MissBench
收藏arXiv2026-03-11 更新2026-03-12 收录
下载链接:
https://anonymous.4open.science/r/MissBench-4098/
下载链接
链接失效反馈官方服务:
资源简介:
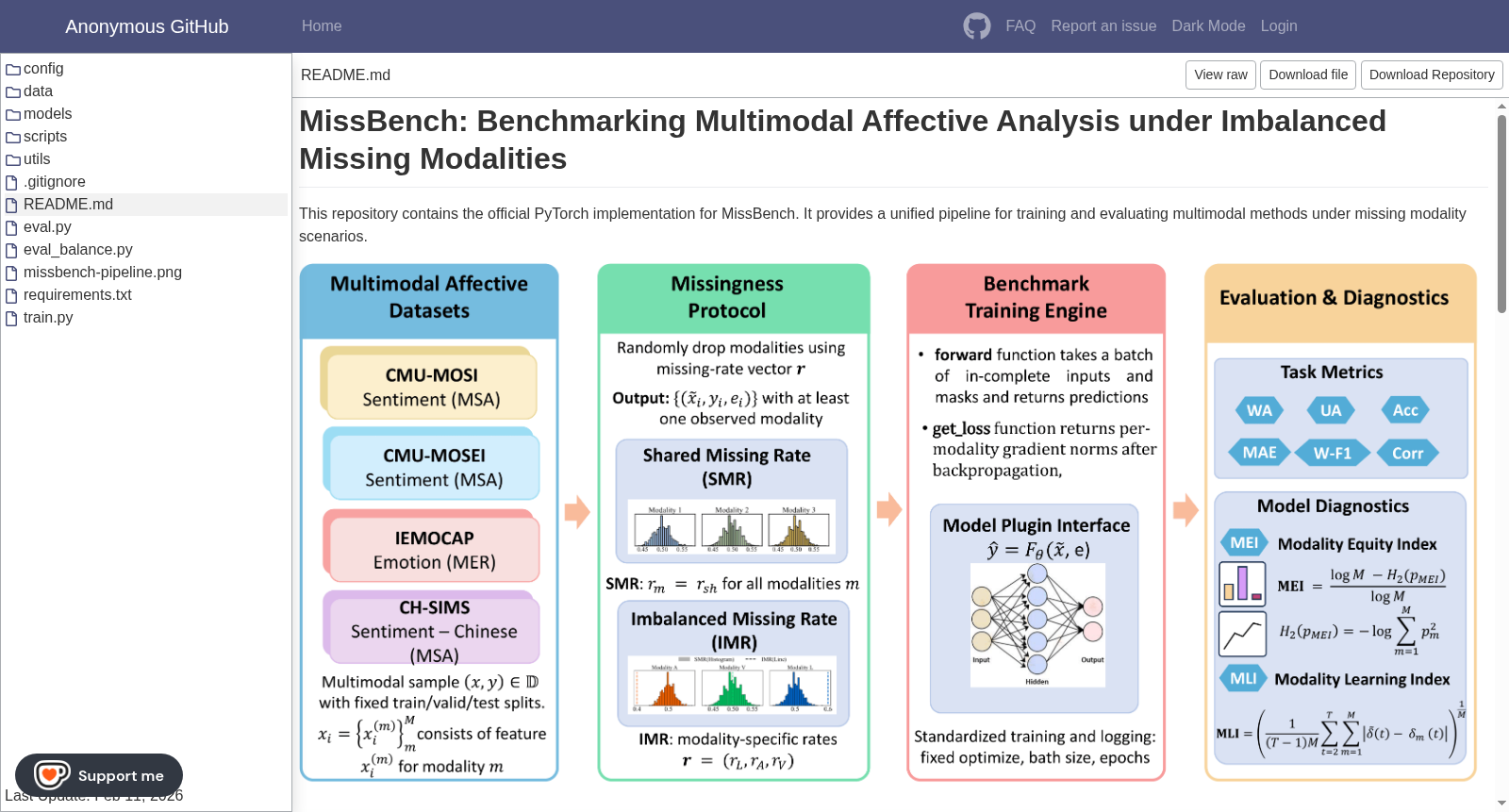
MissBench是由越南国立大学团队构建的多模态情感分析基准,整合了CMU-MOSI、CMU-MOSEI、IEMOCAP和CH-SIMS四个经典数据集,涵盖英语和中文的情感识别与情绪分析任务。该数据集创新性地设计了共享缺失率(SMR)和不平衡缺失率(IMR)两种协议,通过标准化数据分割和掩码种子实现可复现评估。其核心价值在于提出了模态公平指数(MEI)和模态学习指数(MLI)两大诊断指标,能有效量化不同模态在缺失条件下的贡献均衡性与优化动态,为现实场景中不完整多模态数据的研究提供系统性评估框架。
MissBench is a multimodal sentiment analysis benchmark constructed by the team from Vietnam National University. It integrates four classic datasets, namely CMU-MOSI, CMU-MOSEI, IEMOCAP and CH-SIMS, covering sentiment recognition and emotion analysis tasks in both English and Chinese. This dataset innovatively designs two protocols: Shared Missing Rate (SMR) and Imbalanced Missing Rate (IMR), and enables reproducible evaluation through standardized data splits and masking seeds. Its core value lies in proposing two diagnostic indicators, Modal Fairness Index (MEI) and Modal Learning Index (MLI), which can effectively quantify the contribution balance and optimization dynamics of different modalities under missing conditions, providing a systematic evaluation framework for research on incomplete multimodal data in real-world scenarios.
提供机构:
越南国立大学·工程与技术学院
创建时间:
2026-03-11
搜集汇总
数据集介绍
构建方式
在情感计算领域,多模态数据常因传感器故障或隐私限制而出现模态缺失,传统评估假设各模态均匀可用,忽视了现实中的不平衡缺失现象。MissBench的构建基于四个广泛使用的情感数据集——CMU-MOSI、CMU-MOSEI、IEMOCAP和CH-SIMS,通过设计共享缺失率与不平衡缺失率两种协议,系统化地模拟模态缺失场景。其采用随机掩码操作,为每个模态分配特定缺失概率,确保至少一个模态保留以维持监督学习框架,从而生成可控的不完整多模态样本集合。
特点
MissBench的突出特点在于其引入了两种诊断性指标:模态公平指数与模态学习指数。前者量化不同模态在缺失配置下的贡献均衡性,后者通过比较训练过程中各模态梯度范数来评估优化失衡程度。该基准不仅覆盖了英语与中文数据集,还提供了标准化的训练流程与模型插件接口,支持对多种方法在相同缺失条件下的公平比较。这些设计使得模型在平衡缺失率下表现出的稳健性,能在不平衡场景中暴露出潜在的模态不公平与梯度主导问题。
使用方法
研究人员可通过MissBench的统一管道,将自有模型封装为插件,并利用其前向与损失计算接口集成到基准框架中。在指定共享或不平衡缺失率协议后,系统自动生成掩码数据,执行标准化训练,并记录任务性能指标及诊断指数。用户可基于模态公平指数与模态学习指数的分析,深入探究模型在不同缺失配置下的模态贡献分布与优化动态,从而在多模态情感计算的实际部署中识别并缓解不平衡缺失带来的偏差。
背景与挑战
背景概述
多模态情感计算作为支撑情感分析与情绪识别的关键技术,在对话系统、呼叫中心及社交媒体等领域具有广泛应用。传统评估范式通常假设文本、声学与视觉模态具备同等可用性,然而现实场景中,部分模态因传感器故障、噪声干扰或隐私限制等因素,呈现出系统性缺失或质量退化,导致模态缺失率不平衡及训练偏差问题。为应对这一挑战,越南VNU工程与技术大学的研究团队于2026年提出了MissBench基准数据集。该数据集重构了IEMOCAP、CMU-MOSI、CMU-MOSEI及CH-SIMS四个广泛使用的情感数据集,并系统化定义了共享缺失率与不平衡缺失率两种协议,旨在为多模态情感模型在非平衡缺失模态场景下的鲁棒性评估提供标准化框架。
当前挑战
MissBench数据集致力于解决多模态情感分析在模态不平衡缺失条件下的评估难题,其核心挑战体现在两个层面。在领域问题层面,现有方法多基于均匀缺失假设,难以揭示模型在现实不平衡缺失场景下的模态贡献公平性与优化动态失衡问题,例如单一主导模态可能过度支配梯度更新,导致表征偏差。在构建过程层面,挑战在于如何设计可复现的缺失协议以精确模拟系统性缺失模式,并开发超越任务级指标的诊断工具。为此,MissBench引入了模态公平指数与模态学习指数,前者量化不同缺失配置下各模态贡献的均衡性,后者通过追踪训练中模态特异性梯度范数来刻画优化不平衡,从而暴露传统评估中隐藏的模型缺陷。
常用场景
经典使用场景
在情感计算领域,多模态数据融合常面临模态缺失的现实挑战,而MissBench通过标准化共享缺失率与不平衡缺失率协议,为模型评估提供了严谨的基准框架。该数据集在情感分析与情绪识别任务中,系统模拟了文本、语音和视觉模态的不平衡缺失场景,使得研究者能够深入探究不同模态在非对称缺失条件下的贡献度与优化动态。其经典使用场景涵盖了对现有多模态模型的压力测试,尤其是在极端不平衡缺失配置下,揭示模型在模态公平性与梯度稳定性方面的潜在缺陷,为改进模型鲁棒性提供了关键见解。
解决学术问题
MissBench致力于解决多模态情感计算中因模态不平衡缺失而引发的学术难题。传统评估方法通常假设各模态均匀可用,忽视了现实应用中某些模态更易缺失或成本更高的系统性偏差,导致模型在训练过程中出现梯度主导或表征偏斜。该数据集通过引入模态公平指数与模态学习指数,量化了不同缺失配置下模态贡献的均衡性以及优化过程中的梯度动态,从而揭示了仅靠任务级指标无法捕捉的模态不平等与学习失衡问题。这一工作填补了现有基准在区分共享与不平衡缺失机制方面的空白,推动了多模态学习向更公平、更稳健的方向发展。
衍生相关工作
MissBench的推出催生了一系列关注不平衡缺失问题的衍生研究。在基准构建方面,其启发了后续工作如MissMAC-Bench等,进一步扩展了多模态情感计算中缺失模态的评估维度。在方法论层面,RedCore与MCE等模型借鉴了MissBench的评估协议,专门设计了针对不平衡缺失率的表示学习与优化机制。同时,该数据集提出的模态公平指数与模态学习指数也被后续研究采纳为诊断工具,用于分析多模态融合中的梯度冲突与模态贡献偏差。这些衍生工作共同推动了多模态学习社区对不平衡缺失问题的深入理解,促进了更公平、更高效的模型设计。
以上内容由遇见数据集搜集并总结生成


