mmlu_5_shot
收藏Hugging Face2025-09-06 更新2025-09-07 收录
下载链接:
https://huggingface.co/datasets/zaaabik/mmlu_5_shot
下载链接
链接失效反馈官方服务:
资源简介:
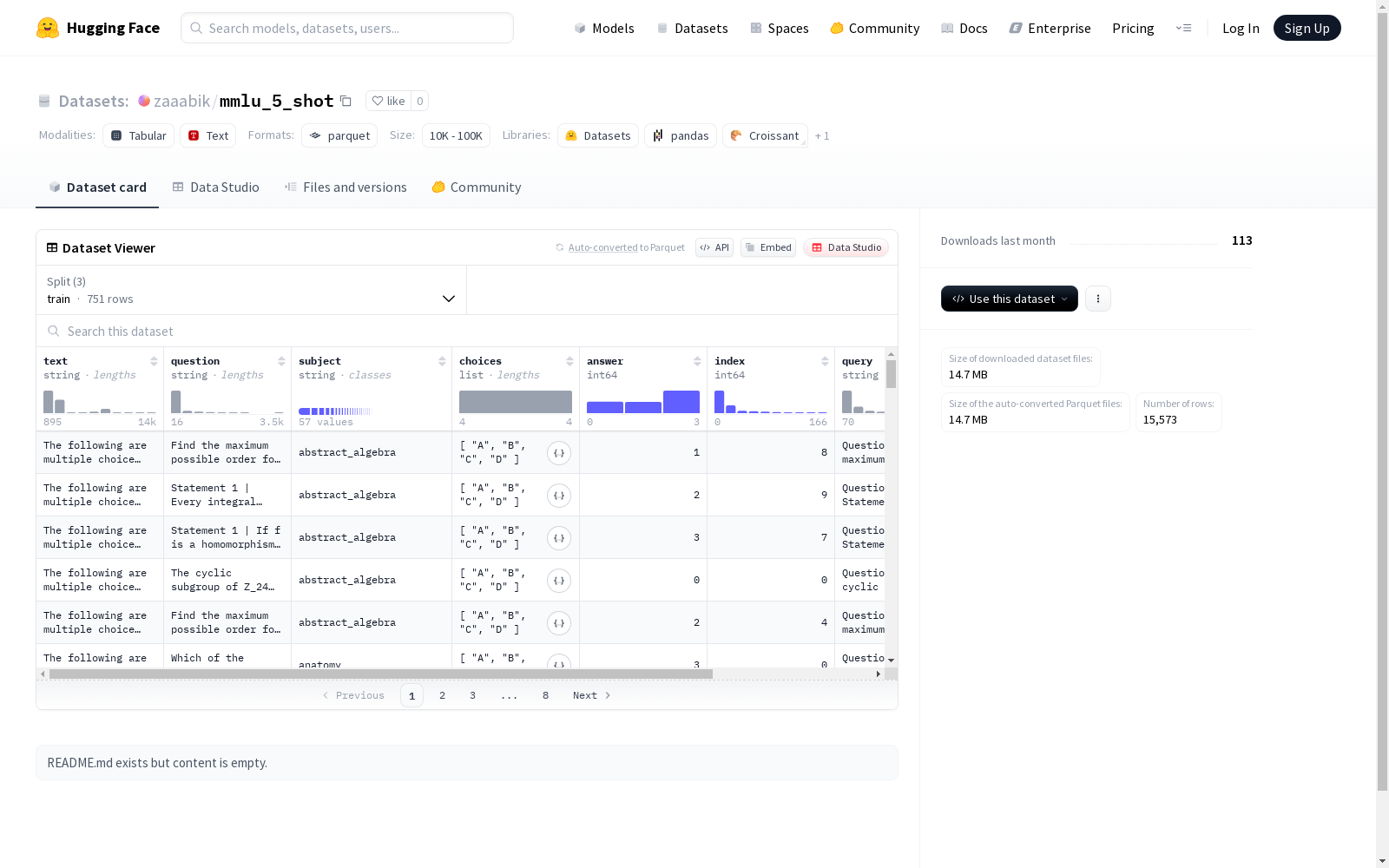
这是一个包含文本、问题、主题、选项、答案、索引、查询和黄金标准等字段的数据集。数据集分为测试集、验证集和训练集三个部分,分别包含不同数量的示例。总数据大小超过61MB,下载大小约为14.7MB。
This is a dataset containing fields such as text, question, topic, option, answer, index, query, and gold standard. The dataset is divided into three subsets: test set, validation set, and training set, each with a distinct number of samples. The total data size exceeds 61 MB, while the download size is approximately 14.7 MB.
创建时间:
2025-08-24
原始信息汇总
数据集概述
基本信息
- 数据集名称: mmlu_5_shot
- 来源平台: Hugging Face
- 下载大小: 14,681,442 字节
- 数据集大小: 61,527,393 字节
数据特征
- 特征列表:
- text (字符串类型)
- question (字符串类型)
- subject (字符串类型)
- choices (字符串序列)
- answer (int64类型)
- index (int64类型)
- query (字符串类型)
- gold (int64类型)
数据划分
- 测试集 (test):
- 样本数量: 14,042
- 数据大小: 55,455,061 字节
- 验证集 (validation):
- 样本数量: 780
- 数据大小: 3,093,806 字节
- 训练集 (train):
- 样本数量: 751
- 数据大小: 2,978,526 字节
配置信息
- 默认配置 (default):
- 测试集文件路径: data/test-*
- 验证集文件路径: data/validation-*
- 训练集文件路径: data/train-*
搜集汇总
数据集介绍
构建方式
在知识评估领域,mmlu_5_shot数据集通过精心设计的五样本学习框架构建,涵盖了57个学科领域的多项选择题。数据来源于标准化的学术和常识性内容,每个样本包含问题文本、选项序列及正确答案索引,确保了评估的广度和深度。
特点
该数据集以其多学科覆盖和结构化特征著称,包含文本、问题、主题及选项序列等字段,支持模型在有限样本下的泛化能力测试。其验证集和测试集规模适中,便于精确评估模型性能,同时保持了数据的多样性和平衡性。
使用方法
使用者可通过加载标准数据分割进行模型训练与评估,利用五样本设置模拟少样本学习场景。典型应用包括模型在多项选择题上的准确率计算和跨学科泛化分析,适用于学术研究和模型基准测试。
背景与挑战
背景概述
大规模多任务语言理解数据集(MMLU)由加州大学伯克利分校与谷歌研究院于2020年联合推出,旨在评估模型在跨学科知识推理与综合理解方面的能力。该数据集涵盖人文、社科、理工及专业领域共57个学科,通过多选题形式检验模型对复杂语义和逻辑关系的把握。其构建推动了通用人工智能在知识密集型任务中的发展,为自然语言处理领域的评估体系设立了新基准。
当前挑战
MMLU数据集核心挑战在于解决模型对跨领域知识的泛化与深层推理问题,要求系统同时具备专业知识提取和逻辑分析能力。构建过程中需协调学科专家的标注一致性,确保57个领域问题的准确性与权威性。此外,数据平衡性设计需规避学科偏差,而五样本学习设定增加了模型在有限示例下快速适应的难度,对评估框架的鲁棒性提出更高要求。
常用场景
经典使用场景
在人工智能领域的知识评估中,MMLU_5_shot数据集作为大规模多任务语言理解基准,被广泛用于测试模型在57个学科领域的综合表现。研究者通过五样本学习设置,考察模型在有限示例下快速适应新任务的能力,涵盖从基础数学到专业医学的广泛知识范畴。这种设计能有效衡量模型的知识广度和推理深度,成为评估通用人工智能系统的重要试金石。
实际应用
在实际应用中,该数据集为教育科技和智能辅导系统提供了可靠的评估基准。教育机构利用其构建自适应学习系统,通过分析学生在各学科领域的表现数据,精准识别知识薄弱环节。企业招聘平台将其作为专业能力测评工具,对应聘者的综合知识水平进行多维评估。医疗领域则借鉴其评估框架,开发医学知识诊断和继续教育系统。
衍生相关工作
基于该数据集衍生的经典工作包括知识蒸馏框架KnowBERT和跨模态推理模型MMLU-Pro。哈佛大学团队开发的Subject-Wise分析工具实现了学科层面的细粒度评估,MetaAI提出的Chain-of-Thought增强方法显著提升了复杂问题的推理准确率。这些工作共同推动了少样本学习理论的发展,为构建更智能的知识处理系统奠定了坚实基础。
以上内容由遇见数据集搜集并总结生成


