qasper-yesno
收藏Hugging Face2025-05-29 更新2025-05-30 收录
下载链接:
https://huggingface.co/datasets/allenai/qasper-yesno
下载链接
链接失效反馈官方服务:
资源简介:
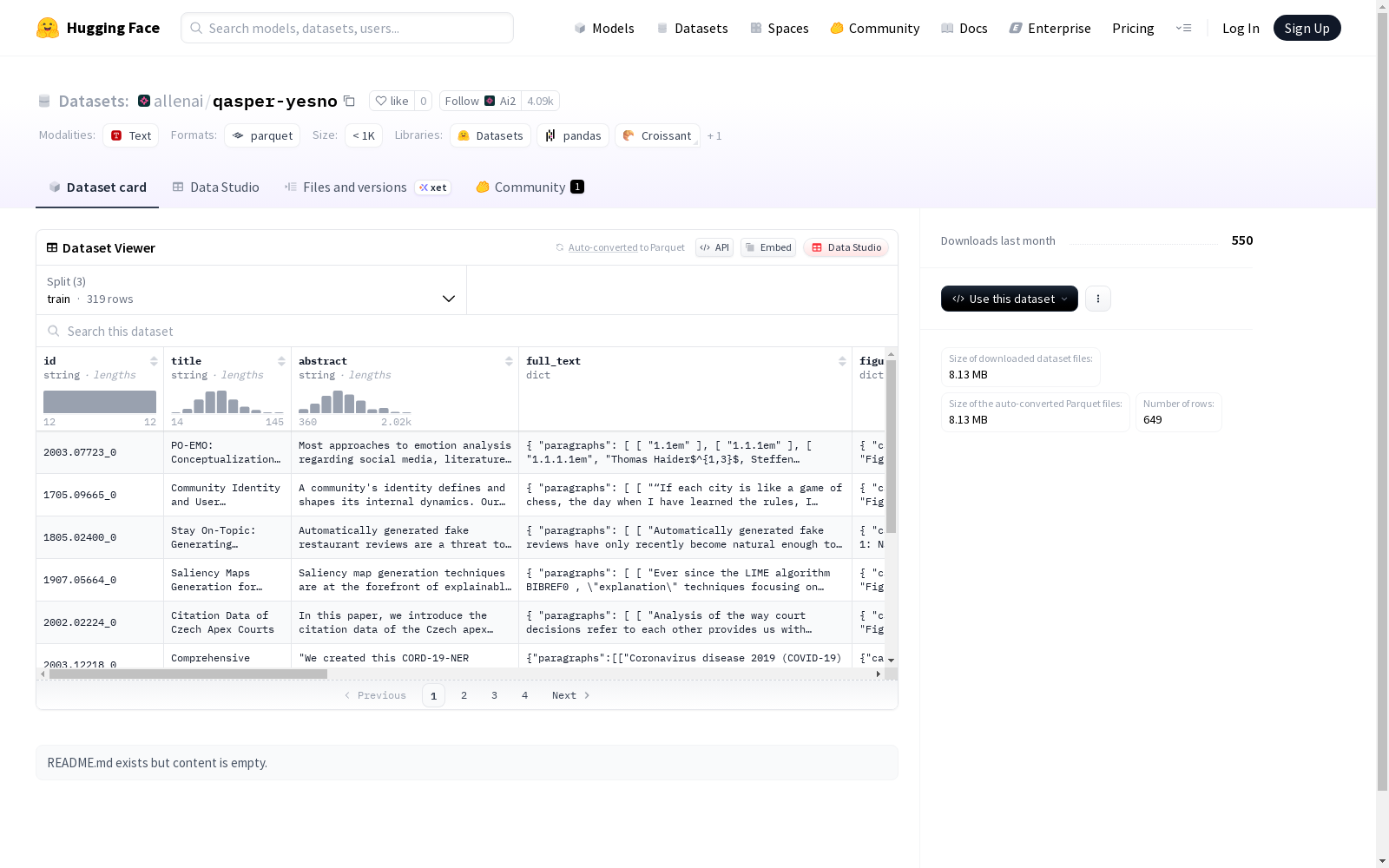
这是一个包含论文标题、摘要、全文(包括段落和章节标题)、图表(包括标题和文件)、问题、问题ID、NLP背景、主题背景、阅读论文情况、搜索查询、问题编写者、证据和答案等字段的数据集。数据集分为训练集、验证集和测试集,适用于文本分析和处理任务。
This is a dataset containing fields such as paper titles, abstracts, full texts (including paragraph and section titles), figures and tables (including their captions and associated files), questions, question IDs, NLP backgrounds, topic backgrounds, paper reading statuses, search queries, question authors, evidence and answers, and other related fields. The dataset is split into training, validation, and test sets, and is suitable for text analysis and processing tasks.
创建时间:
2025-05-29
搜集汇总
数据集介绍
构建方式
在科学文献问答领域,qasper-yesno数据集通过系统化流程构建而成。研究团队从开放获取学术论文中提取结构化内容,包括标题、摘要、全文段落以及图表信息。针对每篇论文,由领域专家设计二元判断型问题,确保问题与论文内容深度关联。标注过程中严格记录证据来源和问题背景,形成包含319个训练样本、111个验证样本和219个测试样本的标准化数据集。
使用方法
使用者可通过HuggingFace数据集库直接加载qasper-yesno的默认配置,自动获取训练、验证和测试分划。数据加载后呈现为结构化字典格式,关键字段包括论文全文、问题文本和证据段落。研究人员可基于该数据集开发科学文献理解模型,特别适用于证据检索和二元分类任务的性能评估。测试集未标注答案的设计支持盲测评估,符合学术研究规范。
背景与挑战
背景概述
qasper-yesno数据集于2021年由艾伦人工智能研究所(Allen Institute for AI)主导发布,旨在推动科学文献问答系统的研究进程。该数据集聚焦于从计算机科学和生物学领域的学术论文中提取结构化信息,通过提供论文标题、摘要、全文段落以及图表说明等多元特征,构建了一个专门针对二分类(是/否)问题的问答基准。其核心研究问题在于提升模型对科学文本深层语义的理解能力,特别是在处理专业术语和复杂逻辑关系时的准确性,为自然语言处理领域中的证据检索和推理任务提供了重要支撑。
当前挑战
该数据集首要挑战在于解决科学文献问答中证据定位与逻辑推理的复杂性,要求模型从长篇学术文本中精准识别支持答案的关键片段,同时应对专业术语和多义表达带来的歧义问题。构建过程中的难点包括人工标注的高成本与一致性保障,需依赖领域专家对论文内容进行精细的答案标注和证据提取;此外,数据稀疏性与领域偏差也构成显著障碍,例如生物学与计算机科学论文的表述差异可能影响模型的泛化性能。
常用场景
经典使用场景
在科学文献问答领域,qasper-yesno数据集被广泛应用于评估模型对学术论文内容的理解能力。该数据集通过提供论文全文、图表及结构化问题,支持研究者训练系统进行精确的是非判断回答。典型应用包括构建端到端的问答管道,其中模型需从复杂文本中提取证据并生成二元答案,这有助于推动机器阅读理解的边界。
解决学术问题
该数据集主要针对科学文献中信息检索与验证的挑战,解决了传统模型难以处理长文本多模态数据的局限。通过融合摘要、全文及图表证据,它为自然语言处理领域提供了验证推理能力的新基准,显著提升了学术知识抽取的准确性与可解释性,对智能学术助手的发展具有奠基意义。
实际应用
在实际场景中,qasper-yesno可集成于学术搜索引擎或文献管理工具,辅助研究人员快速验证论文中的特定论断。例如,在医学或工程领域,系统能自动分析论文结论的可信度,减少人工查阅成本。这种应用不仅提升了科研效率,还为科学传播的自动化提供了技术支撑。
数据集最近研究
最新研究方向
在科学文献问答领域,qasper-yesno数据集以其对学术论文结构化内容的深度解析能力,正推动着自然语言处理技术的前沿探索。当前研究聚焦于利用该数据集的多模态特征,如文本段落与图表信息的融合,开发能够处理复杂推理任务的问答模型。热点方向包括结合大语言模型的上下文理解能力,提升对科学文献中隐含逻辑的识别精度,同时关注证据检索机制的优化,以增强答案的可解释性。这一趋势不仅加速了学术知识自动化挖掘的进程,也为跨学科研究提供了可靠的技术支撑,凸显了其在智能学术助手开发中的关键价值。
以上内容由遇见数据集搜集并总结生成


