tool-calling-mix
收藏Hugging Face2025-09-03 更新2025-09-04 收录
下载链接:
https://huggingface.co/datasets/younissk/tool-calling-mix
下载链接
链接失效反馈官方服务:
资源简介:
这是一个用于微调语言模型以使用工具的数据集。它通过结合多个高质量的数据源,并包含非工具调用示例,旨在产生能够有效使用工具同时保持通用语言能力模型。
This is a dataset for fine-tuning language models to utilize tools. By integrating multiple high-quality data sources and including non-tool-calling examples, it aims to generate models that can effectively utilize tools while retaining their general language capabilities.
创建时间:
2025-09-03
原始信息汇总
Tool Calling SFT Mix 数据集概述
基本信息
- 许可证:MIT
- 语言:英语(en)
- 任务类别:文本生成、其他
- 规模分类:10K<n<100K
- 配置名称:default
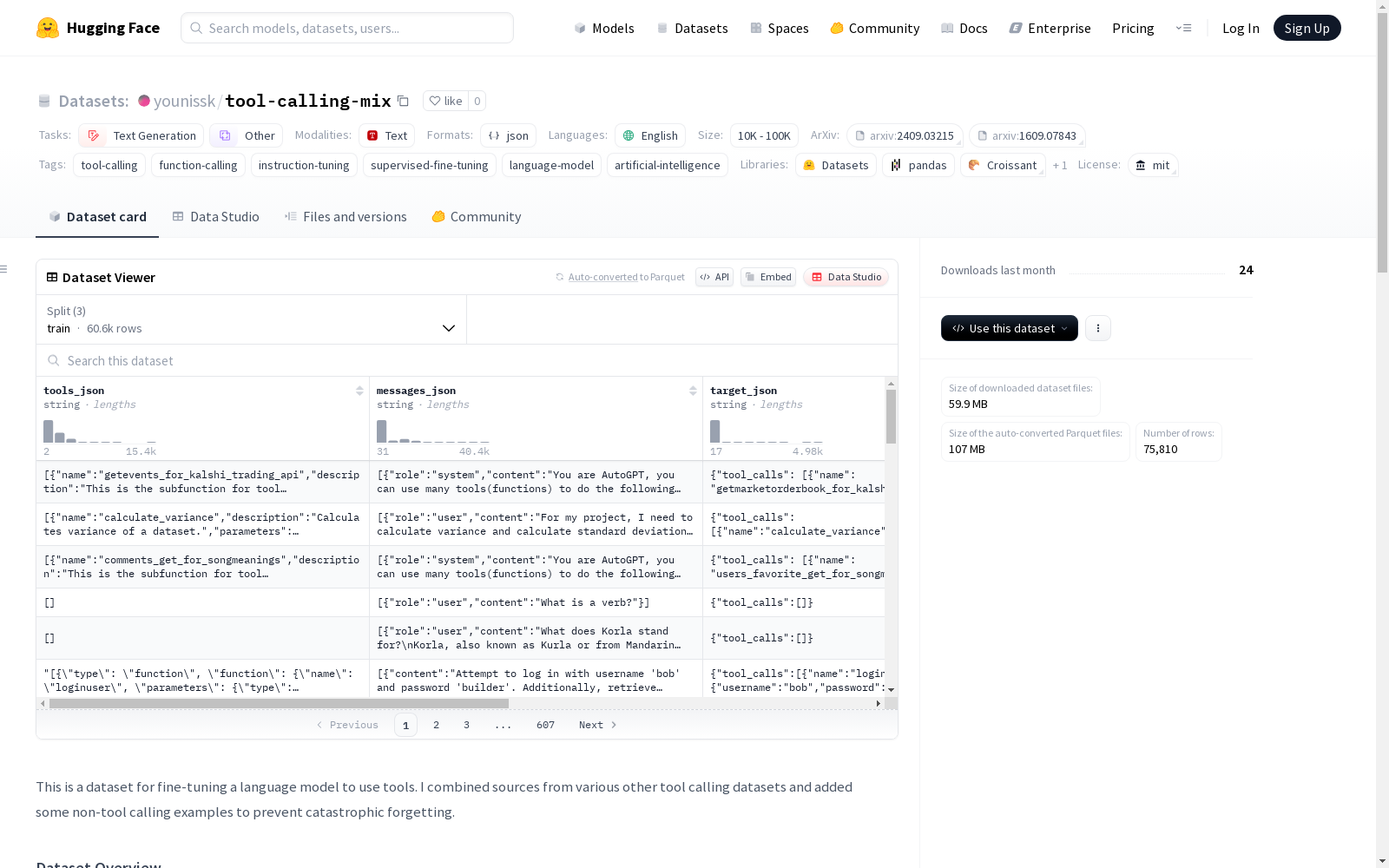
数据内容
特征字段
tools_json:字符串类型messages_json:字符串类型target_json:字符串类型meta_source:字符串类型n_calls:int32类型difficulty:字符串类型valid:布尔类型
数据分割
- 训练集:60,648个样本,291,192,023字节
- 验证集:7,581个样本,36,585,030字节
- 测试集:7,581个样本,36,983,211字节
数据集统计
- 总样本量:75,810个示例(100%有效)
- 工具使用情况:
- 平均每个示例1.34次工具调用
- 简单示例74.5%,并行示例19.8%,多重示例4.0%,无调用示例1.7%
- 单个示例最多24次工具调用
来源分布
- ToolBench Normalized:26.4%
- xLAM60k:26.4%
- OpenFunctions v1:15.2%
- Instruction No-Call (Dolly):10.6%
- WikiText No-Call:10.6%
- Synthetic Parallel:6.6%
- 其他:4.2%
预期用途
- 训练语言模型有效使用工具
- 对现有模型进行工具使用的微调
- 研究工具调用模式和行为
上游来源
- Zhang, J. et al. (2024). xLAM: A Family of Large Action Models to Empower AI Agents. arXiv:2409.03215
- Patil, S. G., Zhang, T., Wang, X., Gonzalez, J. E. (2024). Gorilla: Large Language Model Connected with Massive APIs
- Databricks (2023). databricks-dolly-15k
- Merity, S., Xiong, C., Bradbury, J., Socher, R. (2016). Pointer Sentinel Mixture Models. arXiv:1609.07843
搜集汇总
数据集介绍
构建方式
在工具调用研究领域,数据质量对模型性能具有决定性影响。本数据集通过整合多个权威来源构建而成,包括ToolBench Normalized、xLAM60k和OpenFunctions等核心资源,并创新性地融入了10.6%的非工具调用指令数据以防止灾难性遗忘。所有样本均经过统一的模式转换和JSON字段标准化处理,采用随机种子42进行严格的数据洗牌与采样,确保数据分布的均衡性与一致性。
特点
该数据集展现出显著的多源异构特征,总计包含75,810个有效样本,平均每个样本包含1.34次工具调用。其复杂度分布呈现阶梯式特征,74.5%为简单调用,19.8%涉及并行调用,4.0%为多重调用,更有极端案例达到单样本24次调用。数据来源构成科学,26.4%来自xLAM60k的精细化标注,15.2%采用OpenFunctions的高质量API调用数据,并辅以WikiText文本语料保持语言模型的通用能力。
使用方法
研究人员可通过HuggingFace数据集库直接加载该资源,使用标准接口即可获取训练、验证和测试三个子集。每个样本包含工具定义、对话消息、目标输出和元数据等结构化字段,支持端到端的监督微调训练。该数据集特别适用于工具调用模式的行为学研究、语言模型工具化能力的增强训练,以及多轮工具调用场景的建模实验,为构建下一代工具学习系统提供坚实基础。
背景与挑战
背景概述
在人工智能领域,工具调用能力被视为大型语言模型实现实际应用价值的关键技术。tool-calling-mix数据集由研究机构于2024年创建,旨在解决语言模型在工具使用方面的泛化能力问题。该数据集整合了xLAM60k、OpenFunctions等多个权威数据源,通过精心设计的监督微调框架,使模型既能掌握复杂工具调用模式,又能保持基础语言理解能力。其创新性的多源融合策略为语言智能体研究提供了重要基准,推动了行动模型领域的技术发展。
当前挑战
该数据集主要应对工具调用场景中的语义理解与执行逻辑分离的挑战,包括多轮对话中工具选择的准确性、参数提取的精确性以及异常处理能力。构建过程中面临源数据格式异构性整合难题,需要设计统一的结构化表示方案;同时需平衡工具调用样本与常规语言样本的比例以防止灾难性遗忘。此外,不同工具API的标准化表达与验证机制也构成了显著的技术障碍,需要确保函数调用的语法规范性和语义完整性。
常用场景
经典使用场景
在人工智能工具调用研究领域,该数据集通过整合多源工具调用范例与非工具调用样本,为语言模型的监督微调提供了标准化训练资源。其典型应用体现在模型指令跟随能力的优化过程中,研究者利用该数据集的统一化工具调用范式,训练模型准确解析用户指令并触发相应外部工具API。数据集内包含的并行调用与多重调用样本,有效支撑了复杂工具调用逻辑的建模研究。
衍生相关工作
基于该数据集衍生的经典研究包括工具调用链式推理框架,其中Gorilla项目通过增强API检索精度提升了工具调用的可靠性。xLAM系列研究则利用该数据构建了大规模动作模型家族,实现了跨工具的多任务协调能力。此外,在工具调用安全约束方面,多项研究借助该数据集的验证集开发了工具使用边界控制机制,为实际部署提供了安全性保障方案。
数据集最近研究
最新研究方向
在工具调用与函数执行领域,该数据集正推动大语言模型向多工具协同与复杂推理方向发展。研究者们聚焦于提升模型在动态环境中的工具选择精度与序列执行能力,特别是在处理并行调用与多步骤任务时的表现。近期突破体现在模型能够结合外部API实现实时数据处理与跨域知识整合,这直接关联到AI智能体的自动化决策研究。随着多模态交互需求的增长,该数据集为构建具备现实世界交互能力的语言模型提供了关键训练基础,显著影响了具身智能与工业自动化应用的发展轨迹。
以上内容由遇见数据集搜集并总结生成


