llmradar/eu-llm-providers
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/llmradar/eu-llm-providers
下载链接
链接失效反馈官方服务:
资源简介:
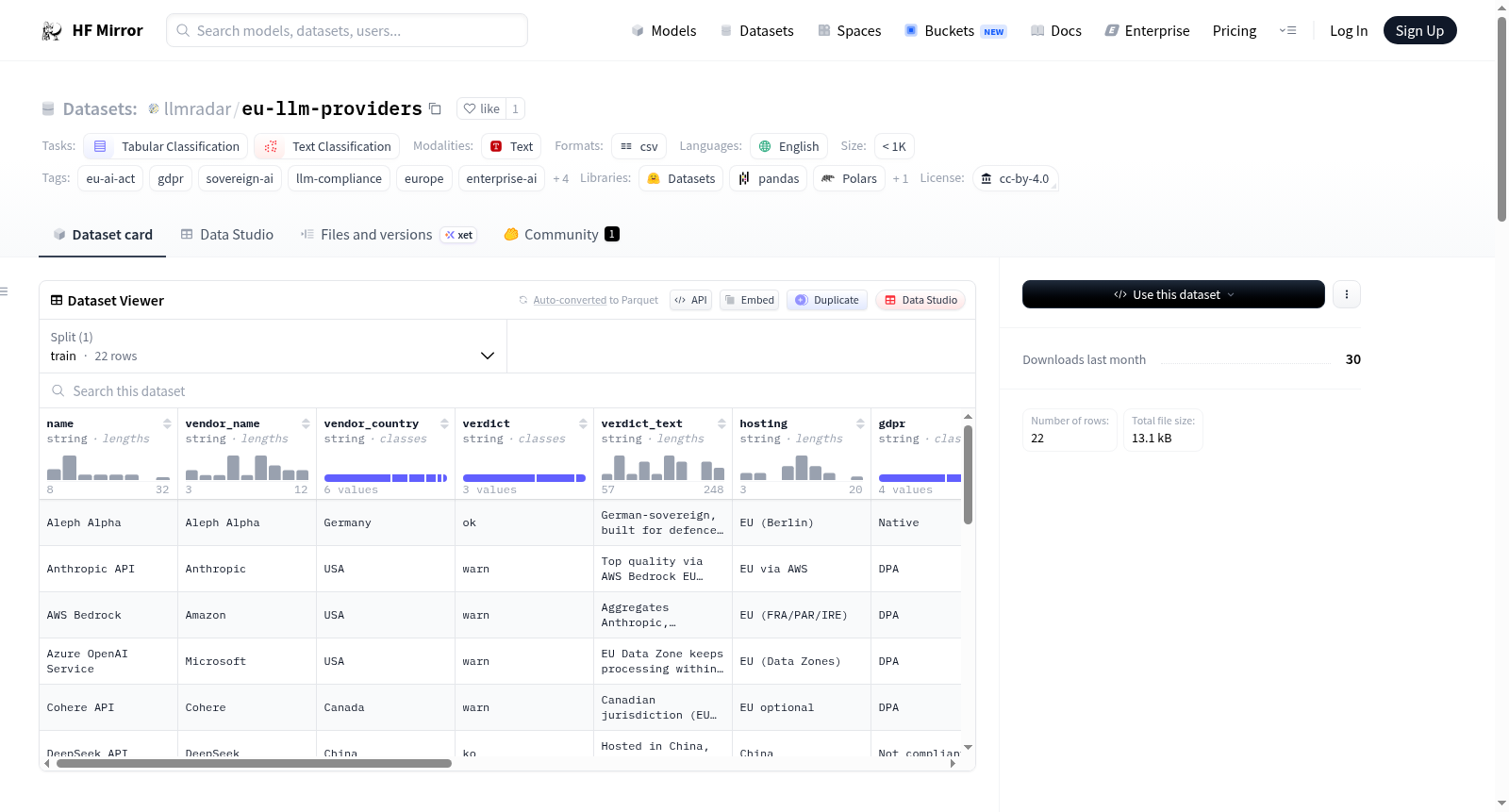
该数据集名为LLM API提供商的欧盟准备情况,由LLM Radar精心整理,最新更新于2026年4月25日,包含22个提供商的信息。这是一个手动审核的数据集,评估了托管大型语言模型(LLM)API提供商在欧盟法规(如GDPR、数据保护、AI法案、数字服务法案)下的准备情况。每个提供商在四个维度上被评分:托管、GDPR、司法管辖区、AI法案,并附有纯文本的编辑裁决和指向完整报告的链接。主要用途包括:欧盟组织的采购和供应商风险尽职调查、主权AI和数据驻留研究、关于LLM合规性的分类器训练/评估集、以及欧盟LLM市场状态的基准测试。数据集字段包括提供商名称、供应商名称、供应商国家、总体裁决、裁决文本、托管位置、GDPR/DPA立场、司法管辖区、AI法案准备情况、标签、最后审核日期、LLM Radar链接和稳定标识符。数据集采用CC BY 4.0许可,每周更新一次。
The dataset, titled EU-readiness of LLM API providers, is curated by LLM Radar and was last updated on 2026-04-25, covering 22 providers. It is a manually-reviewed dataset assessing hosted Large Language Model (LLM) API providers on their readiness for use under EU regulation (GDPR, Data Protection, AI Act, Digital Services Act). Each provider is graded on four axes — hosting, GDPR, jurisdiction, AI Act — with a plain-text editorial verdict and a canonical link back to the full write-up. Primary use cases include: Procurement and vendor-risk due diligence for EU-based organisations, Sovereign-AI and data-residency research, Training classifiers / evaluation sets about LLM compliance posture, and Benchmarking the state of the EU LLM market over time. The dataset fields include provider name, vendor name, vendor country, overall verdict, verdict text, hosting location, GDPR/DPA posture, jurisdiction, AI Act readiness, tags, last reviewed date, LLM Radar URL, and stable identifier. The dataset is released under CC BY 4.0 license and is updated weekly.
提供机构:
llmradar
搜集汇总
数据集介绍
构建方式
该数据集由LLM Radar团队人工编纂,旨在评估托管式大语言模型(LLM)API提供商在欧盟法规框架下的合规性。构建过程严格依托公开可得的信息源,包括提供商文档、服务条款、数据保护协议、子处理方清单、监管指引、模型卡片及供应商公开声明。每一条目均经手动审查,并按照红绿灯三档评级体系对四个核心维度——托管地点、GDPR合规性、管辖法律与AI法案准备度——进行评分。数据以CSV格式存储,每周从LLM Radar编辑数据库自动更新,确保时效性与准确性。
特点
该数据集的核心特点在于其体系化的多维评估架构与人工审查的严谨性。不同于自动化采集的数据库,每一家提供商均经过资深编辑的定性分析,涵盖托管地点(如“仅欧盟”或“美国+欧盟”)、GDPR数据保护协议、管辖法律下的数据访问机制以及AI法案的合规准备度。此外,数据集提供整体裁决(ok/warn/ko)及纯文本编辑评语,并附带指向LLM Radar网站的规范链接,便于深度溯源。标签系统覆盖银行、医疗、国防等细分领域,增强了在特定场景下的应用粒度。
使用方法
该数据集主要适用于欧盟组织进行采购尽职调查与供应商风险排查,同时服务于主权AI与数据驻留研究。研究者可利用其中的多维度标签与评级训练分类器或构建合规态势评估集。实际应用中,用户可直接通过CSV文件内的字段如verdict、gdpr、ai_act等筛选与比较不同提供商的表现,或结合llmradar_url访问完整分析文章获取更深入的背景信息。由于每行均附有last_reviewed_at时间戳,用户可根据需要按最新更新过滤数据,确保评估基于最近的市场状态。
背景与挑战
背景概述
随着欧盟《人工智能法案》(AI Act)、《通用数据保护条例》(GDPR)及《数字服务法案》等法规的相继施行,大型语言模型(LLM)API服务提供商在欧盟市场的合规性成为企业采购与风险管理的核心关切。由LLM Radar团队于2026年精心编纂并持续更新的eu-llm-providers数据集,专注于评估22家主流LLM API提供商在托管、GDPR合规、司法管辖及AI Act准备度四个维度的表现,旨在为欧盟组织提供供应商尽职调查、主权AI研究及合规态势基准测试的关键资源。该数据集通过手动审核公开资料形成,每一条目均附带编辑评价与来源链接,其系统化的交通灯评级体系(绿/黄/红)为学界与产业界理解欧盟LLM市场合规演化提供了量化工具,对推动负责任AI部署与数据主权保护具有显著影响力。
当前挑战
该数据集所解决的领域挑战核心在于:欧盟监管框架下,企业难以从碎片化的服务条款、数据保护协议及合规声明中快速评估LLM API提供商的真实合规状态,且市场缺乏统一、透明的评级标准。构建过程中面临的挑战包括:1) 数据源高度异构——供应商文档、子处理者列表及监管指南分布于不同格式与渠道,需逐一人工交叉验证;2) 法规解释存在灰色地带——如GDPR对跨境数据传输的适用边界、AI Act对通用目的AI系统的分类标准尚存争议,导致评级判定需兼顾法律文本与行业实践;3) 时效性压力——法规更新与供应商政策调整频繁,数据集需以周为周期刷新,同时确保每项变更经手动复审,在规模与准确性间维持平衡。
常用场景
经典使用场景
在欧盟AI法案与通用数据保护条例(GDPR)日益严格的监管框架下,评估大型语言模型(LLM)API提供商是否合规成为关键需求。该数据集基于人工审核,对22家主流LLM API提供商在托管位置、GDPR合规性、法律管辖区域及AI法案准备度四个维度进行评级,并附带简明编辑评语与详细评测链接。经典使用场景涵盖供应商风险尽职调查、主权AI与数据驻留研究、合规性分类器训练以及欧盟LLM市场格局的动态基准分析。通过交通灯式的三级评分机制,该数据集为组织提供了一种可量化、可复现的合规评估工具,适用于采购决策与监管审计。
实际应用
现实世界中,欧盟境内企业与公共机构在采购LLM API时面临复杂的合规迷宫,特别是金融、医疗、国防与政务等敏感行业。该数据集直接服务于供应商筛选与合同合规审查流程,帮助采购团队快速甄别哪些提供商能将推理计算保留在欧盟境内、签署标准合同条款(SCCs)或持有充分性认定。初创企业亦可借助其中‘tags’字段锁定符合行业特殊监管要求(如银行保密与健康数据保护)的选项。此外,数据集每周更新并标注每项条目的人工复核日期,使其成为实时监控市场合规动态的实用仪表盘。
衍生相关工作
围绕该数据集,已衍生出多个方向的经典工作。其一,基于其结构化特征,研究者构建了LLM合规性分类器与回归模型,预测新提供商在不同监管轴上的评级,从而实现了合规评估的部分自动化。其二,借助‘verdict_text’与‘vendor_country’字段,学者开展了欧盟内外司法管辖区的横向比较研究,揭示数据主权偏好与公司注册地之间的统计关联。其三,该数据集被用作‘欧盟AI法案准备度指数’的原始样本,衍生出动态可视化平台与市场季度报告,跟踪合规趋势的演变。此外,其开源CC BY 4.0许可鼓励了社区驱动的定期审计与贡献机制,形成了可持续的更新生态。
以上内容由遇见数据集搜集并总结生成


