human-coherence-preferences-images
收藏Hugging Face2024-12-12 更新2024-12-13 收录
下载链接:
https://huggingface.co/datasets/Rapidata/human-coherence-preferences-images
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是一个用于文本到图像生成模型的人类标注一致性数据集,包含了超过120万个人类一致性投票。数据集通过展示两张图片并询问参与者哪张图片看起来更不奇怪或不自然,来收集人类对图像生成模型的一致性评价。数据集具有大规模、全球代表性、多样化的提示和领先模型的比较等特点。该数据集对于基准测试新的图像生成模型、开发更好的生成模型评估指标、理解全球对AI生成图像的偏好、训练和微调图像生成模型以及研究跨文化审美偏好等方面具有重要价值。
创建时间:
2024-12-02
原始信息汇总
Rapidata Image Generation Coherence Dataset
数据集概述
- 数据集名称: Rapidata Image Generation Coherence Dataset
- 数据集大小: 26,233,103,274 字节
- 下载大小: 17,836,409,651 字节
- 数据集版本: default
- 数据文件路径: data/train-*
- 许可证: cdla-permissive-2.0
- 语言: 英语 (en)
- 标签: Human, Preference, country, language, flux, midjourney, dalle3, stabeldiffusion, alignment, flux1.1, flux1, imagen3
- 规模分类: 1M<n<10M
- 任务类别:
- 文本生成图像 (text-to-image)
- 图像生成文本 (image-to-text)
- 问答 (question-answering)
- 强化学习 (reinforcement-learning)
数据集特征
- prompt: 字符串类型 (string)
- image1: 图像类型 (image)
- image2: 图像类型 (image)
- votes_image1: 整数类型 (int64)
- votes_image2: 整数类型 (int64)
- model1: 字符串类型 (string)
- model2: 字符串类型 (string)
- detailed_results: 字符串类型 (string)
- image1_path: 字符串类型 (string)
- image2_path: 字符串类型 (string)
数据集分割
- train: 63,748 个样本,26,233,103,274 字节
关键特性
- 大规模: 超过 1,200,000 个人类一致性投票,收集时间不到 100 小时
- 全球代表性: 来自全球各地的参与者
- 多样化的提示: 精心策划的提示,测试图像生成的各个方面
- 领先模型: 比较最先进的图像生成模型
应用场景
- 基准测试新的图像生成模型
- 开发更好的生成模型评估指标
- 理解全球对 AI 生成图像的偏好
- 训练和微调图像生成模型
- 研究跨文化审美偏好
数据收集
- 平台: Rapidata Python API
- 时间: 约 4 天
- 技术:
- 快速大规模数据收集
- 全球覆盖 145+ 个国家
- 内置质量保证机制
- 全面的代表性
- 成本效益高的规模化标注
搜集汇总
数据集介绍
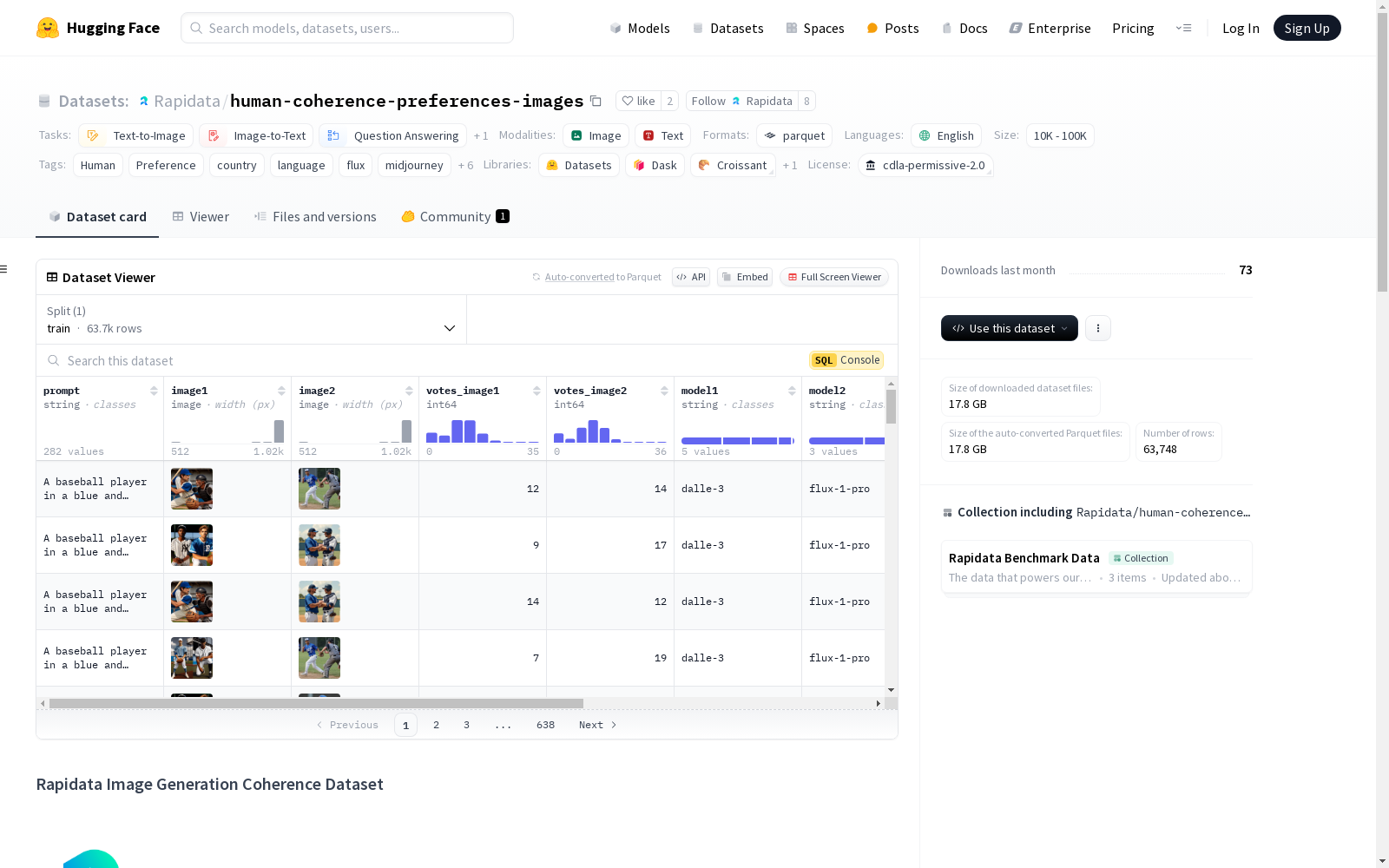
构建方式
该数据集通过Rapidata Python API在短短四天内收集而成,利用了Rapidata平台的创新性数据标注技术。参与者被展示两张图像,并被要求选择哪一张在细节上显得更自然、少有视觉错误或瑕疵。数据集的构建不仅依赖于大规模的人类投票,还涵盖了来自全球各地的多样化参与者,确保了数据的地理和文化代表性。此外,数据集的构建过程中使用了精心设计的提示(prompts),以测试图像生成模型的不同方面,从而确保了数据集的全面性和深度。
特点
该数据集的显著特点在于其庞大的规模和全球化的参与度。数据集包含了超过120万次的人类一致性投票,这些投票在不到100小时内完成,展示了Rapidata平台在数据收集速度上的优势。此外,数据集涵盖了多种领先的图像生成模型,如Imagen-3、Flux-1.1、Dalle-3等,为模型间的比较提供了丰富的资源。数据集的提示设计也极具多样性,能够有效测试模型在不同情境下的表现。
使用方法
该数据集适用于多种应用场景,包括但不限于新图像生成模型的基准测试、生成模型评估指标的开发、全球范围内AI生成图像偏好的理解、图像生成模型的训练与微调,以及跨文化美学偏好的研究。用户可以通过Rapidata Python API轻松访问和分析数据,利用这些数据进行模型优化和研究。数据集的结构化设计使得用户能够方便地提取和分析不同模型在特定提示下的表现,从而推动图像生成技术的进一步发展。
背景与挑战
背景概述
在文本到图像生成模型的研究领域,human-coherence-preferences-images数据集的诞生标志着对模型生成图像质量评估的重大进步。该数据集由Rapidata公司主导,于短时间内(约4天)通过其高效的Python API收集了超过120万条人类对图像一致性的投票数据。这一数据集不仅涵盖了全球范围内的参与者,还涉及多种先进的图像生成模型,如Imagen、Flux、Dalle和Midjourney等。其核心研究问题聚焦于如何通过大规模的人类反馈来评估和提升生成图像的自然度和一致性,从而为图像生成模型的性能评估提供了新的基准。
当前挑战
该数据集在构建过程中面临了多重挑战。首先,如何在短时间内收集如此大规模的人类反馈数据,确保数据的时效性和代表性,是技术上的重大挑战。其次,不同文化背景下的审美偏好差异可能影响投票结果的一致性,如何平衡这些差异并确保评估的公正性也是一个难题。此外,数据集的多样性要求涵盖广泛的提示(prompts)和模型对比,这增加了数据收集和处理的复杂性。最后,如何在保持数据质量的同时,实现高效的全球数据收集和处理,也是该数据集面临的关键挑战。
常用场景
经典使用场景
该数据集的经典使用场景主要集中在图像生成模型的评估与优化上。通过展示两幅由不同模型生成的图像,并收集人类对这些图像的连贯性偏好,研究者能够量化和比较不同生成模型在视觉连贯性方面的表现。这种基于人类感知的评估方法,为图像生成模型的性能提供了更为直观的衡量标准,特别是在处理复杂的视觉错误和图像不自然性方面。
实际应用
在实际应用中,该数据集为图像生成模型的开发和优化提供了宝贵的资源。例如,在广告设计、游戏开发和虚拟现实等领域,图像生成模型的连贯性和自然性直接影响到用户体验。通过利用该数据集进行模型训练和微调,开发者能够生成更符合人类视觉偏好的图像,从而提升产品的市场竞争力和用户满意度。
衍生相关工作
该数据集的发布催生了一系列相关研究工作,特别是在图像生成模型的评估和优化领域。例如,研究者利用该数据集开发了新的评估指标,以更好地量化图像生成模型的连贯性。此外,该数据集还被用于训练和验证新的图像生成模型,推动了生成对抗网络(GANs)和扩散模型(Diffusion Models)等技术的进一步发展。这些衍生工作不仅丰富了图像生成领域的研究内容,也为实际应用提供了更为强大的技术支持。
以上内容由遇见数据集搜集并总结生成


