GRAB
收藏arXiv2020-08-26 更新2024-06-21 收录
下载链接:
https://grab.is.tue.mpg.de
下载链接
链接失效反馈官方服务:
资源简介:
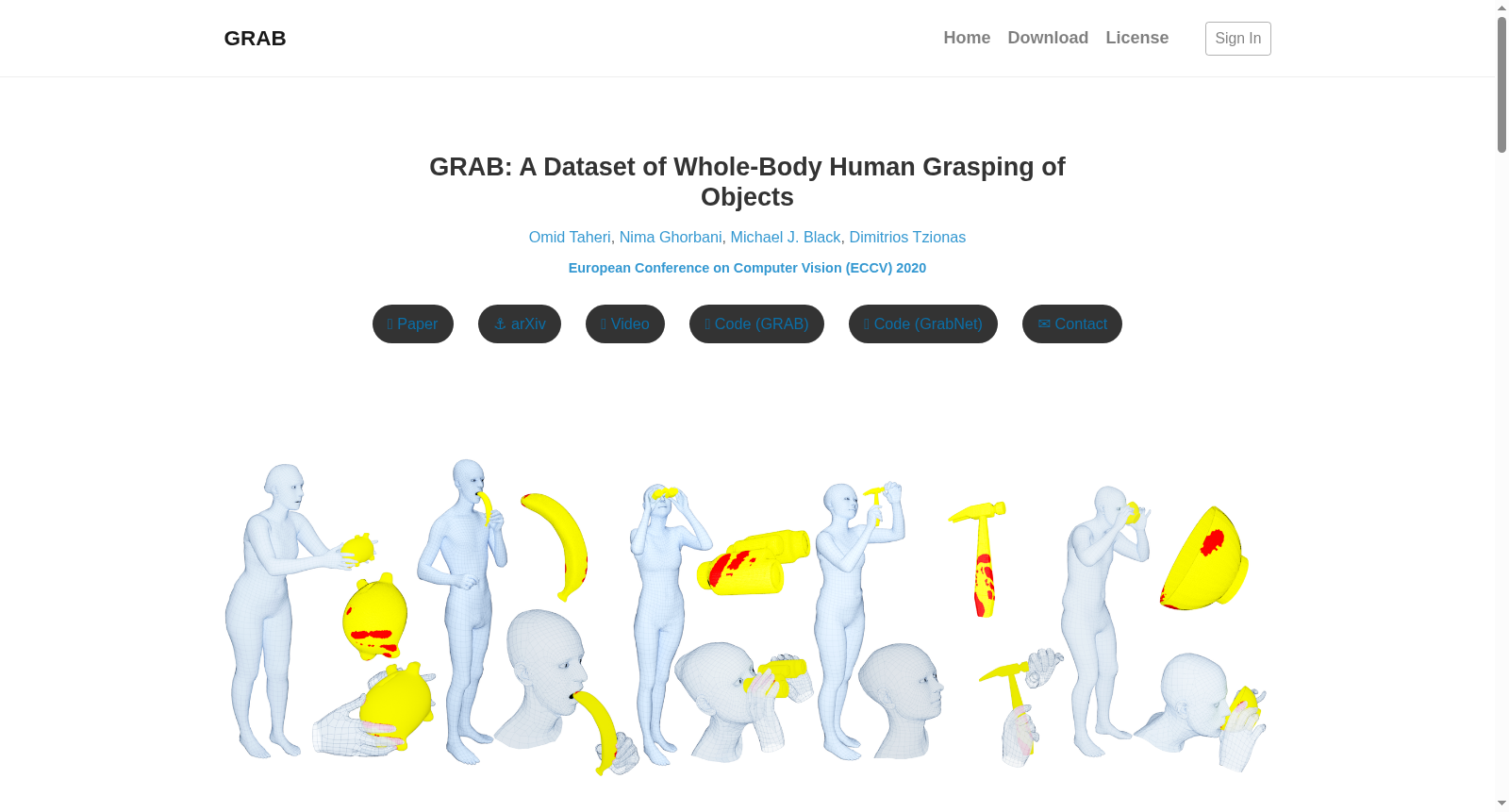
GRAB数据集由马克斯·普朗克智能系统研究所创建,专注于捕捉全身人类抓取物体的动作,包含10名不同性别和体型的参与者与51种日常物品的互动。数据集通过高级动作捕捉技术记录,包括详细的3D身体形状和姿势序列,以及物体与身体之间的接触信息。GRAB数据集不仅用于训练条件生成网络以预测3D手部抓取,还广泛应用于理解人类如何抓取和操纵物体,以及全身如何参与交互。数据集的创建过程涉及精确跟踪3D身体和物体形状,以及计算身体与物体之间的接触,从而生成一个独特的数据集,超越了现有数据集的功能。
The GRAB dataset was developed by the Max Planck Institute for Intelligent Systems, with a core focus on capturing full-body human object grasping actions. It includes interactions between 10 participants with diverse genders and body types and 51 daily objects. Recorded via advanced motion capture technologies, the dataset features detailed 3D body shape and pose sequences, alongside contact information between the human body and objects. The GRAB dataset is not only utilized for training conditional generative networks to predict 3D hand grasping, but also broadly applied to researching how humans grasp and manipulate objects, as well as the full body's involvement in such interactions. The creation of this dataset involves precise tracking of 3D body and object shapes, and calculation of contact information between the body and objects, yielding a unique dataset that outperforms the functionalities of existing datasets.
提供机构:
马克斯·普朗克智能系统研究所
创建时间:
2020-08-26
搜集汇总
数据集介绍
构建方式
在视觉分析领域,对图表进行精确解读是大型多模态模型面临的核心挑战之一。GRAB数据集通过全合成生成的方式构建,利用Matplotlib库程序化生成2170个图表分析问题,涵盖函数与数据序列的四大任务及23种图形属性。其构建过程首先为每个属性生成初始问题长列表,随后通过下采样确保答案分布的均匀性,以增强问题多样性并避免生成偏差。图表的美学参数如尺寸、字体和线条样式在基础任务中随机采样,而在复杂任务中则统一配置以保证可读性,同时通过严格控制问题复杂度与答案精度,实现了高质量、无噪声的基准测试环境。
特点
GRAB数据集的核心特点在于其针对前沿多模态模型设计的高难度挑战性,最高性能模型仅获得21.7%的准确率,显著超越了现有基准的饱和限度。该数据集全面覆盖从基础属性提取到多重变换推理的多样化任务,包括单属性分析、多函数/序列均值计算以及复杂几何变换后的属性推导。通过合成生成机制,GRAB确保了地面真值的绝对准确性与问题复杂度的精细可控,同时避免了训练数据污染的风险。其问题设计强调视觉分析推理而非OCR式读取,并融入整数与小数精度要求,进一步提升了评估的严谨性与区分度。
使用方法
GRAB数据集主要用于评估大型多模态模型在图表分析任务上的推理与指令遵循能力。使用时,模型接收包含问题与输出格式指令的简洁提示,需直接生成指定精度的数值答案。评估采用严格的字符串精确匹配协议,仅当模型输出与地面真值完全一致时判为正确,此举同步检验了任务执行与指令遵循的可靠性。研究人员可通过该基准系统测试模型在不同图形属性、任务复杂度及精度要求下的表现,并进行错误分析与消融实验,以深入理解模型在视觉分析中的优势与局限,推动下一代多模态模型的发展。
背景与挑战
背景概述
随着计算资源的丰富与多模态模型研究的蓬勃发展,现有评测基准在区分前沿模型能力方面逐渐显现出饱和与不足。在此背景下,剑桥大学与香港大学的研究团队于2024年推出了GRAB(GRaph Analysis Benchmark)图分析基准。该基准旨在评估大型多模态模型对科学图表进行视觉解析与定量推理的核心能力,其核心研究问题聚焦于模型在无法直接获取底层数据的情况下,仅通过视觉观察从函数曲线与数据序列中推导关键数学属性的高级认知任务。GRAB通过完全合成的方式构建了涵盖四大任务、23种图表属性的2170个高质量问题,为衡量模型在图分析这一关键领域的进展提供了严谨且具有前瞻性的标尺,对推动多模态推理向更深层次发展具有显著影响力。
当前挑战
GRAB基准所针对的领域挑战在于,现有模型在视觉数学推理,尤其是从图表中精确提取并计算函数截距、梯度、相关系数、面积等复杂属性方面存在显著能力缺口。该基准揭示了模型在处理多函数/序列均值计算、数据噪声干扰以及经过一系列几何变换后的函数属性推理等复合任务时尤为困难。在构建过程中,研究团队面临的主要挑战在于如何通过合成数据生成,在确保问题可解答性与图形可读性的前提下,系统性地控制问题的复杂度与答案分布的均匀性,同时避免训练数据污染,并设计出能够有效区分当前及下一代模型极限能力的、具有足够‘头部空间’的艰巨问题集合。
常用场景
经典使用场景
在大型多模态模型评估领域,GRAB数据集作为一项专门针对图表分析能力的基准测试,其经典使用场景在于系统性地评估模型从视觉图表中提取和计算数学属性的能力。该数据集通过合成生成的图表,要求模型执行函数方程推导、相关系数估算、数据分布统计以及几何变换后属性计算等核心任务,为研究者提供了一个可控且无噪声的测试环境,用以精确衡量模型在视觉-数学推理交叉领域的实际表现。
实际应用
在实际应用层面,GRAB数据集所针对的图表分析能力具有广泛的现实意义。在学术研究、商业智能和数据分析等领域,从业者经常需要从报告、文献或演示文稿中的静态图表直接解读关键信息,例如估算趋势线的斜率、计算数据序列的统计特征或理解函数变换后的效果。GRAB通过模拟这些真实场景中的分析任务,为开发能够辅助人类进行快速图表洞察的智能工具提供了关键的评估标准,推动多模态模型向更专业、更可靠的分析助手方向发展。
衍生相关工作
GRAB数据集的推出,在图表理解与多模态推理研究领域催生了一系列相关探索与对比工作。其设计理念继承并发展了早期合成图表基准(如FigureQA、PlotQA)的严谨性,同时在任务难度和复杂性上实现了显著跃升。该数据集常被与MathVista等通用数学视觉推理基准进行对比研究,以厘清模型在专项图表分析与广义数学问题解决上的能力差异。此外,其严格的精确匹配评估协议也影响了后续基准的设计,促使社区更加关注模型在遵循输出格式指令方面的可靠性,而不仅仅是答案的语义正确性。
以上内容由遇见数据集搜集并总结生成


