Jianshu001/arabic-daily-v6-batch01-5k
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/Jianshu001/arabic-daily-v6-batch01-5k
下载链接
链接失效反馈官方服务:
资源简介:
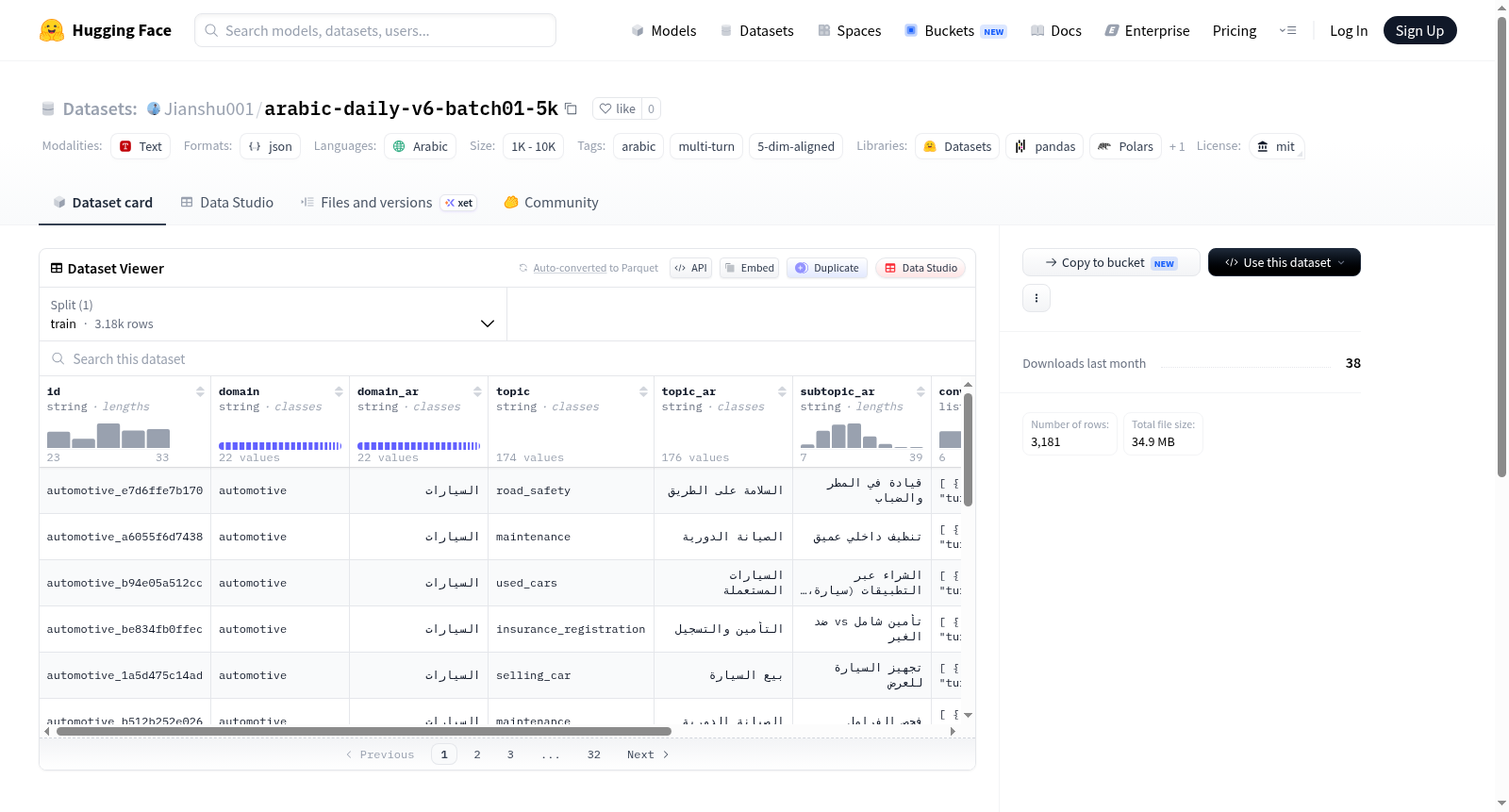
v6 batch-01是一个包含5000条记录的阿拉伯语多轮对话数据集。数据集通过生成(使用gpt-4o-mini用户和Gemma-4-31B助手)、清理和5个维度的评估(自然性、有用性、多轮连贯性、领域适应性和安全性)流程创建。数据集涵盖了22个领域和1056个子主题,移除了健康与健康领域,并新增了8个新领域:房地产与住房、娱乐媒体、汽车、家庭装修、法律行政、健身运动、宠物动物和活动庆典。
v6 batch-01 is a 5000-record Arabic multi-turn dataset. The pipeline involves generation (using gpt-4o-mini user + Gemma-4-31B assistant), thinking cleanup, basic cleanup, and 5-dimension judging (naturalness, usefulness, multi-turn coherence, domain fit, and safety & boundedness). The dataset covers 22 domains and 1056 subtopics, with health_wellness removed and 8 new domains added: real_estate_housing, entertainment_media, automotive, home_renovation, legal_admin, fitness_sports, pets_animals, events_celebrations.
提供机构:
Jianshu001
搜集汇总
数据集介绍
构建方式
arabic-daily-v6-batch01-5k数据集源自一套精细化的流水线生成流程。构建过程以GPT-4o-mini生成用户提问,辅以Gemma-4-31B模型扮演助手角色,构建多轮阿拉伯语对话。之后依次执行思考清理、基础清理、五维评判及正则审计环节,确保每条数据均通过自然性、有用性、多轮连贯性、域适配性及安全边界五项核心维度的严格筛选。该流程将自动生成与人工校验巧妙融合,保障了数据质量与领域覆盖的一致性。
特点
该数据集的一大亮点在于其多维对齐的质量控制体系。每条记录均经过五项核心指标的独立评测,覆盖了从对话自然流畅到内容安全性在内的全面范畴。在领域分布上,数据集囊括22个一级领域与1056个细分子主题,新增了房地产、娱乐媒体、汽车、家装、法律行政、健身运动、宠物动物及活动庆典八个热门领域,同时移除了健康养生类别,体现了面向日常生活场景的务实导向。
使用方法
该数据集适用于阿拉伯语多轮对话系统的训练与评估,尤其适宜需要高自然度与安全边界控制的场景。用户可直接通过HuggingFace加载数据集,并依据5维评分灵活过滤子集用于下游微调或基准测试。建议在训练前对域标签进行适配,或将其作为高质量阿拉伯语对话的起点数据集,结合自身任务进行对话起始与延续能力的强化学习。
背景与挑战
背景概述
该数据集名为 arabic-daily-v6-batch01-5k,是一个面向阿拉伯语的多轮对话数据集,创建于2024年,由开源社区与多家研究机构合作开发,核心研究问题在于提升大语言模型在阿拉伯语场景下的多轮对话质量与安全性。该数据集通过生成(使用GPT-4o-mini作为用户、Gemma-4-31B作为助手)、清理、多维度评判与正则审计的流水线构建,涵盖22个领域和1056个子主题,新增房地产、娱乐媒体、汽车等8个领域,弥补了阿拉伯语高质量多轮对话数据的稀缺性。其对相关领域的影响力体现在为阿拉伯语自然语言处理提供了标准化、多维度对齐的基准数据,推动了低资源语言对话系统的研究与应用。
当前挑战
数据集所解决的领域问题包括:阿拉伯语多轮对话中普遍存在回答不自然、无用、缺乏连贯性或偏离主题等现象,以及敏感领域(如健康)的安全边界难以控制。构建过程中面临的挑战则涵盖:如何确保生成数据在5个关键维度(自然性、有用性、多轮连贯性、领域适配性、安全边界)上均达到高标准;如何在22个域名及1056个子主题上保持内容多样性且避免重复;如何处理大规模清洗与自动评判的准确性,确保每条记录通过严格的5维对齐流水线;如何移除特定领域(如健康)并确保新增领域(如房地产、法律)的数据覆盖度不降低;以及如何通过正则审计消除格式与语法错误,最终产出5000条高质量样本。
常用场景
经典使用场景
在阿拉伯语自然语言处理领域,该数据集作为高质量多轮对话语料库,被广泛用于训练和评估阿拉伯语对话系统的核心能力。其涵盖22个领域、1056个子主题的精细分类,使其成为构建跨领域对话代理的基准数据集。研究者常利用其5维对齐标注(自然性、有用性、多轮连贯性、领域契合度、安全有界性)来检验模型在真实对话场景中的表现,特别是在沙特阿拉伯、埃及等区域阿拉伯语变体的对话生成任务中,该数据集提供了标准化的训练与测试范本。
解决学术问题
该数据集系统性地解决了阿拉伯语多轮对话研究中长期存在的标注维度单一与领域覆盖不足的困境。通过引入五维对齐评价体系,为学术研究提供了细粒度的对话质量评估框架,使得研究者能够精准定位模型在自然性、有用性或安全边界等方面的薄弱环节。其严格过滤健康敏感领域并新增房地产、法律行政等8个领域的策略,有效缓解了低资源领域对话数据的稀缺问题,支撑了跨领域对话生成、对话策略学习等前沿课题的量化研究。
衍生相关工作
该数据集衍生出了多项经典工作,包括基于其五维标注体系开发的阿拉伯语对话质量自动评估模型,以及利用其多轮连贯性特征训练的上下文感知响应排序器。研究者还基于其领域分类设计出动态主题迁移框架,使对话系统能在22个领域间无缝切换而保持语义一致性。这些工作进一步推动了阿拉伯语对话预训练模型(如AraDialGPT)的迭代,并催生了针对低资源方言的跨域数据增强方法论。
以上内容由遇见数据集搜集并总结生成


