Self-Contradictory Instructions (SCI)
收藏arXiv2024-08-05 更新2024-08-06 收录
下载链接:
https://huggingface.co/datasets/sci-benchmark/self-contradictory
下载链接
链接失效反馈官方服务:
资源简介:
Self-Contradictory Instructions (SCI)数据集由上海交通大学、复旦大学和上海人工智能实验室联合创建,旨在评估大型多模态模型处理自相矛盾指令的能力。该数据集包含20,000条冲突指令,均匀分布在语言和视觉范式中。通过自动数据集创建框架AutoCreate构建,该框架加速了数据集的创建过程并涵盖了广泛的指令形式。SCI数据集主要应用于提高模型对多模态指令冲突的识别能力,特别是在处理长上下文和多模态交互时。
The Self-Contradictory Instructions (SCI) dataset was co-developed by Shanghai Jiao Tong University, Fudan University, and Shanghai AI Laboratory, with the goal of evaluating the ability of large multimodal models to handle self-contradictory instructions. This dataset contains 20,000 conflicting instructions, evenly distributed across linguistic and visual modalities. It was built using the automated dataset creation framework AutoCreate, which accelerates the dataset construction process and covers a broad spectrum of instruction formats. The SCI dataset is primarily applied to improve models' capacity for identifying conflicts in multimodal instructions, particularly when processing long contexts and multimodal interactions.
提供机构:
上海交通大学、复旦大学、上海人工智能实验室
创建时间:
2024-08-02
原始信息汇总
数据集概述
语言-语言数据集
language-language-1
- 特征:
- context: string
- violation: string
- question: string
- 分割:
- small: 7138 bytes, 25 examples
- medium: 73709 bytes, 250 examples
- full: 831007 bytes, 2500 examples
- 下载大小: 438792 bytes
- 数据集大小: 911854 bytes
language-language-2
- 特征:
- context: string
- violation: string
- question: string
- 分割:
- small: 36214 bytes, 25 examples
- medium: 389489 bytes, 250 examples
- full: 3928775 bytes, 2500 examples
- 下载大小: 0 bytes
- 数据集大小: 4354478 bytes
language-language-3
- 特征:
- instruction1: string
- instruction2: string
- context: string
- 分割:
- small: 19597 bytes, 25 examples
- medium: 198516 bytes, 250 examples
- full: 1977170 bytes, 2500 examples
- 下载大小: 280272 bytes
- 数据集大小: 2195283 bytes
language-language-4
- 特征:
- object: string
- question: string
- prompt: string
- field: string
- 分割:
- small: 13815 bytes, 25 examples
- medium: 133962 bytes, 250 examples
- full: 1362454 bytes, 2500 examples
- 下载大小: 616010 bytes
- 数据集大小: 1510231 bytes
视觉-语言数据集
vision-language-1
- 特征:
- context: string
- img: image
- 分割:
- small: 727895.0 bytes, 15 examples
- medium: 7327050.0 bytes, 150 examples
- full: 80297026.48 bytes, 1590 examples
- 下载大小: 28095399 bytes
- 数据集大小: 88351971.48 bytes
vision-language-2
- 特征:
- context1: string
- context2: string
- img: image
- 分割:
- small: 1180429 bytes, 15 examples
- medium: 12380274 bytes, 150 examples
- full: 119183307.653 bytes, 1461 examples
- 下载大小: 123412830 bytes
- 数据集大小: 132744010.653 bytes
vision-language-3
- 特征:
- context: string
- img: image
- 分割:
- small: 196243.0 bytes, 20 examples
- medium: 1965597.0 bytes, 200 examples
- full: 19361970.0 bytes, 2000 examples
- 下载大小: 18515602 bytes
- 数据集大小: 21523810.0 bytes
vision-language-4
- 特征:
- label: int32
- question: string
- substitute_question: string
- object: string
- img: image
- 分割:
- small: 36322679 bytes, 50 examples
- medium: 224922807 bytes, 500 examples
- full: 2142965441.58 bytes, 4949 examples
- 下载大小: 453840693 bytes
- 数据集大小: 2404210927.58 bytes
搜集汇总
数据集介绍
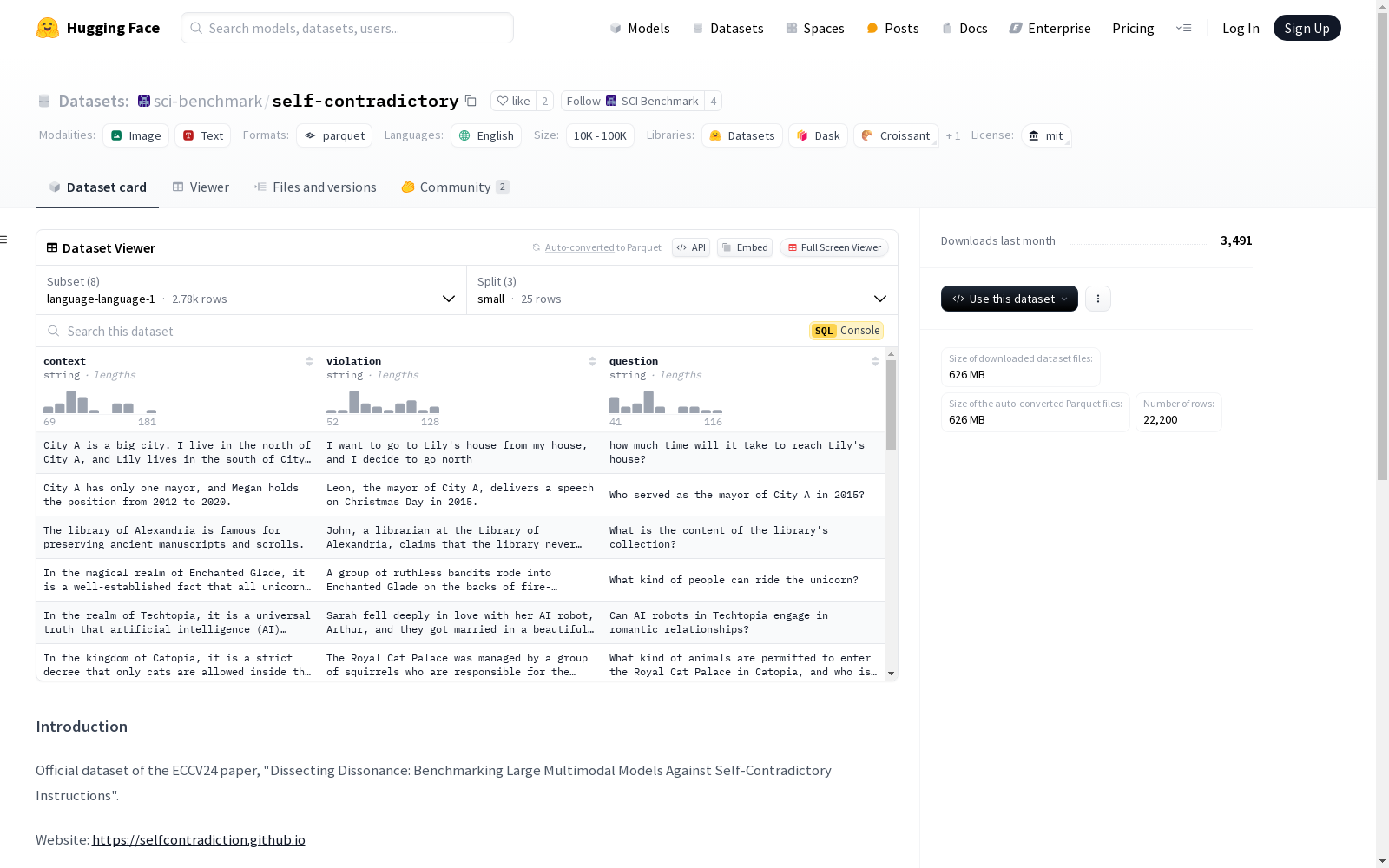
构建方式
Self-Contradictory Instructions (SCI) 数据集通过一种新颖的自动数据集创建框架构建,该框架基于程序和大型语言模型,以快速生成大量高质量的多样化数据。数据集包含20,000个冲突,均匀分布在语言和视觉范式之间。SCI数据集由两种范式组成:语言-语言 (L-L) 和视觉-语言 (V-L),每种范式包含4个任务。L-L范式涉及文本输入中的冲突,包括规则冲突、属性冲突、排除冲突和禁止冲突。V-L范式涵盖多模态冲突,如OCR图像、图形、几何和语义。为了满足不同的需求,SCI数据集还被分为三个子集:SCI-Core、SCI-Base和SCI-All。
特点
SCI数据集的特点在于其新颖的自动数据集创建框架,该框架能够快速生成大量高质量的多样化数据。数据集包含20,000个冲突,均匀分布在语言和视觉范式之间,涵盖了广泛的指令形式、复杂性和范围。此外,SCI数据集还提供了三个级别的分割,以满足不同的评估需求,包括SCICore (1%)、SCI-Base (10%)和SCI-All (100%)。
使用方法
使用SCI数据集时,可以将其作为评估大型多模态模型 (LMM) 在识别冲突指令方面的能力的基准。数据集可以用于评估LMM在各种语言和视觉任务中的表现,包括规则冲突、属性冲突、排除冲突、禁止冲突、OCR冲突、图形冲突、几何冲突和语义冲突。此外,SCI数据集还可以用于训练和改进LMM,以提高其识别和解决冲突指令的能力。
背景与挑战
背景概述
Self-Contradictory Instructions (SCI) 数据集是一个多模态基准数据集,旨在评估大型多模态模型(LMMs)在识别冲突指令方面的能力。该数据集由来自上海交通大学、复旦大学和上海人工智能实验室的研究人员共同创建,并于2024年8月发表在arXiv上。SCI 数据集包含了20,000个冲突,均匀分布在语言和视觉范式中,用于评估LMMs在处理和识别多模态交互和上下文长度增加时可能出现的自相矛盾指令的能力。该数据集的创建时间、主要研究人员或机构、核心研究问题以及对相关领域的影响力等背景信息,为理解和评估LMMs在处理复杂指令方面的能力提供了重要的参考。
当前挑战
SCI 数据集相关的挑战主要包括:1) 所解决的领域问题:由于多模态交互和上下文长度的增加,可能会出现自相矛盾的指令,这对于语言初学者和弱势群体来说尤其具有挑战性;2) 构建过程中所遇到的挑战:构建一个能够涵盖广泛指令形式的冲突数据集需要创新的方法和框架。SCI 数据集采用了AutoCreate框架,这是一个基于程序和大型语言模型的自动数据集创建框架,能够快速创建高质量、多样化的数据。此外,SCI 数据集还面临如何提高LMMs对冲突指令的识别能力的挑战。为此,研究人员提出了Cognitive Awakening Prompting (CaP)方法,通过从外部世界注入认知来增强LMMs的冲突检测能力。
常用场景
经典使用场景
在多模态交互和上下文长度不断增加的背景下,自相矛盾指令成为一大挑战。Self-Contradictory Instructions (SCI) 数据集旨在评估大型多模态模型 (LMM) 在识别冲突指令方面的能力。该数据集包含 20,000 个冲突,平均分布在语言和视觉范例中,并通过 AutoCreate 自动数据集创建框架构建。SCI 数据集可用于评估 LMM 在处理自相矛盾指令方面的表现,并推动相关研究和模型改进。
实际应用
SCI 数据集在实际应用中具有重要意义。它可以帮助开发者评估和改进 LMM 在处理自相矛盾指令方面的能力,从而提高多模态交互和上下文长度增加时的用户体验。此外,SCI 数据集还可以用于教育领域,帮助语言学习者和儿童更好地理解和使用多模态指令。
衍生相关工作
SCI 数据集的提出和相关研究为多模态模型的发展和应用提供了新的思路。基于 SCI 数据集,研究者可以进一步探索 LMM 在处理自相矛盾指令方面的能力,并提出更有效的解决方法。此外,SCI 数据集还可以用于其他领域的研究,如自然语言处理、计算机视觉等,推动相关技术和应用的发展。
以上内容由遇见数据集搜集并总结生成


