ai4privacy/pii-masking-openpii-1m
收藏Hugging Face2026-04-04 更新2026-03-29 收录
下载链接:
https://hf-mirror.com/datasets/ai4privacy/pii-masking-openpii-1m
下载链接
链接失效反馈官方服务:
资源简介:
---
license: other
license_name: cc-by-4.0
language:
- en
- fr
- de
- es
- it
- nl
- bg
- cs
- da
- el
- et
- fi
- hr
- hu
- lt
- lv
- pl
- pt
- ro
- sk
- sl
- sr
- sv
task_categories:
- token-classification
- text-generation
tags:
- privacy
- pii
- sensitive-data
- data-masking
- data-anonymization
- ner
- synthetic
- multilingual
- ai4privacy
- openpii
pretty_name: "OpenPII 1M — Multilingual PII Masking Dataset (19 Labels, 23 Languages)"
size_categories:
- 1M<n<10M
source_datasets:
- original
configs:
- config_name: default
data_files:
- split: train
path: data/train.jsonl
- split: validation
path: data/validation.jsonl
---
# OpenPII 1M — Multilingual PII Masking Dataset
<p align="center">
<img src="assets/logo.png" alt="Ai4Privacy" width="200"/>
</p>
## Overview
The **OpenPII 1M** dataset is a large-scale, multilingual collection of **1,428,143 synthetic text examples** with fine-grained PII (Personally Identifiable Information) annotations, spanning **23 European languages** and **19 entity types**.
Built to advance open research in privacy-preserving NLP, this dataset enables the development and benchmarking of **Named Entity Recognition (NER)** models, **token classification** pipelines, and **data masking** systems that work across languages and borders.
Each example contains the original text, a masked version with labeled placeholders, span-level annotations, and pre-computed BIO token labels compatible with transformer-based models (mBERT, XLM-R, ModernBERT, etc.).
## Dataset Details
| Property | Value |
|:---|:---|
| **Total Examples** | 1,428,143 |
| **Train Split** | 1,143,397 |
| **Validation Split** | 284,746 |
| **Unique Labels** | 19 |
| **Languages** | 23 |
| **Total Annotations** | 10,328,208 |
| **Format** | JSON Lines (.jsonl) |
| **License** | CC-BY-4.0 |
| **Contact** | `enterprise@ai4privacy.com` |
## Language Coverage
<p align="center">
<img src="assets/europe_language_map.png" alt="Language Coverage Map — Europe" width="800"/>
</p>
The dataset spans **29 regions** — 25 European countries plus Canada (CA), United States (US), Mexico (MX), and India (IN).
<p align="center">
<img src="assets/language_distribution.png" alt="Language Distribution" width="800"/>
</p>
## Label Taxonomy (19 Labels)
<p align="center">
<img src="assets/label_distribution.png" alt="Label Distribution" width="800"/>
</p>
| Label | Count | Description |
|:---|---:|:---|
| `DATE` | 1,218,939 | Dates and temporal references |
| `GIVENNAME` | 1,205,300 | First / given names |
| `SURNAME` | 1,056,355 | Last / family names |
| `EMAIL` | 769,479 | Email addresses |
| `CITY` | 721,890 | City names |
| `TITLE` | 670,650 | Personal titles (Mr, Dr, etc.) |
| `TELEPHONENUM` | 574,865 | Phone numbers |
| `AGE` | 512,150 | Age values |
| `STREET` | 484,891 | Street names |
| `BUILDINGNUM` | 476,224 | Building / house numbers |
| `ZIPCODE` | 443,413 | Postal / ZIP codes |
| `IDCARDNUM` | 333,065 | National ID card numbers |
| `CREDITCARDNUMBER` | 320,504 | Credit card numbers |
| `DRIVERLICENSENUM` | 286,935 | Driver's license numbers |
| `GENDER` | 277,496 | Gender identifiers |
| `TAXNUM` | 266,967 | Tax identification numbers |
| `SEX` | 256,019 | Biological sex |
| `SOCIALNUM` | 246,414 | Social security numbers |
| `PASSPORTNUM` | 206,652 | Passport numbers |
## Data Structure
Each line in the JSONL files is a JSON object:
```json
{
"source_text": "John Smith lives at 42 Rue de Rivoli, 75001 Paris.",
"masked_text": "[GIVENNAME_1] [SURNAME_1] lives at [BUILDINGNUM_1] [STREET_1], [ZIPCODE_1] [CITY_1].",
"privacy_mask": [
{"value": "John", "start": 0, "end": 4, "label": "GIVENNAME"},
{"value": "Smith", "start": 5, "end": 10, "label": "SURNAME"},
{"value": "42", "start": 20, "end": 22, "label": "BUILDINGNUM"},
{"value": "Rue de Rivoli", "start": 23, "end": 36, "label": "STREET"},
{"value": "75001", "start": 38, "end": 43, "label": "ZIPCODE"},
{"value": "Paris", "start": 44, "end": 49, "label": "CITY"}
],
"split": "train",
"uid": "openpii-abc123",
"language": "fr",
"region": "FR",
"script": "Latn",
"mbert_tokens": ["[CLS]", "John", "Smith", "lives", "..."],
"mbert_token_classes": ["O", "B-GIVENNAME", "B-SURNAME", "O", "..."]
}
```
## Use Cases
* **NER Research**: Train and evaluate multilingual token classification models for PII detection
* **Privacy-Preserving NLP**: Build data anonymization and masking pipelines across 23 languages
* **Multilingual Benchmarking**: Compare PII detection models across language families (Germanic, Romance, Slavic, Finno-Ugric, Baltic, Hellenic)
* **Compliance Tools**: Develop systems for GDPR, CCPA, and other data protection regulations
* **AI Safety**: Prevent language models from memorizing or exposing sensitive personal information
## Extended Taxonomies
This dataset covers the **19 core identity labels**. For research or enterprise applications requiring extended label taxonomies — including **82+ labels** across health (PHI), financial (PFI), digital (PDI), work (PWI), and location (PLI) categories — contact our team:
📧 **Email:** [`enterprise@ai4privacy.com`](mailto:enterprise@ai4privacy.com)
🌐 **Website:** [www.Ai4Privacy.com](https://www.ai4privacy.com)
🔗 **Contact Form:** [https://forms.gle/oDDYqQkyoTB93otHA](https://forms.gle/oDDYqQkyoTB93otHA)
## Related Datasets
| Dataset | Labels | Languages | Size | Category |
|:---|:---|:---|:---|:---|
| **pii-masking-2m** | 82+ | 24 | 2M+ | Full EPII taxonomy |
| **phi-masking-100k** | 20 | 8 | 100K+ | Personal Health Information |
| **pfi-masking-100k** | 20 | 8 | 100K+ | Personal Financial Information |
| **pdi-masking-100k** | 20 | 8 | 100K+ | Personal Digital Information |
| **pwi-masking-100k** | 20 | 8 | 100K+ | Personal Work Information |
| **pli-masking-100k** | 20 | 8 | 100K+ | Personal Location Information |
---
## p5y Data Analytics
This dataset is built on the [p5y](https://p5y.org) framework - think of it as i18n but for privacy. Just as i18n (internationalization) translates content into different locales, p5y translates sensitive data into privacy-safe formats through a standardized 3-step approach:
1. **Awareness** - Scan and markup private entities in unstructured text, producing a structured privacy mask with entity types, distribution, density, and risk assessment.
2. **Protection** - Control identified personal data through masking, pseudonymization, or k-anonymization, tailored to the specific use case and regulatory requirements.
3. **Quality Assurance** - Measure remaining privacy risk after anonymization, evaluating de-anonymization risks through expert annotation and automated assessment.
Learn more at [p5y.org](https://p5y.org)
---
## About Ai4Privacy
At Ai4Privacy, we are building the global seatbelt for Artificial Intelligence — enabling innovation while safeguarding personal information. We develop state-of-the-art datasets and tools for privacy-preserving AI.
* **Newsletter & Updates:** [www.Ai4Privacy.com](https://www.ai4privacy.com)
* **Join our Community:** [Discord](https://discord.gg/kxSbJrUQZF)
* **Contribute/Feedback:** [Open Data Access Form](https://forms.gle/iU5BvMPGkvvxnHBa7)
---
## Licensing and Terms of Use
* **License:** [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/). Copyright © 2026 Ai Suisse SA.
* **Permitted Use:** Research, commercial use, redistribution, and modification — subject to attribution requirements under CC-BY-4.0.
* **Attribution:** When using this dataset, please credit "Ai4Privacy / Ai Suisse SA" and link to this repository.
* **Responsible Use:** Use must comply with all applicable data privacy laws and regulations. This dataset contains **synthetic PII only** — no real personal data is included.
* **Citation:**
```bibtex
@dataset{ai4privacy_openpii_1m_2026,
author = {Ai4Privacy},
title = {OpenPII 1M — Multilingual PII Masking Dataset (19 Labels, 23 Languages)},
year = 2026,
publisher = {Hugging Face},
url = {https://huggingface.co/datasets/ai4privacy/pii-masking-openpii-1m}
}
```
## Legal Disclaimer
**No Warranty & Use at Your Own Risk:** This dataset is provided **"as is"** without warranties of any kind. Ai4Privacy and Ai Suisse SA make **no representations** regarding accuracy, completeness, or suitability. Use is **at your own risk**.
**No Liability:** Ai4Privacy, Ai Suisse SA, and affiliates **shall not be liable** for any damages (direct, indirect, consequential, etc.) arising from the use or inability to use this dataset.
**Compliance & Responsibility:** Users are solely responsible for ensuring their use complies with **all applicable laws, regulations, and ethical guidelines**, including data privacy laws (e.g., GDPR, CCPA) and AI regulations. **This dataset contains synthetic PII only — no real personal data is included.**
Ai4Privacy is a project affiliated with [Ai Suisse SA](https://www.aisuisse.com/).
提供机构:
ai4privacy
搜集汇总
数据集介绍
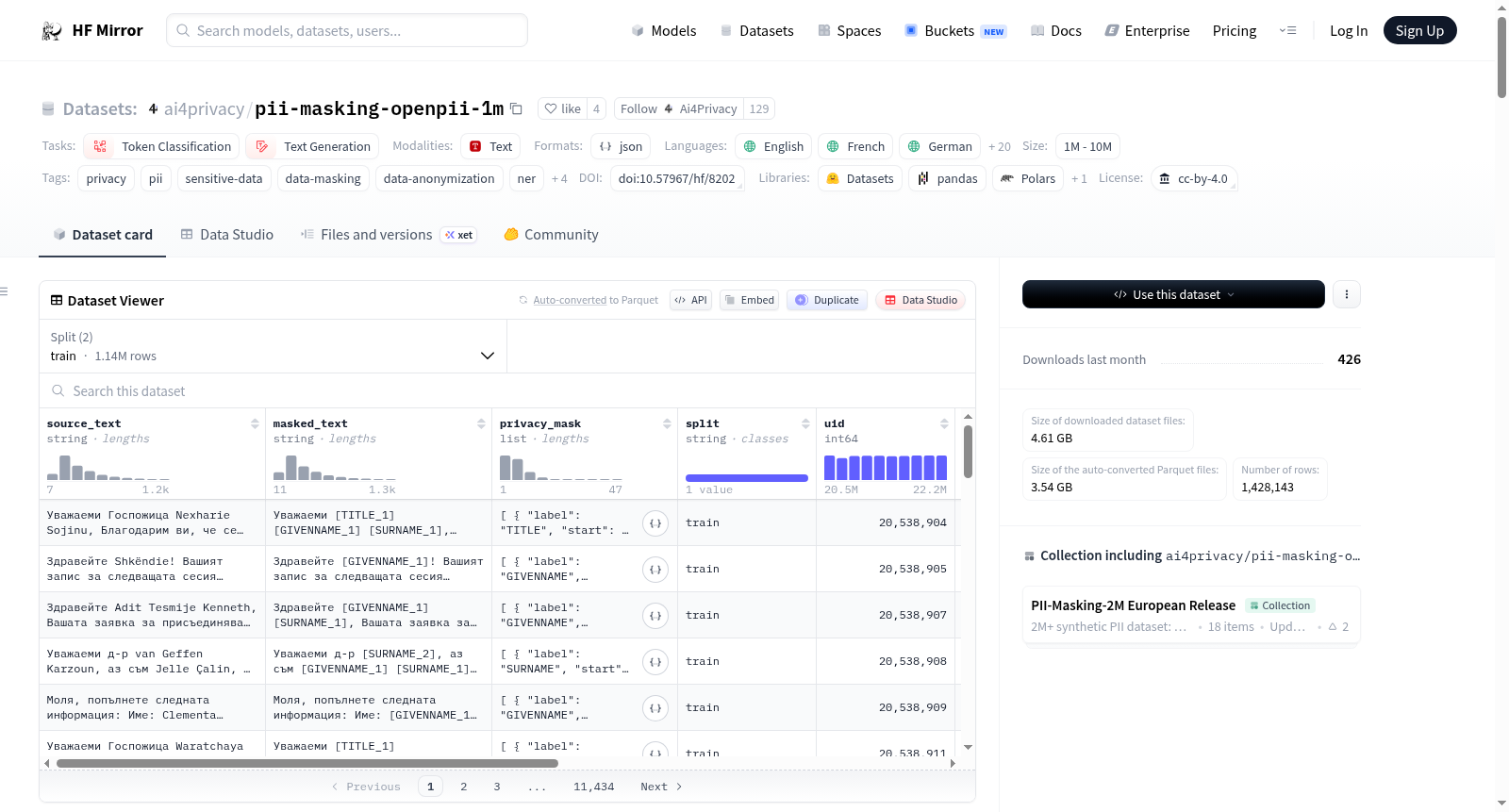
构建方式
在隐私保护自然语言处理领域,构建高质量标注数据集是推动技术发展的基石。OpenPII 1M数据集采用了先进的合成数据生成方法,基于p5y隐私框架系统性地构建而成。该框架遵循感知、保护与质量保证的三步流程,首先在非结构化文本中扫描并标记隐私实体,生成包含实体类型、分布与风险评估的结构化隐私掩码;随后根据具体用例与法规要求,通过掩码化或假名化等技术对识别的个人数据进行保护;最后通过专家标注与自动化评估,衡量匿名化后剩余的隐私风险,确保数据合成的质量与安全性。整个过程生成了超过142万条涵盖23种欧洲语言的合成文本示例,并附有细粒度的标注信息。
特点
该数据集的核心特征体现在其规模、多样性与专业性上。其囊括了1,428,143个文本示例,标注了超过一千万个实体,规模宏大。语言覆盖极具广度,横跨23种欧洲语言,涵盖了日耳曼语、罗曼语、斯拉夫语、芬兰-乌戈尔语、波罗的语和希腊语等多个语系,为跨语言模型研究提供了坚实基础。标注体系精细专业,定义了19种核心个人可识别信息实体类型,包括姓名、日期、地址、各类证件号码等,并提供了原始文本、掩码后文本、实体跨度标注以及与BERT等Transformer模型兼容的预计算BIO令牌标签,数据结构完整且便于直接用于模型训练与评估。
使用方法
该数据集为隐私增强的自然语言处理研究提供了多功能的实践平台。研究者可直接利用其JSON Lines格式的数据文件,其中的`mbert_tokens`和`mbert_token_classes`字段已为基于Transformer的命名实体识别模型提供了预处理好的输入与标签,极大简化了训练流程。数据集适用于开发与评估跨语言的令牌分类与序列标注模型,以检测文本中的个人可识别信息。同时,其提供的`masked_text`字段可直接服务于数据匿名化与掩码化管道的构建,助力开发符合GDPR、CCPA等数据保护法规的合规工具。通过在不同语系数据上进行测试,该数据集也能作为基准,用于比较各类PII检测模型的跨语言泛化能力与鲁棒性。
背景与挑战
背景概述
在数字时代,个人身份信息(PII)的保护已成为自然语言处理领域的关键议题。OpenPII 1M数据集由Ai4Privacy团队于2026年构建,旨在推动隐私保护型NLP的开放研究。该数据集包含超过140万条涵盖23种欧洲语言的合成文本示例,标注了19类精细的PII实体。其核心研究问题聚焦于跨语言环境下PII的自动检测与掩码,为开发符合GDPR等数据保护法规的匿名化系统提供了重要基准,显著提升了多语言隐私保护技术的可及性与标准化水平。
当前挑战
该数据集致力于解决多语言环境中个人身份信息的自动识别与匿名化挑战,其核心难点在于不同语言和文化背景下PII表达形式的巨大差异性,例如姓名、地址和证件编号的格式变异。在构建过程中,挑战主要源于大规模合成数据的生成与标注:需要确保合成文本的语义自然性,同时精确覆盖19类实体在23种语言中的分布,并维持标注跨度与BIO标签的一致性,以避免模型训练时的噪声干扰。
常用场景
经典使用场景
在隐私保护自然语言处理领域,OpenPII 1M数据集为多语言命名实体识别模型的训练与评估提供了标准化基准。该数据集涵盖23种欧洲语言和19类个人可识别信息实体,其大规模合成文本与精细标注结构,使得研究者能够系统性地开发跨语言PII检测模型,尤其在处理诸如姓名、地址、身份证号等敏感信息时,展现出卓越的泛化能力与一致性。
实际应用
在实际应用中,OpenPII 1M数据集被广泛集成于数据匿名化与脱敏流水线,服务于金融、医疗、客服等行业的多语言文本处理系统。基于该数据集训练的模型能够自动识别并掩码文档中的个人身份信息,助力企业满足跨境数据流转中的隐私合规要求,同时保障数据效用性,为安全的数据共享与分析提供了技术支撑。
衍生相关工作
围绕该数据集,学术界与工业界衍生出一系列经典工作,包括基于mBERT、XLM-R等架构的多语言PII识别模型优化研究,以及扩展至健康信息、财务信息等领域的细分标注体系构建。这些工作进一步深化了隐私实体识别的粒度,并催生了如pii-masking-2m等更庞大、标签体系更完善的数据集,形成了持续演进的隐私保护数据生态系统。
以上内容由遇见数据集搜集并总结生成


