MMPR-v1.2
收藏Hugging Face2026-05-15 更新2026-05-16 收录
下载链接:
https://huggingface.co/datasets/mm-eval/MMPR-v1.2
下载链接
链接失效反馈官方服务:
资源简介:
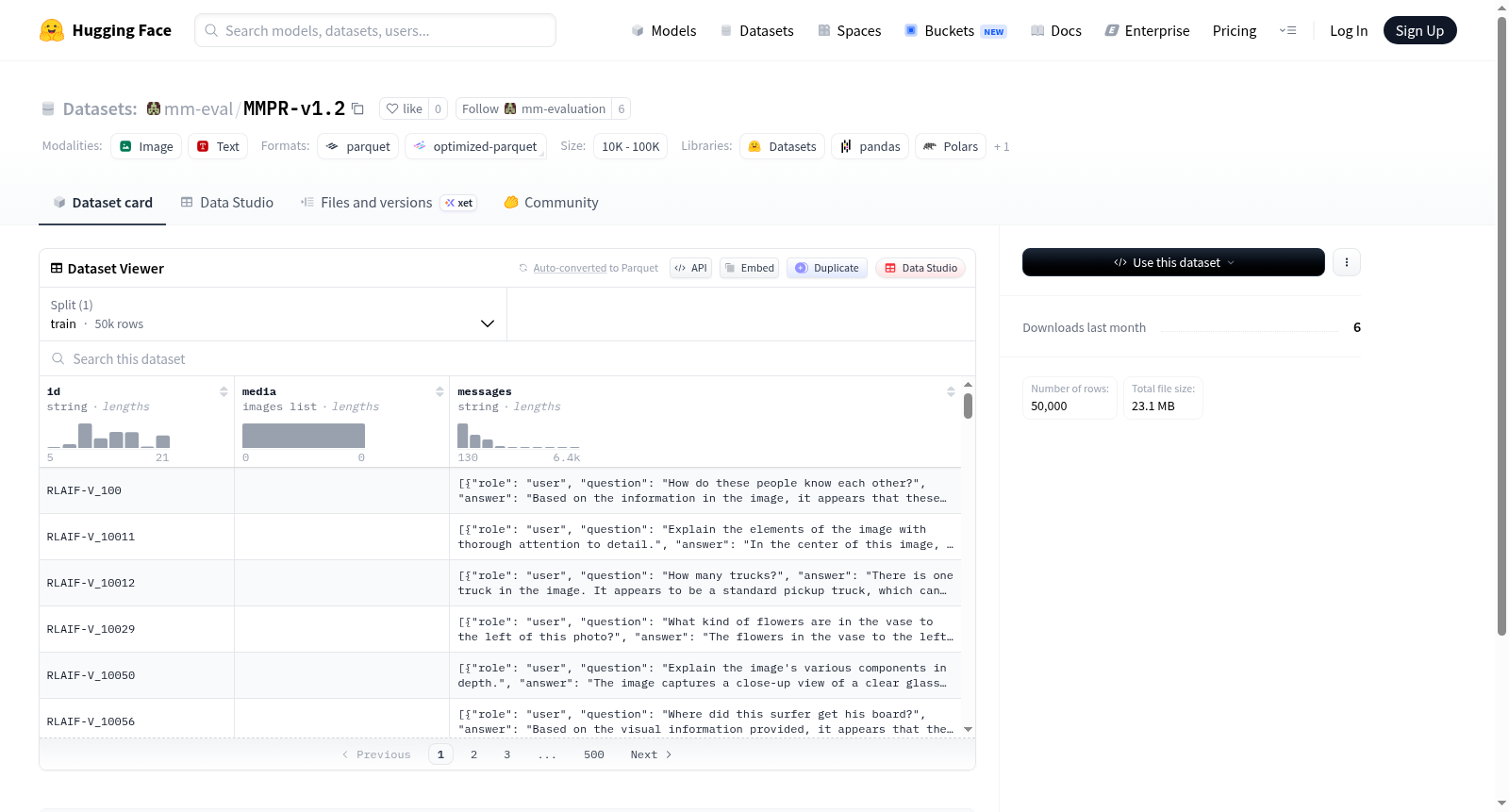
该数据集是一个多模态数据集,包含50,000个训练样本。每个样本由三个主要字段构成:一个唯一的字符串标识符(id)、一个或多个图像(media),以及一段文本消息(messages)。数据集总大小约为53.9MB。从数据结构的组合(图像与文本)来看,该数据集适用于需要结合视觉与语言信息的任务,例如图像描述生成、视觉问答或多模态对话系统。
This dataset is a multimodal dataset containing 50,000 training samples. Each sample consists of three main fields: a unique string identifier (id), one or more images (media), and a text message (messages). The total size of the dataset is approximately 53.9MB. Based on the combination of data structures (images and text), this dataset is suitable for tasks that require integrating visual and linguistic information, such as image caption generation, visual question answering, or multimodal dialogue systems.
创建时间:
2026-05-15
原始信息汇总
根据提供的数据集详情页面 README 文件内容,以下是该数据集的关键信息总结:
数据集名称
MMPR-v1.2
数据集来源
- 托管地址:https://huggingface.co/datasets/mm-eval/MMPR-v1.2
数据集特征
- id:字符串类型,用于标识每个样本。
- media:列表类型,包含图像数据。
- messages:字符串类型,存储消息内容。
数据集划分
- 训练集(train):共包含 50,000 个样本,数据集大小为 53,917,514 字节。
数据文件与配置
- 配置名称:default
- 数据文件路径:
data/train-*,表示训练集数据存储在data/目录下,以train-开头的多个文件中。
数据下载
- 下载大小:23,133,476 字节。
注意:该数据集仅包含训练集(train)划分,无验证集或测试集信息。数据集主要用于多模态评估任务,包含图像与文本消息的配对数据。
搜集汇总
数据集介绍
构建方式
MMPR-v1.2数据集是基于大规模多模态预训练需求构建的高质量图文对数据集。其构建过程以精细的图文匹配为核心,通过自动化的数据清洗与筛选流程,从海量互联网图文资源中提取出50,000个训练样本。每个样本包含唯一的文本标识符、对应的图像列表以及结构化的多轮对话文本,确保了数据在模态对齐与语义一致性上的严谨性。数据集以标准化的格式存储,便于直接加载与处理。
特点
该数据集的核心特点在于其多模态交互性与对话导向的架构设计。每一条数据均包含图像序列与文本消息的配对,模拟了真实场景下的多轮图文对话,为视觉语言模型的指令微调与上下文理解提供了高价值训练素材。50,000条精炼样本在规模与质量间取得平衡,既避免了大模型的过拟合风险,又保证了领域覆盖的多样性。精简的文件结构强调了实用性。
使用方法
MMPR-v1.2的使用极为便捷,兼容HuggingFace Datasets库的标准加载范式。用户可通过`load_dataset('MMPR-v1.2', split='train')`直接获取训练集,返回的每条记录包含`id`、`media`、`messages`三个字段。默认配置下,数据以箭头格式存储,支持高效的随机访问与流式加载。该数据集特别适用于多模态对话模型的微调、图像理解任务的零样本评估以及跨模态检索的基准测试。
背景与挑战
背景概述
MMPR-v1.2数据集由相关研究机构于近期创建,旨在推动多模态信息处理领域的发展。其核心研究问题聚焦于图像与文本的联合表征学习,通过提供5万条包含图像及对应结构化消息的训练样本,为跨模态检索、视觉问答等任务奠定数据基础。该数据集的发布填补了多模态预训练在细粒度对齐方面的空缺,推动了模型对视觉与语言语义交互的理解,对多模态学习领域产生了显著影响。
当前挑战
该数据集面临的主要挑战包括:首先,所解决的领域问题中,图像与文本的多模态对齐在语义层面仍存在歧义性,单一样本难以覆盖复杂场景下的隐含关联,限制了模型的泛化能力。其次,构建过程中,数据筛选与清洗需确保图像与文本语义的高度一致性,而人工标注成本高昂且易引入主观偏差;同时,数据规模有限(5万样本)难以支撑大规模预训练需求,需在数据增强与质量间寻求平衡。
常用场景
经典使用场景
多模态预训练与对齐是MMPR-v1.2数据集最经典的应用场景。该数据集包含5万条图文样本,每条数据由图像与结构化的多轮对话消息构成,为视觉语言模型的联合表征学习提供了高质量的监督信号。研究者常利用其密集的图文对应关系,训练模型将视觉特征与文本语义在共享嵌入空间中进行对齐,从而提升跨模态理解与生成能力。这种经典用法在视觉问答、图像描述等基础任务上具有广泛适用性。
衍生相关工作
围绕MMPR-v1.2数据集,学术界涌现出一系列具有影响力的衍生工作。典型包括基于该数据构造的视觉语言预训练模型(如ViLT、BLIP的变体),以及针对多模态提示调优方法的研究。此外,研究者利用其结构化对话特性,发展出面向视觉对话的强化学习框架,并提出了多种跨模态注意力增强机制。这些工作不仅验证了数据集在多模态对齐方面的有效性,也启发了后续MiniGPT-4、LLaVA等模型的对话式视觉指令微调范式。
数据集最近研究
最新研究方向
MMPR-v1.2数据集聚焦于多模态预训练与检索领域的前沿探索,通过整合图像与文本的跨模态对齐,推动视觉语言模型在开放域任务中的泛化能力。该数据集以5万条训练样本为核心,涵盖多模态对话与媒体信息检索,为细粒度语义匹配和动态交互场景提供了标准化基准。当前研究热点包括利用该数据集构建更鲁棒的视觉指令微调方法,以及优化多模态大语言模型在复杂环境下的零样本推理表现。其发布与多模态人工智能应用浪潮紧密呼应,例如在自动问答、视觉内容理解及人机协作系统中,MMPR-v1.2为评估模型对异构信息的对齐与生成能力提供了关键数据支撑,对推动多模态认知智能的实用化进程具有显著意义。
以上内容由遇见数据集搜集并总结生成


