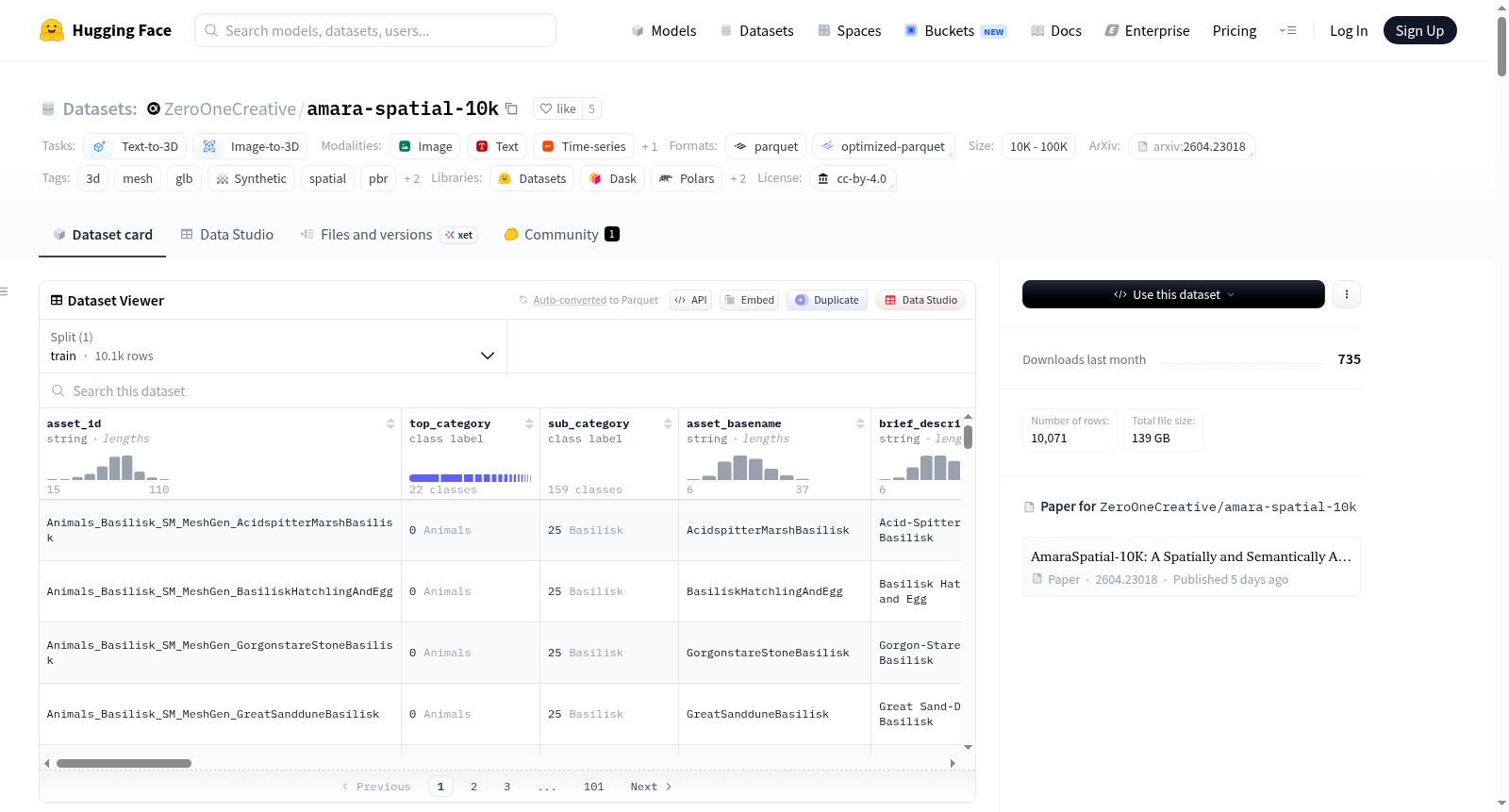
amara-spatial-10k
收藏Hugging Face2026-04-28 更新2026-04-29 收录
下载链接:
https://huggingface.co/datasets/ZeroOneCreative/amara-spatial-10k
下载链接
链接失效反馈官方服务:
资源简介:
AmaraSpatial-10K 是一个专为空间计算和具身 AI 设计的语义锚定、度量尺度的 3D 数据集,包含 10,071 个 AI 生成的 3D 网格,涵盖 65 个类别。每个资产均经过度量缩放、语义锚定、PBR 准备,并附有丰富的多模态元数据。数据集旨在解决生成 3D 资产在游戏引擎、机器人模拟器和 AR/VR 管道中零样本部署时的空间对齐问题。数据集包含种子图像、主 GLB 网格、碰撞 GLB、五个相机渲染和丰富的元数据,适用于 LLM 驱动的场景组合、具身 AI 和机器人模拟器、文本到 3D 训练与评估、检索系统和游戏引擎原型设计。数据集采用 CC BY 4.0 许可发布。
AmaraSpatial-10K is a semantically anchored, metrically scaled 3D dataset designed for spatial computing and embodied AI, containing 10,071 AI-generated 3D meshes across 65 categories. Each asset is metrically scaled, semantically anchored, PBR-ready, and comes with rich multimodal metadata. The dataset aims to address the spatial alignment challenges of deploying generated 3D assets in game engines, robotics simulators, and AR/VR pipelines with zero-shot deployment. It includes seed images, primary GLB meshes, collision GLBs, five camera renders, and extensive metadata, making it suitable for LLM-driven scene composition, embodied AI and robotics simulators, text-to-3D training and evaluation, retrieval systems, and game engine prototyping. The dataset is released under the CC BY 4.0 license.
创建时间:
2026-04-17
原始信息汇总
数据集概述:AmaraSpatial-10K
基本信息
| 项目 | 内容 |
|---|---|
| 数据集名称 | AmaraSpatial-10K |
| 提供方 | Zero One Creative |
| 许可证 | CC BY 4.0 |
| 任务类别 | 文本到3D、图像到3D |
| 数据规模 | 10,071 个3D网格,>130 GB |
| 类别数量 | 65 个顶级类别,476 个子类别 |
核心特色
该数据集同时具备以下四种属性,且据称在同等规模的公开3D数据集中尚无先例:
- 真实世界度量缩放:资产按米为单位的真实物理尺寸缩放,并通过独立的尺度合理性评分进行验证
- 语义原点锚定:原点根据功能上下文放置——地面物品置于底部中心,悬挂物体置于中心,天花板安装物品置于顶部中心
- 生产级PBR与物理:主网格约50K三角形,配有独立的法线/粗糙度贴图(无烘焙光照),并提供配套的凸碰撞外壳(<500三角形)
- 丰富的多模态元数据:每项资产包含多句描述、2D种子图像和五个相机渲染视图,概念密度约为Objaverse标签的18倍
性能对比
基于9个评估类别(5,247项AmaraSpatial资产 vs. 2,856项Objaverse匹配资产)的平均结果:
| 指标 | AmaraSpatial-10K | Objaverse |
|---|---|---|
| 9类平均边界框高度 | 3.89 m | 1,723 m |
| 同类尺度变异系数均值↓ | 3.40 | 9.92 |
| 座椅类合理高度范围[0.6,1.1]m占比↑ | 40.7% | 7.7% |
| 尺度合理性评分均值↑ | 0.68 | — |
| 锚点距语义目标1cm内占比↑ | 79.7% | 4.2% |
| 锚点落在边界框外占比↓ | 5.2% | 35.2% |
| CLIP文本-3D连贯性↑ | 0.238 | 0.203 |
| LLM概念密度(0-5)↑ | 2.62 | 0.14 |
| UV映射占比↑ | 100% | 94% |
数据内容
每项资产包含:
- 种子图像:用于生成网格的文本条件合成图像
- 主GLB网格:度量缩放、语义锚定、UV展开,约10 MB,2K PBR纹理
- 碰撞GLB:用于物理和光线投射的简化凸外壳
- 五个相机渲染:一个透视视图加四个正交视图(前、后、左、右)
- 丰富元数据:28项几何与质量指标、多句描述、结构化类别标签、空间方向数据
仓库结构
metadata/ train-00000-of-00006.parquet ~2.5 GB each, 6 shards train-00001-of-00006.parquet … meshes/ shard-00000.tar ~5 GB each, 21 shards shard-00001.tar each tar contains <asset_id>.glb + <asset_id>.collision.glb … manifest.parquet asset_id → mesh_shard + category labels top_categories.json 65 sorted ClassLabel names sub_categories.json 476 sorted ClassLabel names figures/ README figures
数据模式
元数据Parquet文件中每行包含:
- 身份信息:资产ID、顶级类别、子类别、资产基名
- 提示信息:简短描述、完整描述
- 视觉内容:种子图像、透视图渲染、前/后/左/右渲染
- 网格指针:网格分片、网格路径、碰撞路径
- 几何信息:顶点数、面数、纹理尺寸、边界框、锚点原点、前进轴
- 质量信息:水密百分比、流形边比率、退化三角形数、非流形顶点数、UV坐标、欧拉数
- 碰撞网格:碰撞体积比、碰撞顶点数、碰撞面数
- 衍生几何:表面积、网格体积、边界框体积、平均边长、长宽比
质量检测指标
| 检测项 | 指标 | 对应列名 |
|---|---|---|
| 封闭表面完整性 | 水密三角化百分比 | watertight_percent |
| 流形几何 | 恰好被两个面共享的边比例 | manifold_edge_ratio |
| 退化三角形 | 零面积/共线三角形数 | degenerate_triangle_count |
| 非流形顶点 | 表面自交顶点数 | non_manifold_vertices |
| 拓扑结构 | 欧拉示性数 | euler_number |
| 碰撞拟合 | 碰撞外壳体积/主网格体积比 | collision_volume_ratio |
| UV覆盖 | UV坐标是否存在 | has_uv_coordinates |
预期用途
- LLM驱动的场景合成:正确尺度和锚点可在无需算法调整的情况下减少漂浮物体和穿透
- 具身AI与机器人模拟器:度量尺度和PBR材料缩小仿真到现实的差距
- 文本到3D/图像到3D训练与评估:对齐的文本-图像-网格三元组支持跨模态目标
- 检索系统:多句描述在CLIP和LLM嵌入相似度下显著优于稀疏标签
- 游戏引擎原型开发:生产就绪的GLB文件含碰撞外壳,可在Unreal、Unity或Godot中开箱即用
搜集汇总
数据集介绍
构建方式
AmaraSpatial-10K数据集由Zero One Creative团队通过一套严谨的合成流水线构建而成。首先,利用文本条件生成种子图像;随后,借助图像到三维的生成模型获取原始网格。在此基础上,依次执行空间对齐与度量缩放、UV展开、网格简化以及碰撞外壳简化等后处理步骤。每个资产均经过由大型语言模型估计的物理维度进行度量缩放,并依据语义功能将原点锚定至底部中心、几何中心或顶部中心。最终,每个样本均以GLB格式封装主网格与碰撞网格,并附带多视角渲染图像与丰富的几何质量指标,存储于WebDataset分片中。
使用方法
用户可通过HuggingFace Datasets库便捷地加载元数据Parquet文件进行过滤与浏览,例如筛选特定类别且水密性超过80%的高质量动物网格。训练时,利用WebDataset库流式读取网格分片,实现大规模高效加载。对于需要精确控制的场景,可通过资产ID从HuggingFace Hub下载特定网格文件。完整数据集约130 GB,可使用`hf download`命令进行可中断的并行下载。该数据集可直接用于LLM驱动的场景合成、具身AI模拟、文本/图像到三维模型的训练与评估,以及游戏引擎的原型开发等领域。
背景与挑战
背景概述
随着图像到三维重建技术的蓬勃发展,生成模型虽能产出视觉上合理的网格,但其产物往往在空间上缺乏根基,例如生成的椅子可能高达40米,方位和枢轴点亦显随意。现有的大型三维数据集如ShapeNet缺乏PBR材质,Objaverse存在严重的质量方差与任意尺度问题,而GSO虽尺寸准确却仅含约1000个资产。为弥合这一“空间对齐鸿沟”,Zero One Creative机构于2026年创建了AmaraSpatial-10K数据集。该数据集包含10,071个AI生成的三维网格,跨越65个类别,由Mohammad Sadegh Salehi等研究人员主导开发,旨在为具身智能、空间计算及游戏引擎等领域提供可直接部署的、同时具备公制尺度、语义锚点、PBR材质与丰富语义描述的高质量三维资产。其系统性的评估指标,如尺度合理性评分(SPS),为三维数据集的实用性树立了新标杆。
当前挑战
该数据集所解决的领域核心挑战在于,绝大多数生成式三维资产在空间与语义上的非对齐性,导致其无法在机器人仿真、增强现实等零样本部署场景中直接使用。具体挑战包括:资产尺度任意,如部分数据集内同一类别物体高度跨度从2厘米至100公里;语义锚点缺失,枢轴位置随机浮动,使得场景合成时模型漂浮或穿插。在构建过程中,挑战则体现为:如何为每个类别借助大语言模型精准估计物理尺寸,并建立统一的公制缩放策略;如何通过主成分分析与语义启发式方法,将原始网格旋转至正确方位,并将原点精确放置于功能上下文所指定的位置(如地面物体底部中心),最终还需通过自动几何质量检查(如水密性、流形比例)与尺度合理性评分进行严格筛选,以确保十万级别的资产在空间与语义上的高度一致性。
常用场景
经典使用场景
AmaraSpatial-10K数据集最经典的使用场景在于为具身智能与空间计算领域提供了一组经过语义锚定与公制尺度标定的三维网格资产。该数据集包含超过一万个跨65个类别的AI生成三维模型,每个模型均具备真实的物理尺度、基于功能语义的坐标原点锚定、生产级PBR材质以及丰富的多模态元数据。研究者可以将其直接用于零样本部署于游戏引擎、机器人模拟器和AR/VR管线中,例如在Unreal或Unity中加载带有碰撞凸包的GLB文件进行场景搭建,或在Isaac Sim等机器人仿真环境中利用其公制尺度缩小仿真到现实的迁移鸿沟。
解决学术问题
该数据集精准回应了当前三维生成领域一个长期被忽视的核心矛盾:虽然图像到三维模型生成技术日趋成熟,但输出结果普遍缺乏空间根基——生成的椅子可能高达40米,旋转朝向随意,坐标原点漂浮于质心。AmaraSpatial-10K通过同时赋予每个资产真实的公制尺度、语义化原点锚定、生产级PBR材质和丰富描述,从根本上解决了三维数据仓库在零样本部署时的空间对齐困境。其提出的尺度合理性评分和类别内变异系数等量化指标,为评估和对比不同数据集的空间质量提供了方法论基准,推动了从追求数据体积到追求空间语义对齐的研究范式转变。
实际应用
在实际应用层面,该数据集展现出跨平台、多场景的适配能力。在游戏引擎原型开发中,其生产级GLB文件配备碰撞凸包,可直接拖入Unreal或Godot进行物理交互测试而无需额外处理。在机器人仿真领域,公制尺度和PBR材质使得机械臂抓取策略的仿真训练可以直接迁移到真实环境,显著降低了sim-to-real差距。在增强现实和空间计算场景中,受语义锚定约束的坐标原点确保了虚拟物体与真实环境的贴合度——例如将台灯放置在桌面上时,其底部中心恰好接触桌面表面,避免了穿透或悬浮现象。
数据集最近研究
最新研究方向
当前,三维数据集研究正经历从单纯追求规模向空间与语义对齐的范式转变。AmaraSpatial-10K的出现填补了这一关键空白:它不仅是首个同时具备真实世界度量尺度、语义锚定原点、PBR材质以及丰富多模态元数据的公开三维网格数据集,更通过可量化的空间对齐指标(如尺度合理性分数SPS)为具身智能与空间计算领域树立了新基准。该数据集直接回应了生成式三维模型在零样本部署于游戏引擎、机器人模拟器或AR/VR管线时因非物理尺度与锚点漂浮导致的失效问题。其发布的深层意义在于,它为文本/图像到三维模型的训练与评估提供了可复现、可度量的空间对齐标准,从而实质性地缩小了仿真与现实之间的鸿沟,推动了空间智能从‘视觉合理’向‘物理可用’的关键跨越。
以上内容由遇见数据集搜集并总结生成


