DDL
收藏arXiv2025-06-29 更新2025-07-02 收录
下载链接:
https://deepfake-workshopijcai2025.github.io/main/index.html
下载链接
链接失效反馈官方服务:
资源简介:
DDL数据集是一个包含超过180万伪造样本的大规模深度伪造检测和定位数据集,涵盖了75种不同的深度伪造方法。该数据集的设计包括四个关键创新点:多样化的伪造场景、全面的深度伪造方法、不同的操作模式以及精细的伪造注释。DDL数据集不仅为复杂的真实世界伪造提供了一个更具挑战性的基准,还为构建下一代深度伪造检测、定位和可解释性方法提供了重要支持。
The DDL Dataset is a large-scale deepfake detection and localization dataset containing over 1.8 million forged samples, covering 75 distinct deepfake generation methods. The design of this dataset features four key innovations: diverse forgery scenarios, comprehensive coverage of deepfake techniques, varied operating modes, and precise forgery annotations. The DDL Dataset not only provides a more challenging benchmark for complex real-world forgeries but also offers critical support for developing next-generation deepfake detection, localization, and interpretability methods.
提供机构:
AntGroup, Institute of Automation, Chinese Academy of Sciences, Hefei University of Technology, Anhui Province Key Laboratory of Digital Security, A⋆STAR Centre for Frontier AI Research
创建时间:
2025-06-29
搜集汇总
数据集介绍
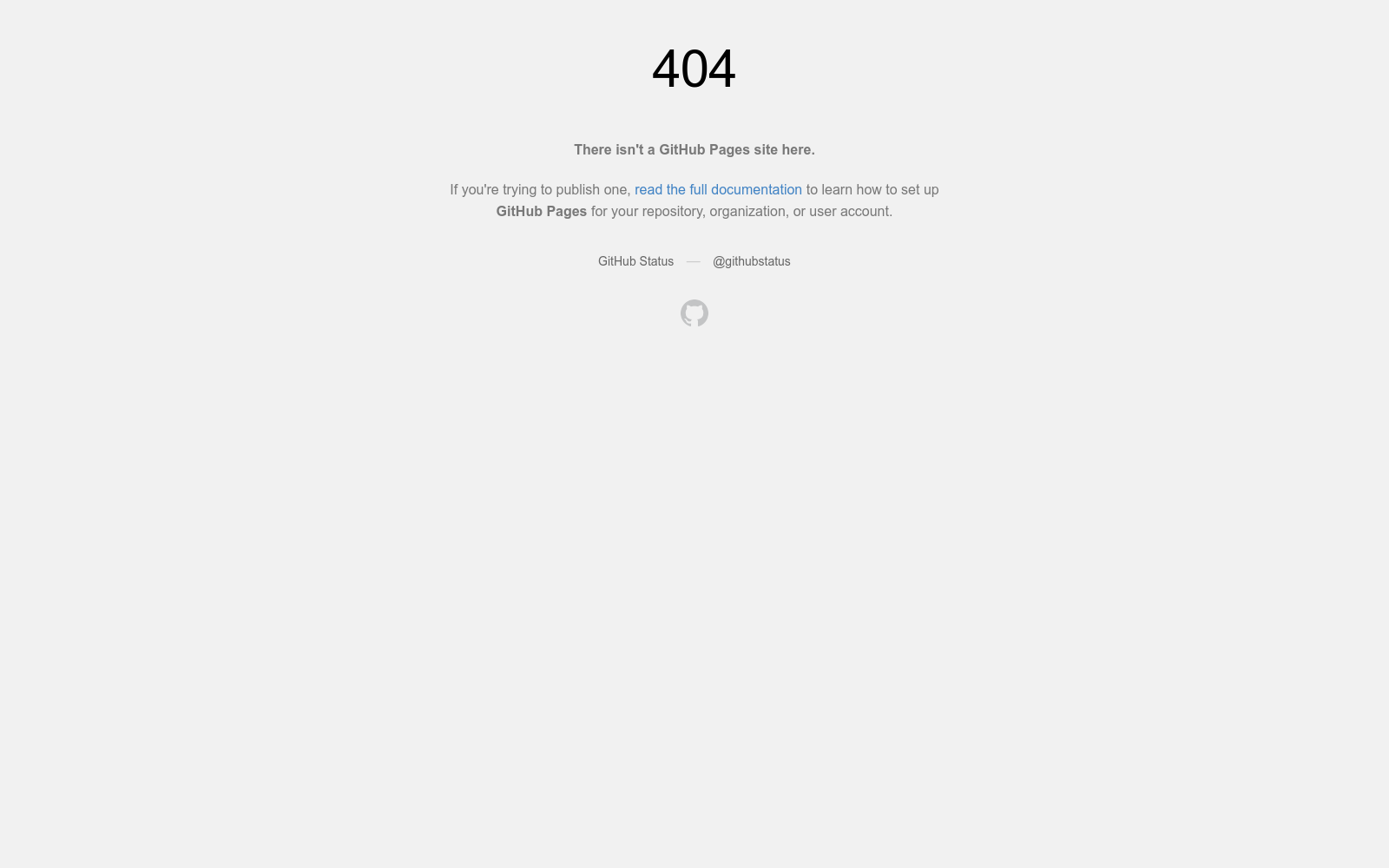
构建方式
在人工智能生成内容(AIGC)技术迅猛发展的背景下,DDL数据集的构建旨在解决现有深度伪造检测数据集的局限性。该数据集通过整合14个真实面部数据集作为原始数据源,采用多样化的伪造生成方法,包括40种图像深度伪造技术、26种视频深度伪造技术和9种音频深度伪造技术。在单脸和多脸场景中,分别采用Dlib模型和MTCNN进行面部区域提取和标记,并通过U-Net分割模型生成精细的伪造区域掩码。音频伪造部分则通过语音识别和文本到语音合成技术实现。整个过程确保了数据集的多样性和真实性。
特点
DDL数据集以其多样性和全面性脱颖而出,涵盖了单脸图像、多脸图像以及联合音频-视觉伪造内容,模拟了复杂的真实世界伪造场景。数据集包含超过180万伪造样本,覆盖75种先进的深度伪造技术,包括GANs、扩散模型、VAEs、AR模型等。此外,DDL首次引入了混合伪造形式和异步时间伪造,进一步增加了数据集的复杂性和真实性。精细的伪造注释,包括空间伪造区域掩码和时间伪造段标签,为伪造定位任务提供了重要支持。
使用方法
DDL数据集的使用方法主要围绕深度伪造检测和定位任务展开。对于图像模态数据,研究者可以利用提供的空间伪造区域掩码进行局部伪造检测和解释性分析。对于音频-视觉模态数据,时间伪造段标签可用于时间定位任务。数据集分为图像单模态子集(DDL-I)和音频-视觉多模态子集(DDL-AV),分别适用于不同的研究需求。研究者可以通过数据集的官方网站获取详细的样本信息和注释,从而进行模型训练和评估。该数据集为开发下一代深度伪造检测、定位和解释性方法提供了重要支持。
背景与挑战
背景概述
DDL数据集由AntGroup、中国科学院自动化研究所等机构的研究团队于2025年提出,旨在解决深度伪造内容检测与定位中的关键挑战。随着AIGC技术的快速发展,恶意深度伪造内容的滥用问题日益严重,亟需开发可靠的检测方法。现有深度伪造检测模型虽然在检测指标上表现优异,但大多仅提供简单的二分类结果,缺乏可解释性。DDL数据集包含超过180万伪造样本,涵盖75种深度伪造方法,通过多样化的伪造场景、全面的深度伪造方法、多变的操作模式和细粒度的伪造注释,为复杂现实场景中的深度伪造检测与定位提供了重要支持。
当前挑战
DDL数据集面临的挑战主要体现在两个方面:领域问题挑战和构建过程挑战。在领域问题方面,深度伪造检测需要解决复杂现实场景中的多样化伪造类型,包括单脸、多脸以及音视频联合伪造,同时要求模型不仅能够检测伪造内容,还能准确定位伪造区域,提高结果的可解释性。在构建过程中,研究团队需要克服大规模数据采集与标注的困难,确保覆盖广泛的伪造技术和操作模式,同时保持数据的高质量和多样性。此外,音视频异步伪造等新型伪造形式的引入,进一步增加了数据集的复杂性和构建难度。
常用场景
经典使用场景
在数字取证和多媒体安全领域,DDL数据集被广泛应用于深度伪造检测与定位任务。该数据集通过涵盖单脸图像、多脸图像及联合音视频伪造等多样化伪造场景,为研究者提供了复杂真实世界伪造内容的模拟环境。其1.8M伪造样本和75种深度伪造技术的规模,使得该数据集成为评估模型在跨模态、跨技术场景下泛化能力的黄金标准。
解决学术问题
DDL数据集有效解决了深度伪造检测领域长期存在的三大核心问题:模型可解释性不足、跨技术泛化能力弱以及细粒度定位缺失。通过提供空间伪造区域掩码和时间伪造片段标签,该数据集首次实现了对伪造内容的像素级定位分析,为构建可解释的检测框架奠定了数据基础。同时,其覆盖的40种图像伪造方法、26种视频伪造方法和9种音频伪造方法,显著提升了模型应对新兴伪造技术的鲁棒性。
衍生相关工作
基于DDL数据集已衍生出多个标志性研究:1)Miao等人提出的多光谱类中心网络实现了91.2%的跨技术检测准确率;2)Yan团队开发的UCF框架利用该数据集验证了通用深度伪造特征提取理论;3)Kong等学者构建的Detect-and-Locate系统首次实现像素级伪造解释。这些工作共同推动了可解释深度伪造检测从二分类向细粒度分析的技术演进。
以上内容由遇见数据集搜集并总结生成


