garrying/VMD-D
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/garrying/VMD-D
下载链接
链接失效反馈官方服务:
资源简介:
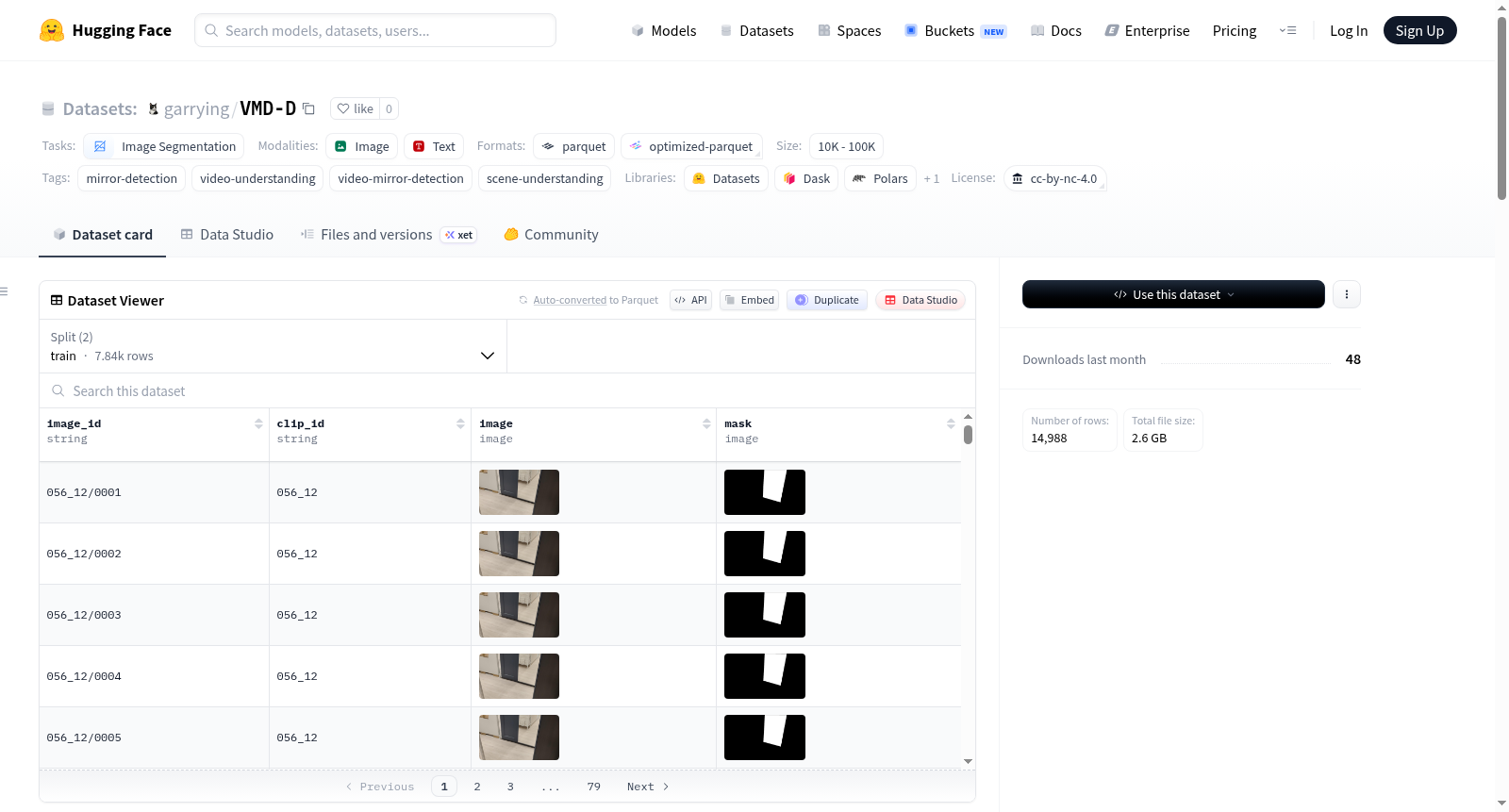
VMD-D(视频镜面检测数据集)是第一个用于视频镜面检测的大规模数据集,包含14,987张图像帧,来自269个视频,每帧都有手动标注的二进制镜面掩码。视频被分割成剪辑,每个剪辑是一个独立的序列段。数据集分为训练集和测试集,训练集包含144个剪辑和7,836帧,测试集包含127个剪辑和7,151帧。每个样本包含四个列:image_id、clip_id、image和mask。数据集的原始磁盘布局和加载方式也在README中详细描述。
VMD-D (Video Mirror Detection Dataset) is the first large-scale dataset for Video Mirror Detection, containing 14,987 image frames from 269 videos with corresponding manually annotated binary mirror masks. Videos are split into clips, and each clip is an independent sequence segment. The dataset is divided into training and test sets, with the training set containing 144 clips and 7,836 frames, and the test set containing 127 clips and 7,151 frames. Each sample has four columns: image_id, clip_id, image, and mask. The original on-disk layout and loading methods are also described in detail in the README.
提供机构:
garrying
搜集汇总
数据集介绍
构建方式
VMD-D(Video Mirror Detection Dataset)作为首个面向视频镜面检测的大规模数据集,由269段视频中提取的14,987帧图像构成,每帧均配有手工标注的二值镜面分割掩码。视频被切分为独立的片段,其中训练集包含144个片段共7,836帧,测试集包含127个片段共7,151帧。数据集以片段-帧为组织单元,每个样本包含图像标识符、片段编号、原始视频帧及对应的PNG格式分割掩码,原始文件存储为JPEGImages与SegmentationClassPNG两类目录结构,确保了数据加载与还原的便利性。
特点
VMD-D的核心特点在于其首次系统性地将镜面检测任务从静态图像拓展至视频领域,通过连续帧间的时序对应关系来提升检测鲁棒性。数据集覆盖了多样化的室内外场景与镜面形态,每帧均提供精确的像素级标注。此外,其结构化存储支持高效的帧级加载与片段级检索,而提供的辅助脚本可将HuggingFace格式无损还原为原始目录布局,便于与传统计算机视觉工具链无缝集成。
使用方法
使用VMD-D时可借助HuggingFace的datasets库直接加载,通过单行指令获取训练或测试分片,返回的样本包含图像与掩码对象,支持即时可视化与模型输入。为还原原始文件结构,用户可运行仓库内附的parquet_to_raw.py脚本,指定数据源与输出路径后即可自动重建JPEGImages与SegmentationClassPNG目录,适用于需基于文件路径操作的流水线。数据集采用CC BY-NC 4.0许可,仅限非商业用途。
背景与挑战
背景概述
视频中的镜子检测是计算机视觉领域一项极具挑战性的任务,其核心在于镜面区域与周围环境在视觉上高度相似,使得单张图像中的镜子定位异常困难。为攻克这一难题,Jiaying Lin、Xin Tan与Rynson W. H. Lau等研究人员于2023年CVPR会议上提出了首个大规模视频镜子检测数据集VMD-D。该数据集由269个视频中精心挑选的14,987帧图像及其对应的逐像素二进制掩膜组成,覆盖了丰富的室内外场景与镜子形态。其发布为视频层级的一致性推理与时空对应关系建模提供了关键基准,有力推动了场景理解研究的边界拓展。
当前挑战
VMD-D数据集所面临的核心挑战在于双重层面:在领域问题上,视频镜子检测需同时应对镜面与非镜面区域的类内相似性、镜面反射导致的纹理扭曲以及视频帧间的运动模糊,传统基于单帧的图像分割方法难以捕捉镜面的时序一致性特征。在构建过程中,挑战同样严峻,包括从连续视频中精准裁剪不含过多冗余内容的有效片段、确保掩膜标注在时间上的连续性以避免帧间标签突变,以及处理不同拍摄角度、光照条件下镜子边界的模糊性,这需要标注人员具备高度的专业判断力与耗时的人工校正。
常用场景
经典使用场景
VMD-D数据集专为视频镜像检测任务而设计,其核心应用场景在于从连续视频帧中精准识别并分割出镜面区域。作为该领域首个大规模基准,数据集包含来自269段视频的近15000帧图像,每帧均配有精细的二值掩码标注。研究者可基于此数据集训练深度学习模型,通过探索帧间时空一致性、边缘连续性以及反射内容与背景的差异性模式,实现对动态场景中镜面区域的鲁棒检测。该数据集不仅是视频理解与场景解析领域的重要资源,也为智能监控、增强现实等下游任务提供了关键的数据支撑。
解决学术问题
在VMD-D出现之前,镜面检测多聚焦于静态图像,而视频中的镜子识别面临诸多独特挑战:镜面反射内容随视角与物体移动而动态变化、帧间对应关系复杂、单纯依赖单帧外观线索极易产生误判。VMD-D通过提供多帧序列与精确标注,首次系统性地将视频时序信息引入镜子检测研究。它解决了如何利用帧间双对应(外观对应与反射对应)联合建模镜面区域这一开放学术问题,推动了从静态特征学习向时空联合理解的范式转变,为验证时序一致性约束与跨帧信息传播机制的有效性提供了标准化评估平台。
衍生相关工作
自VMD-D发布以来,围绕其衍生出多项代表性研究工作。原始论文提出的双对应学习框架(Dual Correspondences)通过同时建模帧间外观对应与镜面反射对应,成为视频镜子检测的基线方法论。后续工作在此基础上引入时空注意力机制、光流引导的特征对齐策略,以及基于对比学习的跨帧一致性正则化方法,显著提升了复杂动态场景下的检测精度。这些工作不仅拓展了VMD-D数据集的评估边界,也将视频级空间理解的研究从镜子检测延伸至更广泛的透明物体分割、反射表面解析等方向,形成了以时序对应为核心的相关研究脉络。
以上内容由遇见数据集搜集并总结生成


