coqa-multilingual
收藏Hugging Face2026-03-09 更新2026-03-10 收录
下载链接:
https://huggingface.co/datasets/ellamind/coqa-multilingual
下载链接
链接失效反馈官方服务:
资源简介:
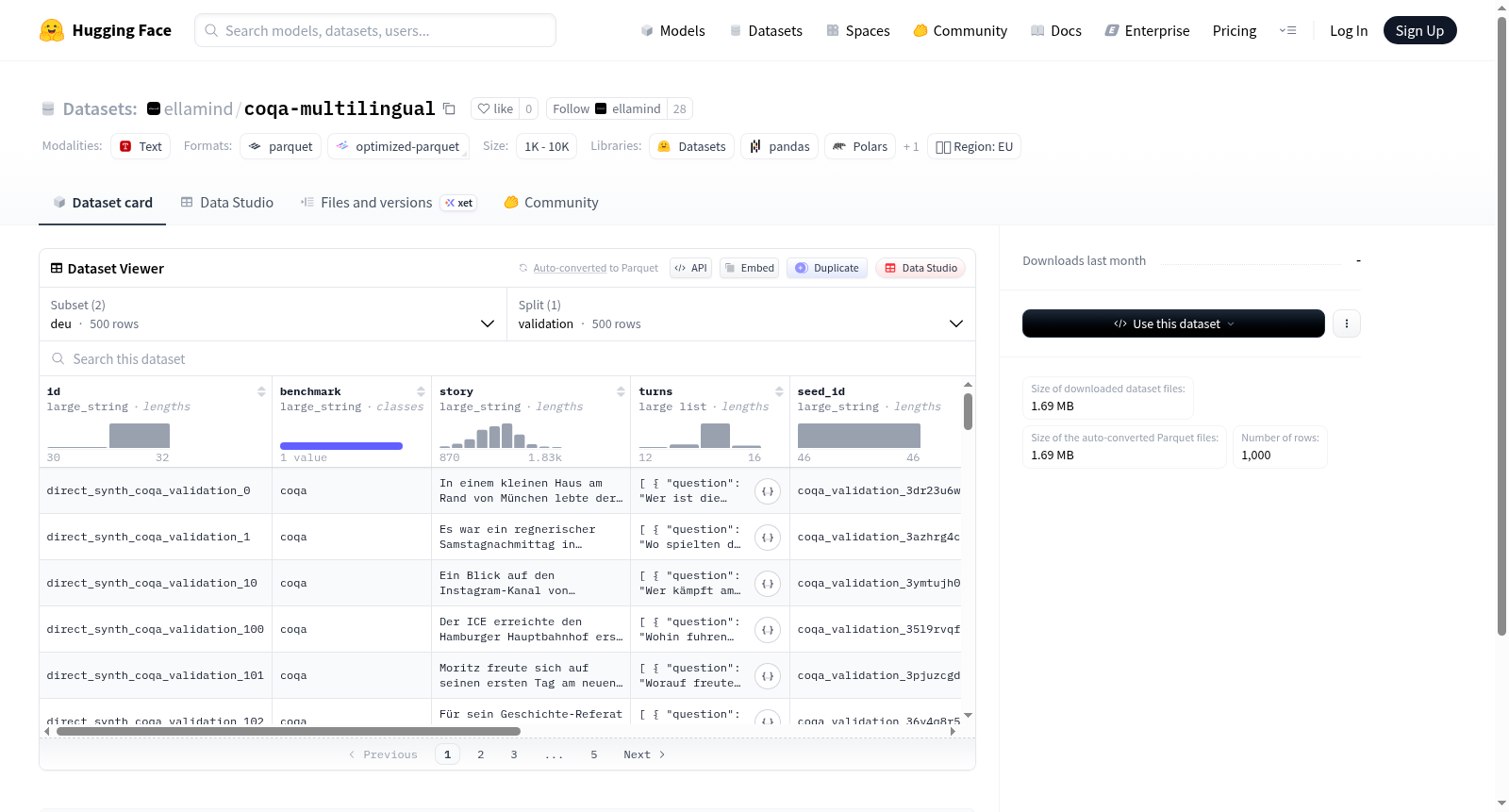
该数据集包含德语(deu)和法语(fra)两种配置,每个配置包含500个验证集样本。数据结构包含以下核心字段:唯一标识符(id)、基准名称(benchmark)、故事文本(story)、多轮对话数据(turns,内含问题-回答对)、种子ID(seed_id)、推理类型(reasoning_type)、综合注释(synthesis_notes)、审核标记(flag_for_review)及审核原因(review_reason)。数据集采用大型字符串(large_string)和布尔值(bool)数据类型存储,其中turns字段为大型列表结构,包含question和answer两个子字段。数据规模方面,德语配置下载大小861KB,存储大小1.47MB;法语配置下载大小832KB,存储大小1.44MB。从字段设计推断,该数据集可能用于多语言问答系统或推理能力评估任务。
提供机构:
ellamind
创建时间:
2026-03-09
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,多语言对话理解任务对数据资源提出了更高要求。CoQA-Multilingual数据集基于原始CoQA英语对话数据集,通过专业人工翻译与本地化适配,构建了德语和法语两个语言版本。每个版本包含500个验证集样本,每个样本由一篇故事文本及围绕其展开的多轮问答组成,翻译过程注重保留原文的语义连贯性与文化语境,确保跨语言评估的有效性。
使用方法
使用该数据集时,研究者可通过HuggingFace平台直接加载德语或法语配置,获取验证集进行模型评估。数据以结构化字段呈现,包括故事文本、问答轮次列表及各类元信息,便于构建对话状态跟踪或问答生成任务。典型应用包括多语言对话模型的零样本或跨语言迁移学习评估,也可用于分析不同语言间推理模式的一致性,推动语言无关的对话理解技术发展。
背景与挑战
背景概述
CoQA-Multilingual数据集诞生于对话式问答研究领域,旨在扩展原始CoQA(Conversational Question Answering)数据集的跨语言应用能力。该数据集由斯坦福大学的研究团队于2019年构建,核心研究问题聚焦于多语言环境下的对话理解与推理,通过提供德语(deu)和法语(fra)等语言版本的对话问答对,推动自然语言处理模型在非英语语境中的泛化性能。其影响力不仅体现在机器阅读理解任务的评估上,更为跨语言对话系统的开发奠定了重要基础,促进了全球范围内智能助手与教育技术应用的进步。
当前挑战
CoQA-Multilingual数据集所解决的领域挑战在于多语言对话问答的复杂性,包括跨语言上下文依赖、文化特定表达的理解以及对话连贯性的维持。构建过程中面临的挑战涉及高质量多语言数据的收集与标注,需要确保翻译的准确性与对话逻辑的一致性,同时克服语言资源不均衡带来的数据偏差问题。此外,数据集的扩展还需处理不同语言语法结构与语义表达的差异,这对标注者的语言专业性与领域知识提出了较高要求。
常用场景
解决学术问题
多语言对话系统研究中,数据稀缺与语言差异常阻碍模型的泛化性能。CoQA-Multilingual通过提供高质量的多语言对话标注数据,有效缓解了非英语语言资源的匮乏问题。该数据集助力解决跨语言迁移学习、低资源语言理解以及对话状态跟踪等学术挑战,为构建公平、包容的多语言人工智能系统奠定了数据基础,推动了自然语言处理领域的全球化发展。
实际应用
在实际应用层面,CoQA-Multilingual数据集为智能客服、教育辅助工具及跨语言信息检索系统提供了关键的训练与评估资源。基于该数据集开发的模型能够支持多语言场景下的自然对话,例如帮助用户以母语获取文档信息、辅助语言学习者进行互动练习,或在国际化企业中实现自动化多语言客户支持,显著提升了人机交互的便捷性与覆盖范围。
数据集最近研究
最新研究方向
在对话式问答领域,多语言模型的跨语言迁移能力正成为研究焦点。coqa-multilingual数据集通过提供德语和法语等语言的对话上下文与问答对,为探索模型在低资源语言环境下的泛化性能提供了关键基准。前沿研究围绕零样本或少样本学习策略展开,旨在提升模型无需大量标注数据即可理解复杂对话逻辑的能力。这一方向与当前多语言人工智能应用的热潮紧密相连,尤其在全球化服务与内容本地化需求激增的背景下,推动着更公平、包容的语言技术发展,对打破语言壁垒具有深远意义。
以上内容由遇见数据集搜集并总结生成


