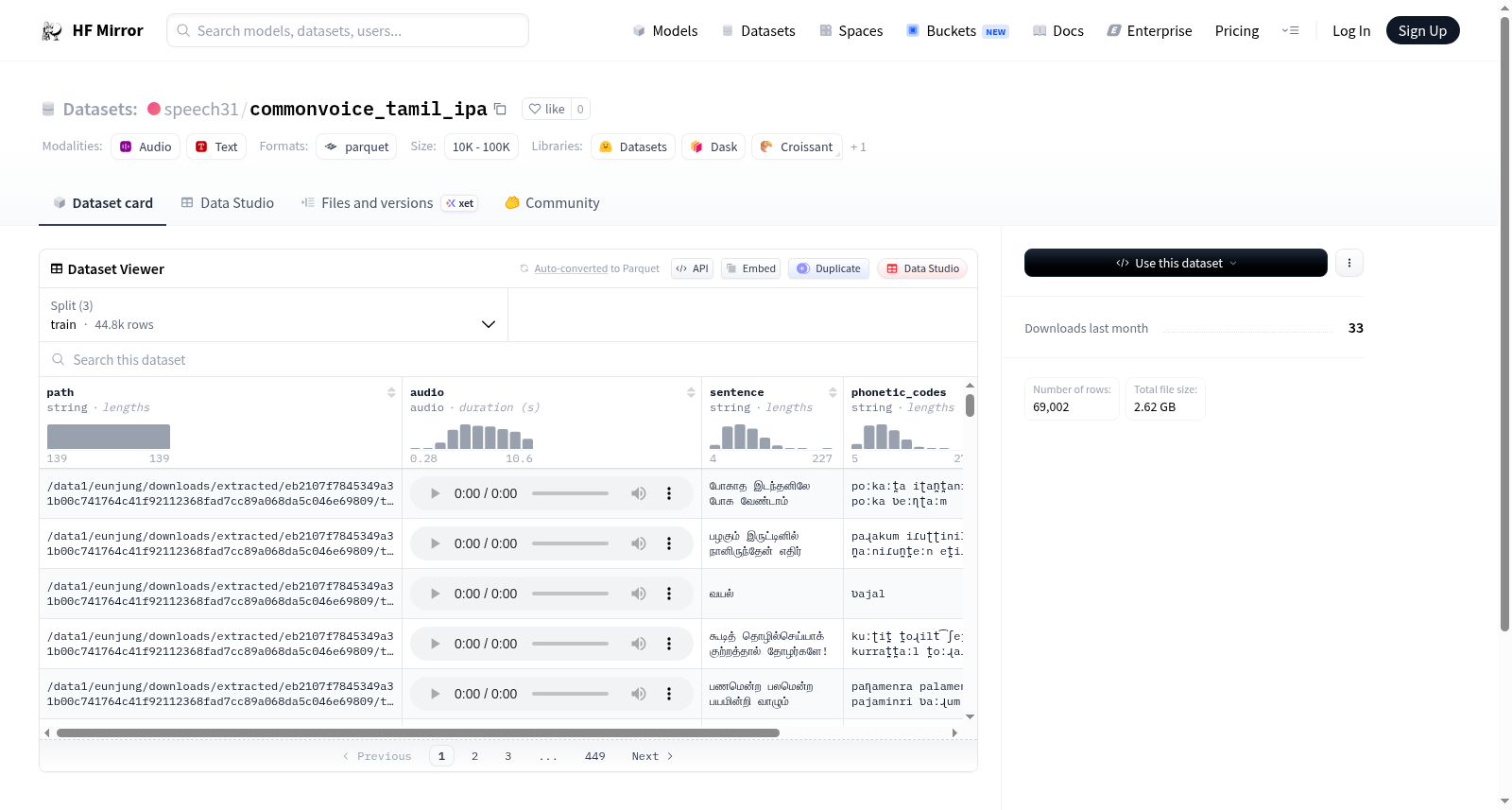
数据集概述
数据集特征
- path: 数据类型为字符串。
- audio: 数据类型为音频,采样率为48000。
- sentence: 数据类型为字符串。
- phonetic_codes: 数据类型为字符串。
- ipa: 数据类型为字符串。
数据集分割
- train: 包含44839个样本,大小为1580430907.016字节。
- validation: 包含12049个样本,大小为374494166.834字节。
- test: 包含12114个样本,大小为478122660.264字节。
数据集大小
- 下载大小: 2619234407字节。
- 数据集大小: 2433047734.114字节。
配置
- config_name: default
- data_files:
- train: 路径为
data/train-* - validation: 路径为
data/validation-* - test: 路径为
data/test-*
- train: 路径为
- data_files:
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个泰米尔语语音数据集,包含约69k条音频和对应的文本及音标转写,适用于语音识别和语音合成研究。数据已分为训练、验证和测试集,便于模型开发和评估。
以上内容由遇见数据集搜集并总结生成


