DarijaStory
收藏DarijaStory 数据集概述
数据集描述
数据集摘要
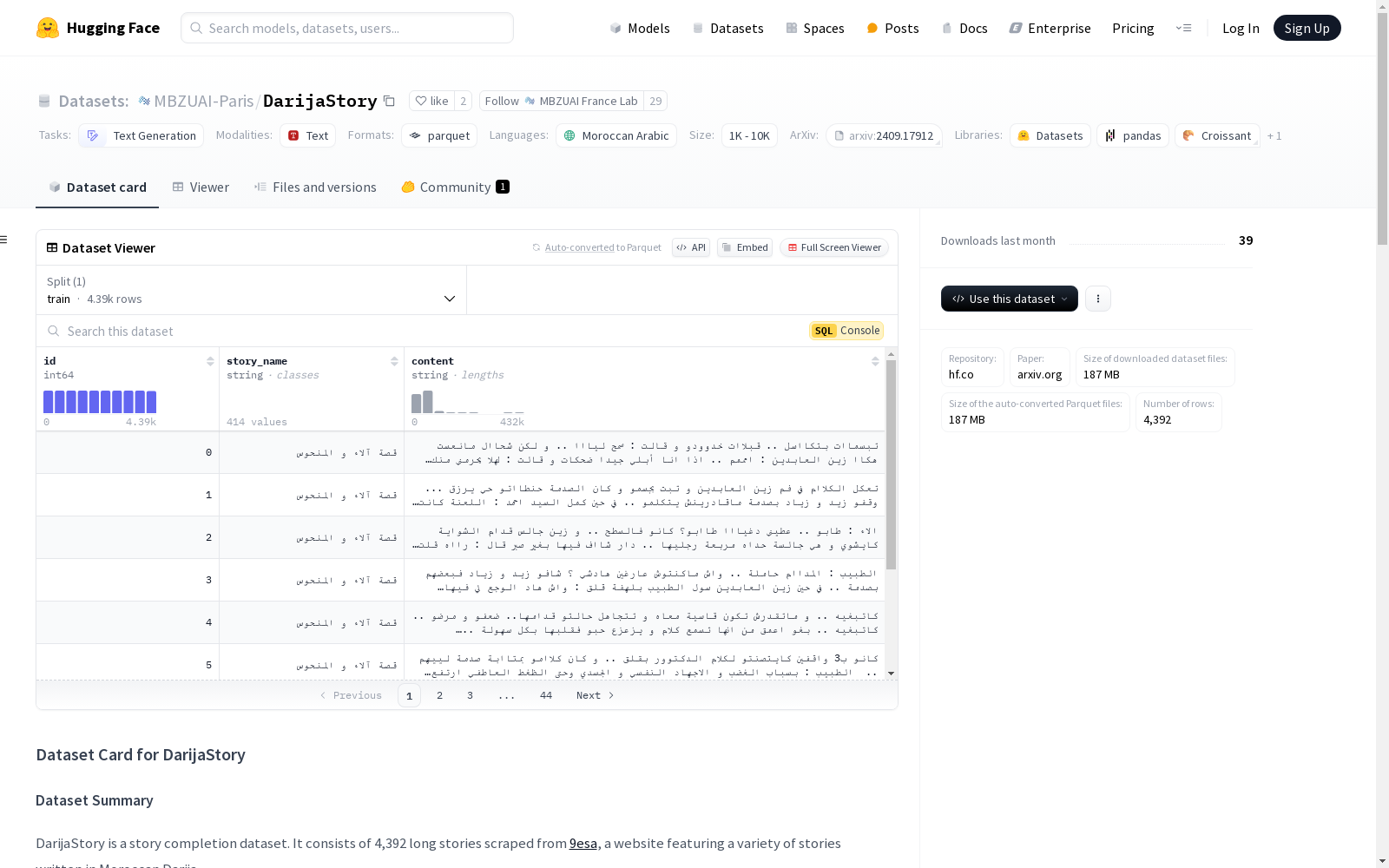
DarijaStory 是一个故事完成数据集,包含从 9esa 网站上抓取的 4,392 个长篇故事,这些故事以摩洛哥达里亚语(Darija)编写。
支持的任务和排行榜
- 任务类别: 条件文本生成
- 任务: 摩洛哥达里亚语的故事完成
语言
该数据集提供摩洛哥阿拉伯语(Darija)版本。
数据集结构
数据实例
每个数据实例包含一个故事或故事的一个章节。
示例数据实例:
json { id: 1170, story_name: قصة اللؤلؤة السوداء, content: حلات عوييناتها بتقااالة... حاسة بحرييق كيقطع فراااسها... قوي وعينيها مضببين ليها رؤيا ... هزات يديها بتقالة حطاتها فوق رااسها.... }
数据字段
- id: (整数) 故事的索引。
- story_name: (字符串) 故事名称。
- content: (整数) 故事内容。
数据分割
数据集包含一个分割:
| 分割 | 实例数量 |
|---|---|
| train | 4,392 |
数据集创建
策划理由
该数据集从 9esa.com 网站上抓取,该网站包含以达里亚语编写的故事。
个人和敏感信息
该数据集不包含个人、私人或敏感信息。所有故事均为一般性内容,涵盖与摩洛哥相关的虚构或社会主题。
使用数据的注意事项
数据集的社会影响
该数据集促进了能够理解和生成摩洛哥达里亚语扩展叙事的语言模型的发展和评估,从而推动了在代表性不足的语言中的 NLP 进步,并支持 AI 应用中的文化多样性。
偏见的讨论
该数据集包含摩洛哥达里亚语的故事,这些故事可能反映了与摩洛哥相关的特定文化和社会主题。用户在使用该数据集进行一般语言模型应用时应意识到这一点。
附加信息
数据集策展人
- MBZUAI-Paris 团队
许可信息
- 许可证: ODC-BY
引用信息
如果您在研究中使用此数据集,请引用我们的论文: none @article{shang2024atlaschatadaptinglargelanguage, title={Atlas-Chat: Adapting Large Language Models for Low-Resource Moroccan Arabic Dialect}, author={Guokan Shang and Hadi Abdine and Yousef Khoubrane and Amr Mohamed and Yassine Abbahaddou and Sofiane Ennadir and Imane Momayiz and Xuguang Ren and Eric Moulines and Preslav Nakov and Michalis Vazirgiannis and Eric Xing}, year={2024}, eprint={2409.17912}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2409.17912}, }