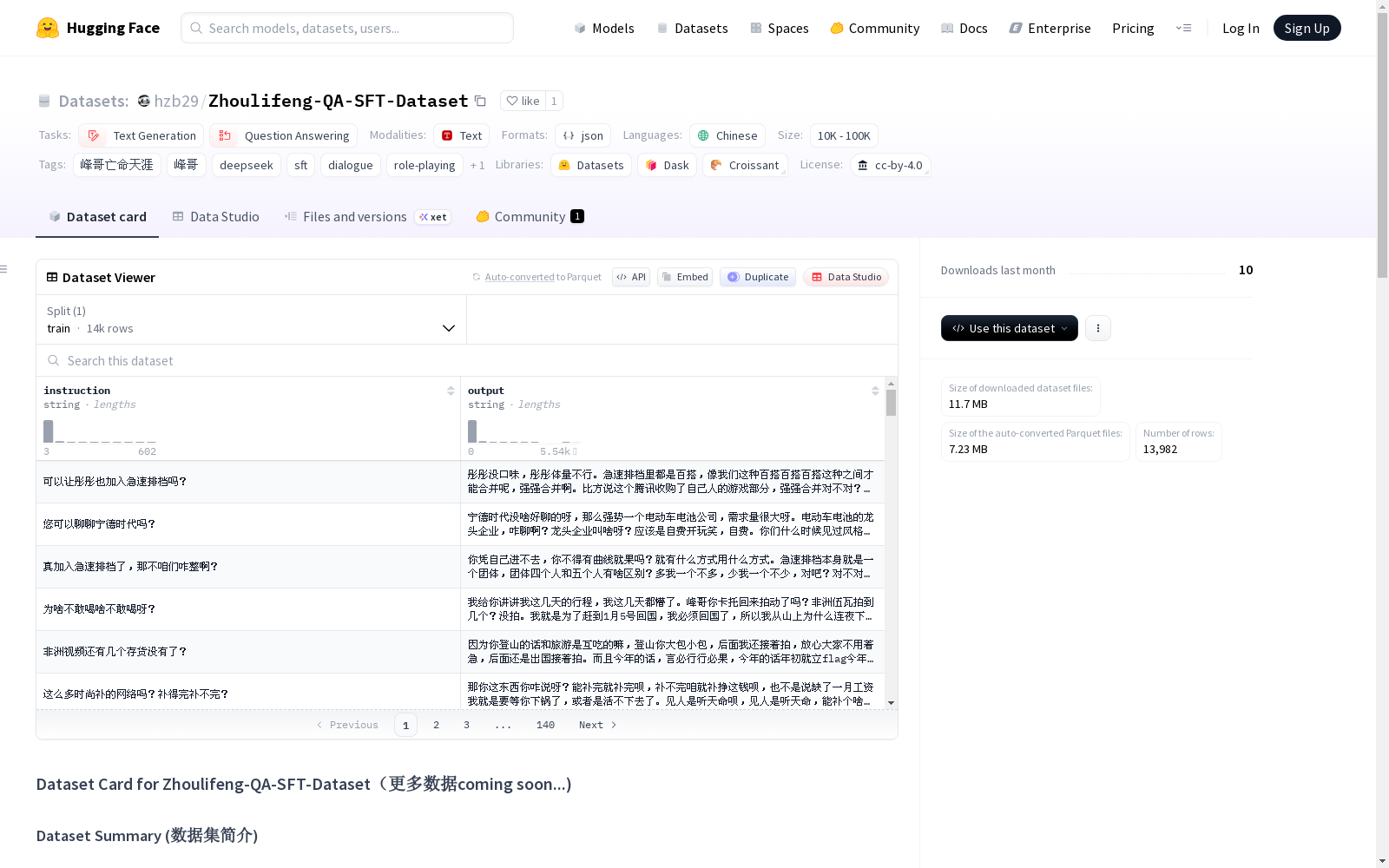
Zhoulifeng-QA-SFT-Dataset
收藏Hugging Face2025-12-10 更新2025-12-11 收录
下载链接:
https://huggingface.co/datasets/hzb29/Zhoulifeng-QA-SFT-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
Zhoulifeng-QA-SFT-Dataset是一个经过精心构造的中文对话SFT(监督微调)数据集。该数据集的内容源自知名户外主播峰哥亡命天涯的直播语音转录文本。利用DeepSeek (V3)对原始的语音转录(ASR)文本进行了深度处理,在清洗噪声的同时,最大程度地保留了峰哥本人的语言风格、幽默感、犀利的社会洞察以及独特的口癖。本数据集旨在帮助开发者训练具有鲜明“峰哥”人格、能够进行高质量闲聊、观点输出和幽默互动的AI模型。
Zhoulifeng-QA-SFT-Dataset is a meticulously constructed Chinese conversational Supervised Fine-Tuning (SFT) dataset. Its content is derived from the live broadcast speech transcripts of well-known outdoor streamer Fengge Wangming Tianya. Raw Automatic Speech Recognition (ASR) transcripts were deeply processed using DeepSeek (V3), which performed noise cleaning while retaining Fengge's original speech style, sense of humor, sharp social insights, and unique speech tics to the greatest extent possible. This dataset is designed to assist developers in training AI models that embody the distinct "Fengge" personality, and are capable of engaging in high-quality casual conversations, expressing viewpoints, and conducting humorous interactions.
创建时间:
2025-12-10
原始信息汇总
Zhoulifeng-QA-SFT-Dataset 数据集概述
数据集基本信息
- 名称:Zhoulifeng-QA-SFT-Dataset
- 许可证:cc-by-4.0
- 任务类别:文本生成、问答
- 语言:中文
- 数据规模:10K<n<100K
- 标签:峰哥亡命天涯、峰哥、deepseek、sft、dialogue、role-playing、humor
数据集简介
Zhoulifeng-QA-SFT-Dataset 是一个经过精心构造的中文对话 SFT(监督微调)数据集。该数据集的内容源自知名户外主播 峰哥亡命天涯 的直播语音转录文本。利用 DeepSeek (V3) 对原始的语音转录(ASR)文本进行了深度处理:在清洗噪声的同时,最大程度地保留了峰哥本人的语言风格、幽默感、犀利的社会洞察以及独特的口癖。本数据集旨在帮助开发者训练具有鲜明“峰哥”人格、能够进行高质量闲聊、观点输出和幽默互动的 AI 模型。
数据来源与处理
- 数据来源:2023-2024年峰哥亡命天涯直播录音 -> Whisper 转录 -> 文本切片。
- 处理模型:DeepSeek V3 (API)。
- 数据格式:标准 Instruction/Output 格式,可直接用于 SFT 训练。
数据构建流程
- 语音转录 (ASR):使用 Whisper Large-v3 模型将峰哥的历史直播视频/音频转换为原始文本(
.txt),源自hzb29/Zhoulifeng-Streaming-Dataset。 - 文本分块 (Chunking):采用滑动窗口机制,将长文本切分为适合上下文窗口的片段,保留语义连贯性。
- DeepSeek 处理:
- 使用
DeepSeek API对文本进行分析。 - 通过精心设计的 Prompt,要求模型识别直播中的问答逻辑。
- 风格锁定:DeepSeek 被指示严格保留原文的口语化表达(如“批个骚的”、“完了”、“这咋整”),仅对无意义的重复和 ASR 错误进行微调,确保生成的 output 原汁原味。
- 使用
- 格式化:导出为标准的 JSON 格式,适配主流 SFT 训练框架。
字段说明
- instruction (
string): 用户提出的问题,或根据直播语境反推的弹幕提问。 - output (
string): 峰哥的回答。保留了原始的语气词、反问句式和独特的逻辑跳跃,具有极强的人格特征。
适用场景
- Role-Playing (角色扮演):训练一个像“峰哥”一样说话的 AI 伴侣或聊天机器人。
- Style Transfer (风格迁移):研究如何将 LLM 的回答从“由于...”的机器风转换为“老铁我跟你讲...”的直播风。
- Chatbot Personality:增强聊天机器人的幽默感和攻击性(非恶意,而是风格上的犀利)。
局限性与偏见
- 口语化严重:数据集中包含大量非标准汉语语法、倒装句和网络俚语。
- 主观性强:所有观点仅代表主播个人在直播时的即兴表达,不代表客观事实,训练后的模型可能会产生带有强烈主观色彩的幻觉。
- 特定语境:部分内容涉及特定的直播梗(如“彤彤”、“水果挺甜”、“急速排档”),非核心粉丝可能难以理解。
引用
如果本数据集对您的研究或项目有帮助,请引用: bibtex @dataset{zhoulifeng_qa_sft_2025, author = {hzb29, FQAJ}, title = {Zhoulifeng-QA-SFT-Dataset}, year = {2025}, publisher = {Hugging Face}, url = {https://huggingface.co/datasets/hzb29/Zhoulifeng-QA-SFT-Dataset} }
免责声明
本数据集仅供学术研究和娱乐用途。生成的内容不代表任何官方立场。
搜集汇总
数据集介绍
构建方式
在中文自然语言处理领域,构建具有鲜明人物风格的数据集对于提升对话模型的拟人化与个性化表达能力至关重要。Zhoulifeng-QA-SFT-Dataset的构建始于对知名户外主播峰哥亡命天涯直播录音的系统性采集,首先运用Whisper Large-v3模型进行高精度语音转录,将原始音频转化为文本形式。随后,通过滑动窗口机制对长文本进行智能分块,确保语义片段的连贯性与完整性。核心处理环节依托DeepSeek V3模型的强大理解与生成能力,在精心设计的提示词引导下,模型被要求严格识别并重构直播场景中的问答逻辑,同时精准锁定并保留主播独特的口语表达、幽默修辞及社会评论风格,仅对转录中的噪声与错误进行最小化修正,最终将处理后的对话对格式化为标准的指令-输出结构,形成可直接用于监督微调的训练数据。
特点
该数据集的核心特征在于其高度风格化与场景真实性。数据内容深度植根于网络直播语境,完整保留了主播标志性的语言习惯,包括特色口癖、反问句式、跳跃性逻辑以及充满市井智慧的幽默表达,使得语料脱离了机械化的书面语体,洋溢着鲜活的生活气息与人格魅力。与此同时,数据集经过严格的质量控制,在去除自动语音识别产生的无意义重复与错误的同时,最大程度维护了原始语料的风格纯度,确保了每一轮对话都承载着鲜明的角色印记。这种对特定人物语言风格的极致还原,为研究语言模型的人格化塑造与风格迁移提供了极具价值的实验素材。
使用方法
针对该数据集的应用,研究者可将其直接整合至主流的监督微调训练流程中。数据集以标准的JSON格式组织,包含清晰的‘instruction’(指令/问题)与‘output’(输出/回答)字段,能够无缝对接各类大语言模型训练框架。其主要应用方向聚焦于角色扮演聊天机器人的开发,通过微调使模型习得数据集蕴含的独特语言风格与幽默感,从而生成具有高度拟人化和娱乐性的对话。此外,该数据集亦适用于自然语言生成领域的风格迁移研究,探索如何将通用模型的表达范式转化为特定人物的口语化、个性化输出,为增强对话系统的情感表现力与用户吸引力提供了实践路径。
背景与挑战
背景概述
在人工智能对话系统领域,赋予模型鲜明的人格特质与风格化表达能力已成为前沿研究方向。Zhoulifeng-QA-SFT-Dataset于2025年由hzb29与FQAJ等研究者构建并发布,其核心研究问题聚焦于如何将特定人物的语言风格、幽默感及社会洞察力迁移至大语言模型中。该数据集源自知名户外主播“峰哥亡命天涯”2023至2024年间的直播语音转录文本,通过DeepSeek-V3模型进行深度处理与风格锁定,旨在为角色扮演与风格迁移任务提供高质量的中文监督微调语料。它的出现推动了个性化对话生成技术的发展,为构建具有独特人格魅力的AI伴侣提供了关键数据支撑。
当前挑战
该数据集致力于解决个性化角色扮演对话生成的领域挑战,其核心在于如何精准捕捉并迁移真人主播高度口语化、充满幽默与犀利评论的独特语言风格,同时避免生成内容陷入无意义的重复或事实性幻觉。在构建过程中,研究者面临多重技术挑战:首先,原始语音转录文本包含大量ASR错误、非标准语法及网络俚语,需在清洗噪声与保留原有人格特征之间取得微妙平衡;其次,通过大语言模型进行风格锁定时,需设计精妙的提示工程以确保输出严格遵循主播的口癖与逻辑跳跃,而不过度平滑或失真;最后,数据中的主观观点与特定直播语境梗可能引入理解壁垒与偏见,对模型的泛化能力与安全性构成考验。
常用场景
经典使用场景
在自然语言处理领域,角色扮演对话系统的构建常需特定风格的语言数据支撑。Zhoulifeng-QA-SFT-Dataset以其源自户外主播峰哥亡命天涯直播转录的独特语料,为训练具备鲜明人格特征的对话模型提供了经典范例。该数据集通过DeepSeek模型深度处理,精准保留了原主播幽默犀利的口语风格与逻辑跳跃,使得研究者能够基于标准指令-输出格式,高效微调大语言模型,实现高度拟人化的闲聊与观点输出交互。
衍生相关工作
围绕该数据集衍生的相关研究,主要集中在个性化对话生成与风格自适应建模方向。已有工作借鉴其数据构建流程,探索如何利用大模型处理原始转录文本以实现风格锁定,为其他领域人物风格数据集的构建提供了方法论参考。同时,基于该数据集训练的模型也在角色扮演AI、幽默响应生成等任务上进行了性能评测与对比,推动了社区对口语化、主观性对话建模技术路径的深入讨论与优化。
数据集最近研究
最新研究方向
在中文对话生成领域,个性化与风格化模型的构建正成为前沿热点。Zhoulifeng-QA-SFT-Dataset以其独特的直播转录文本与深度风格保留处理,为研究者提供了探究特定人格嵌入与风格迁移的珍贵语料。该数据集紧密关联当前大模型在角色扮演与情感交互方面的突破性尝试,其蕴含的鲜明口语特征与幽默逻辑,正推动着对话系统从通用应答向具有人性化特质与情境适应能力的深度演进,对增强AI的社会化表达与用户体验具有显著意义。
以上内容由遇见数据集搜集并总结生成


