scisci-paper-corpus-sections-v2
收藏Hugging Face2025-08-07 更新2025-08-08 收录
下载链接:
https://huggingface.co/datasets/ErzhuoShao/scisci-paper-corpus-sections-v2
下载链接
链接失效反馈官方服务:
资源简介:
这是一个包含学术文献信息的文本数据集,其中包括文献的日期、作者、标题、摘要等详细信息,并提供了文本的分类和摘要信息,适用于文本分类和自然语言处理等任务。
创建时间:
2025-08-02
原始信息汇总
数据集概述
基本信息
- 数据集名称: scisci-paper-corpus-sections-v2
- 存储位置: https://huggingface.co/datasets/ErzhuoShao/scisci-paper-corpus-sections-v2
- 下载大小: 860808382 字节
- 数据集大小: 1313472763 字节
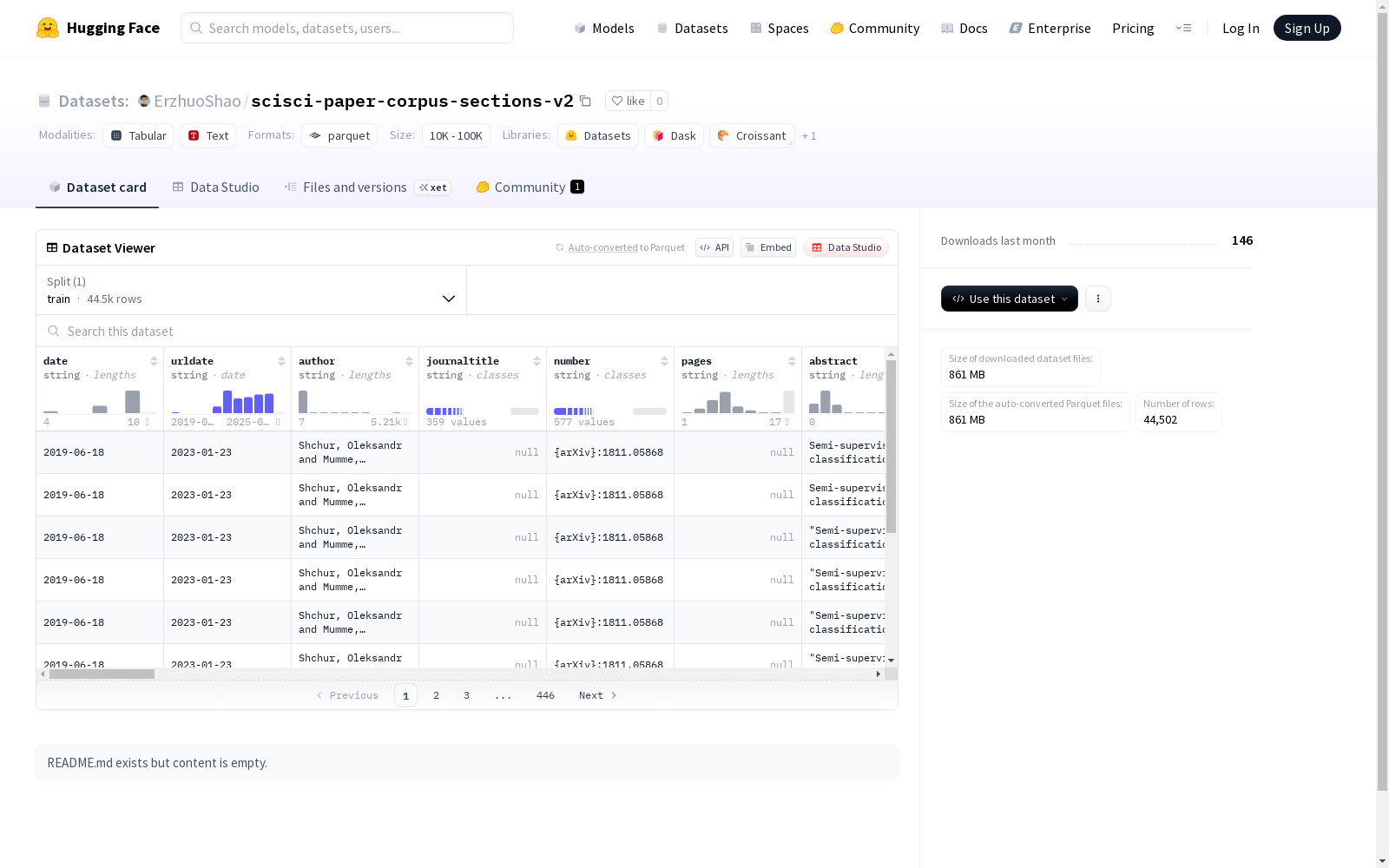
- 训练集样本数: 44502 条
数据结构
特征字段
-
文献元数据:
date: 日期urldate: URL访问日期author: 作者journaltitle: 期刊标题number: 编号pages: 页码abstract: 摘要doi: DOI标识符url: URL链接volume: 卷号title: 标题ENTRYTYPE: 条目类型ID: 唯一标识符keywords: 关键词pmid: PubMed IDshortjournal: 期刊缩写issn: ISSN号langid: 语言标识rights: 版权信息shorttitle: 短标题eprint: 电子打印标识eprinttype: 电子打印类型publisher: 出版商institution: 机构titleaddon: 标题附加信息pagetotal: 总页数isbn: ISBN号location: 位置editor: 编辑booktitle: 书籍标题type: 类型eventtitle: 事件标题series: 系列bookauthor: 书籍作者(空值)issue: 期号pmcid: PMC ID(空值)editoratype: 编辑A类型editora: 编辑Aholder: 持有者editorbtype: 编辑B类型(空值)editorb: 编辑B(空值)edition: 版本(空值)paper_title: 论文标题
-
章节信息:
section_id: 章节ID(int64)section_category: 章节类别section_heading: 章节标题section_text: 章节文本section_text_token_count: 章节文本标记计数(int64)section_summary: 章节摘要embedding: 嵌入向量(float64序列)
数据分割
- 训练集:
- 路径:
data/train-* - 字节数: 1313472763
- 样本数: 44502
- 路径:
搜集汇总
数据集介绍
构建方式
在科学文献数字化处理领域,scisci-paper-corpus-sections-v2数据集通过系统化解析学术论文结构构建而成。其核心方法涉及对原始文献的深度分割,将每篇论文按章节类别(如摘要、方法、结果)进行精细化划分,并提取章节标题、文本内容及标记化计数。该过程采用自动化流水线处理,确保章节边界精确识别与语义连贯性,同时保留文献元数据(如DOI、作者、期刊信息),形成结构化且机器可读的多维度学术语料。
使用方法
研究者可基于该数据集开展学术文本挖掘与自然语言处理任务,例如章节级摘要生成、论文结构预测或学科领域语义分析。使用时需加载训练集拆分(train split),通过section_text字段获取原始文本,结合embedding字段进行向量化建模。元数据字段(如doi、journaltitle)支持文献溯源与跨数据集关联,而section_summary字段可直接用于监督式摘要模型训练,适用于构建自动化文献处理管道。
背景与挑战
背景概述
科学文献语料库章节数据集v2由学术机构于2020年代初期构建,旨在推动学术文本挖掘与自然语言处理研究。该数据集聚焦于科学论文的结构化分析,通过系统化采集论文章节信息,为学术文献的自动摘要、知识提取和语义理解提供重要支撑。其创新性在于将完整论文分解为标准化章节单元,显著提升了学术文本处理的粒度与精度,对计算语言学和信息检索领域产生深远影响。
当前挑战
该数据集核心挑战在于解决学术文献多维度语义解析问题,包括跨学科术语的归一化处理、章节功能的自动分类以及长文本语义连贯性保持。构建过程中面临文献异构性挑战,需克服不同出版体系的元数据规范差异、章节结构非标准化问题,以及大规模学术文本的质量过滤与隐私信息剔除等技术难点。
常用场景
经典使用场景
在科学文献分析领域,该数据集通过精细划分的论文章节结构,为研究者提供了深入探索学术文本组织模式的宝贵资源。其经典应用场景包括自动摘要生成、章节分类和跨文献内容对比分析,这些应用显著提升了学术信息处理的自动化水平。
解决学术问题
该数据集有效解决了学术文本挖掘中的结构化解构难题,为研究论文的标准化解析提供了基准。通过提供详细的章节级标注,它支持了学术写作模式分析、知识抽取和文献计量学研究,推动了计算语言学与科学计量学的交叉融合。
实际应用
在实际应用中,该数据集支撑了智能学术写作辅助系统的开发,能够为科研人员提供结构化的写作参考。同时,它也被广泛应用于学术搜索引擎的优化,通过章节级别的索引和匹配,显著提升了学术文献检索的精准度和效率。
数据集最近研究
最新研究方向
在科学文献结构化分析领域,scisci-paper-corpus-sections-v2数据集正推动学术文本智能处理的前沿探索。该数据集通过精细的章节级标注,为大型语言模型在科研文档理解任务提供了关键支撑。当前研究聚焦于跨学科文献的自动摘要生成和知识图谱构建,结合嵌入向量特征实现语义层面的深度挖掘。随着预训练模型在学术领域的广泛应用,该数据集已成为科学文献结构解析、学术影响力预测以及研究趋势分析的核心资源,显著提升了机器对复杂学术文本的认知能力。
以上内容由遇见数据集搜集并总结生成


