CCI 2.0
收藏Hugging Face2024-04-26 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/BAAI/CCI2-Data
下载链接
链接失效反馈官方服务:
资源简介:
To address the scarcity of high-quality safety datasets in the Chinese, we open-sourced the CCI (Chinese Corpora Internet) dataset on November 29, 2023. Building on this foundation, we continue to expand the data source, adopt stricter data cleaning methods, and complete the construction of the CCI 2.0 dataset. This dataset is composed of high-quality, reliable Internet data from trusted sources. It has undergone strict data cleaning and de-duplication, with targeted detection and filtering carried out for content quality and safety. The rules for data processing include:
Rule-based filtering: safety filtering based on keywords, spam information filtering, etc.
Model-based filtering: filtering of low-quality content by training a classification model.
Deduplication: within and between datasets dedup.
The CCI 2.0 corpus released is 501GB in size.
提供机构:
Beijing Academy of Artificial Intelligence
创建时间:
2024-04-17
搜集汇总
数据集介绍
构建方式
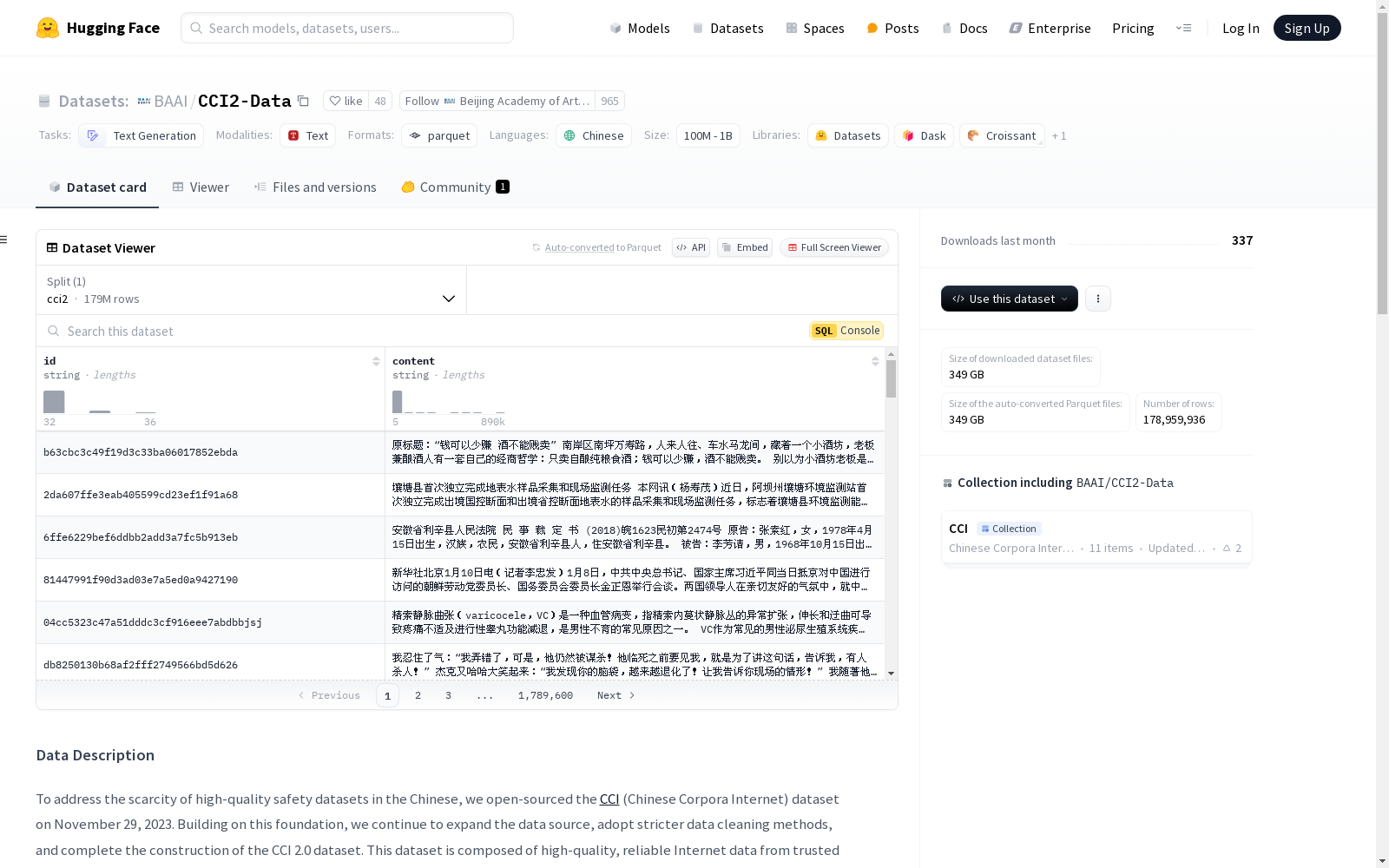
CCI 2.0数据集的构建旨在解决中文高质量安全数据稀缺的问题。该数据集基于互联网可信来源的高质量数据,经过严格的数据清洗和去重处理。数据处理规则包括基于关键词的安全过滤、垃圾信息过滤,以及通过训练分类模型对低质量内容进行过滤。此外,数据集内部和跨数据集之间的去重处理确保了数据的唯一性和高质量。最终发布的CCI 2.0语料库规模达到501GB。
特点
CCI 2.0数据集的特点在于其高质量和可靠性。数据集由互联网可信来源的数据构成,经过严格的安全和质量检测,确保了内容的纯净性和适用性。数据集的规模庞大,涵盖了178,959,936个样本,适用于广泛的文本生成任务。此外,数据集的结构清晰,每个样本包含唯一的文档ID和内容字段,便于用户进行数据处理和分析。
使用方法
CCI 2.0数据集可通过BAAI DataHub和Huggingface平台获取。用户需在BAAI DataHub注册并填写调查问卷后才能下载数据。在Huggingface平台上,用户可以使用`load_dataset`函数直接加载数据集。使用该数据集时,用户需遵守相关的使用协议,确保不进行可能对人类受试者造成伤害的实验。数据集的使用代码示例简洁明了,便于快速上手。
背景与挑战
背景概述
CCI 2.0数据集由北京智源人工智能研究院(BAAI)于2024年4月26日发布,旨在解决中文互联网数据中高质量安全数据稀缺的问题。该数据集基于早期发布的CCI数据集,进一步扩展了数据来源,并采用了更为严格的数据清洗和去重方法。CCI 2.0数据集由来自可信互联网源的高质量数据构成,经过基于规则和模型的过滤,确保了内容的质量和安全性。该数据集的发布为中文自然语言处理领域提供了重要的资源支持,尤其在文本生成任务中具有广泛的应用前景。
当前挑战
CCI 2.0数据集在构建过程中面临多重挑战。首先,数据清洗和去重是核心难题,尤其是在处理大规模互联网数据时,如何有效识别和过滤低质量、重复或有害内容成为关键。其次,数据安全性和隐私保护也是重要挑战,数据集需确保不包含可能对用户造成伤害的内容。此外,数据集的规模庞大,存储和分发效率成为技术瓶颈,如何在保证数据完整性的同时优化下载和使用体验,是开发者需要持续解决的问题。
常用场景
经典使用场景
CCI 2.0数据集在自然语言处理领域中被广泛应用于中文文本生成任务。由于其数据来源广泛且经过严格清洗,该数据集特别适合用于训练和评估生成模型,如GPT系列模型。研究人员可以利用该数据集进行文本生成、语言模型预训练等任务,以提升模型在中文语境下的表现。
解决学术问题
CCI 2.0数据集解决了中文自然语言处理领域中高质量数据稀缺的问题。通过提供大规模、高质量的中文互联网数据,该数据集为研究人员提供了丰富的语料资源,支持了中文语言模型的预训练和微调。这不仅提升了模型在中文任务中的表现,还推动了中文自然语言处理技术的发展。
衍生相关工作
CCI 2.0数据集的发布催生了一系列相关研究工作,特别是在中文语言模型领域。基于该数据集,研究人员开发了多个先进的中文生成模型,如BAAI的中文GPT模型。这些模型在中文文本生成、机器翻译等任务中表现出色,进一步推动了中文自然语言处理技术的发展。
以上内容由遇见数据集搜集并总结生成


