cambridgeltl/vsr_zeroshot
收藏Hugging Face2023-03-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/cambridgeltl/vsr_zeroshot
下载链接
链接失效反馈官方服务:
资源简介:
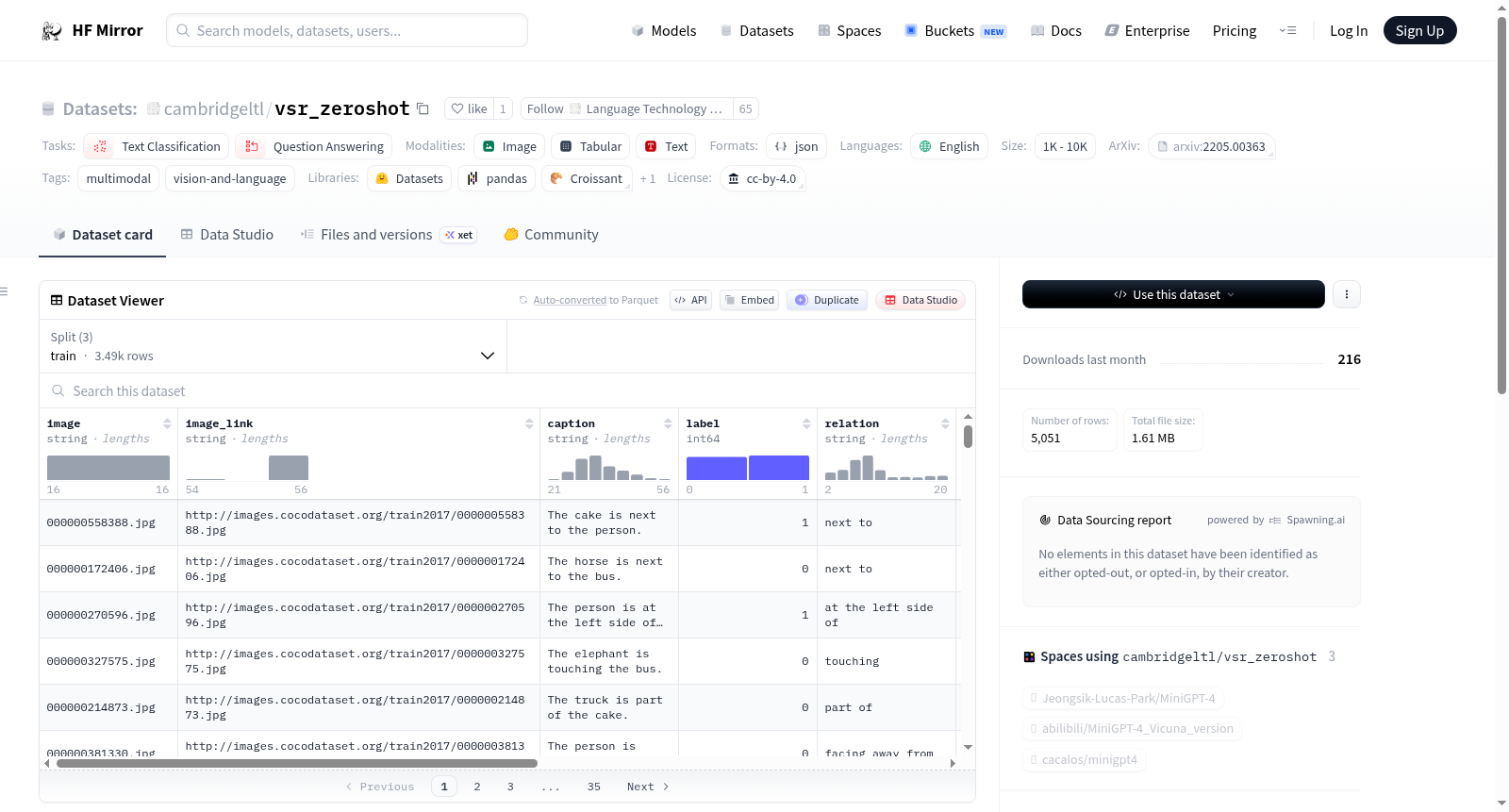
VSR(视觉空间推理)是一个多模态数据集,专注于视觉和语言任务。该数据集包含零样本集,适用于文本分类和问答任务。数据集的语言为英语,大小在1K到10K之间。使用该数据集时,需要单独下载图像文件。
VSR(视觉空间推理)是一个多模态数据集,专注于视觉和语言任务。该数据集包含零样本集,适用于文本分类和问答任务。数据集的语言为英语,大小在1K到10K之间。使用该数据集时,需要单独下载图像文件。
提供机构:
cambridgeltl
原始信息汇总
数据集概述
基本信息
- 许可证: cc-by-4.0
- 任务类别:
- 文本分类
- 问答
- 语言: 英语
- 标签:
- 多模态
- 视觉与语言
- 数据集名称: VSR (zeroshot)
- 大小类别: 1K<n<10K
数据集详情
- 名称: VSR: Visual Spatial Reasoning
- 描述: 这是VSR的零样本集,VSR是一个视觉空间推理数据集,相关论文发表于TACL 2023。
使用方法
-
数据集加载示例: python from datasets import load_dataset
data_files = {"train": "train.jsonl", "dev": "dev.jsonl", "test": "test.jsonl"} dataset = load_dataset("cambridgeltl/vsr_zeroshot", data_files=data_files)
-
注意: 图像文件需要单独下载,详细信息见
data/。
引用信息
bibtex @article{Liu2022VisualSR, title={Visual Spatial Reasoning}, author={Fangyu Liu and Guy Edward Toh Emerson and Nigel Collier}, journal={Transactions of the Association for Computational Linguistics}, year={2023}, }
搜集汇总
数据集介绍
构建方式
在视觉语言理解领域,VSR零样本数据集通过精心设计的流程构建而成。研究团队从公开的视觉场景中提取图像,并基于空间关系标注生成对应的自然语言描述。每一条数据均包含图像与文本对,文本以陈述句形式描述图像中的空间方位,如物体相对位置。构建过程中注重数据的多样性与平衡性,确保覆盖多种常见空间关系,并通过人工校验提升标注质量,为模型零样本评估奠定基础。
特点
VSR零样本数据集的核心特点在于其专注于视觉空间推理任务,强调模型对图像中物体间方位关系的理解能力。数据集以英文呈现,包含多模态数据,规模在1K到10K之间,适用于文本分类与问答等任务。其零样本设定要求模型在未针对特定关系训练的情况下进行推理,从而有效评估模型的泛化与逻辑推理能力。数据格式简洁,图像需单独下载,便于研究者灵活使用。
使用方法
使用VSR零样本数据集时,研究者可通过Hugging Face的datasets库便捷加载。具体操作中,需指定训练、开发与测试集的JSONL文件路径,并单独下载对应的图像文件以完成数据整合。该数据集适用于多模态模型的评估与微调,尤其在视觉语言预训练领域,能帮助检验模型对空间关系的零样本推理性能。用户可参考其GitHub仓库获取更详细的介绍与数据说明。
背景与挑战
背景概述
视觉空间推理(VSR)数据集由剑桥大学语言技术实验室于2023年发布,旨在推动多模态人工智能在空间理解领域的发展。该数据集聚焦于图像与文本的联合理解,核心研究问题在于评估模型对物体间空间关系的零样本推理能力,如方位、相对位置等。通过构建精细标注的图像-文本对,VSR为计算机视觉与自然语言处理的交叉研究提供了基准,显著提升了模型在复杂场景下的语义解析与逻辑推断水平,对自动驾驶、机器人导航等应用领域具有深远影响。
当前挑战
VSR数据集所解决的领域挑战在于多模态空间关系推理,这要求模型超越简单的物体识别,深入理解图像中元素的拓扑与几何关联,并在零样本设置下泛化到未见过的关系组合。构建过程中的挑战包括空间关系标注的歧义性消除,需确保标注的一致性与逻辑严密性;同时,数据收集需平衡多样性与复杂性,涵盖日常场景中的丰富空间配置,避免偏差,并处理图像与文本对齐的细粒度匹配问题。
常用场景
经典使用场景
在视觉语言多模态研究领域,VSR零样本数据集为评估模型的空间推理能力提供了基准。该数据集通过图像与文本对的形式,要求模型判断描述性语句是否准确对应图像中的空间关系,例如物体间的相对位置或方向。这一场景常用于测试模型在未经特定训练数据暴露下的泛化性能,推动了零样本学习在视觉理解中的进展。
解决学术问题
VSR零样本数据集致力于解决多模态人工智能中空间关系理解的难题。传统模型往往在复杂空间描述上表现薄弱,该数据集通过精心设计的视觉场景与自然语言陈述,帮助研究者量化模型对上下、左右、远近等关系的认知准确性。其意义在于为空间推理提供了可重复的评估框架,促进了视觉语言模型在抽象思维层面的进步。
衍生相关工作
围绕VSR零样本数据集,已衍生出一系列经典研究工作。这些工作多聚焦于改进多模态Transformer架构或引入新的注意力机制,以提升模型在零样本设置下的空间推理性能。部分研究进一步扩展了数据集的适用范围,结合对比学习或元学习策略,推动了视觉语言预训练模型在细粒度关系理解上的创新。
以上内容由遇见数据集搜集并总结生成


