EN-DE-MT
收藏Hugging Face2026-05-13 更新2026-05-14 收录
下载链接:
https://huggingface.co/datasets/HUFS-DILAB/EN-DE-MT
下载链接
链接失效反馈官方服务:
资源简介:
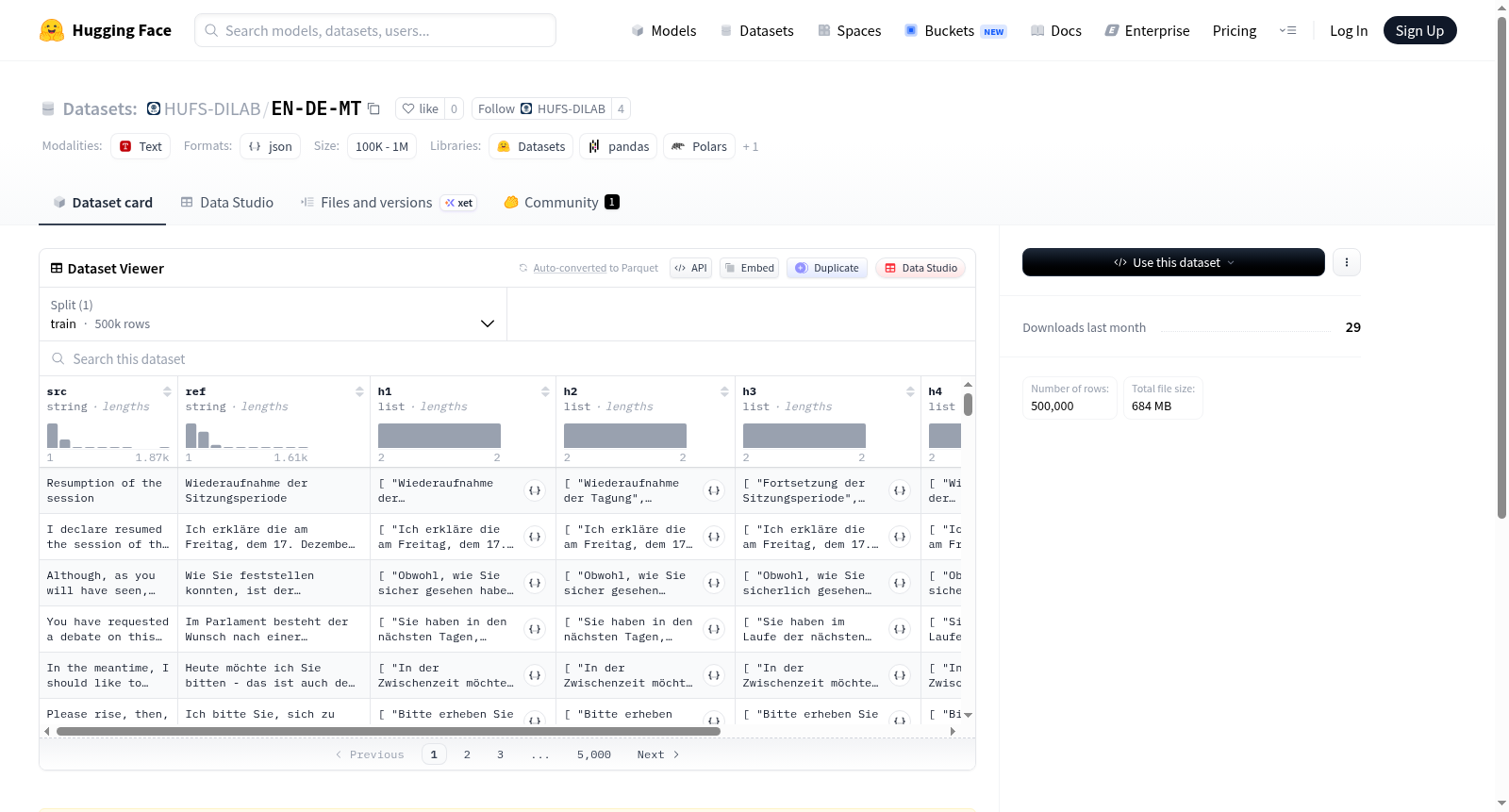
该数据集是WMT14(2014年机器翻译研讨会)英德翻译任务训练集的一个子集,包含50万句对。数据由Helsinki-NLP/opus-mt-en-de机器翻译模型生成,翻译方向为英语到德语,解码过程采用集束搜索(beam search),参数设置为num_beams=5和num_return_sequences=5。每个数据样本包含以下字段:src(英语源文本)、ref(原始人工参考译文),以及h1到h5(5个由模型生成的德语翻译候选,每个候选都附有其对数概率得分,并且列表已按得分降序排列)。该数据集适用于机器翻译模型训练、评估、重排序(reranking)或翻译质量估计等研究任务。
This dataset is a subset of the WMT14 (Workshop on Machine Translation 2014) English-German translation task training set, containing 500,000 sentence pairs. The data is generated by the Helsinki-NLP/opus-mt-en-de machine translation model in the direction from English to German, using beam search decoding with parameters set to num_beams=5 and num_return_sequences=5. Each data sample includes the following fields: src (English source text), ref (original human reference translation), and h1 to h5 (five model-generated German translation candidates, each accompanied by its log probability score, with the list sorted in descending order by score). The dataset is suitable for research tasks such as machine translation model training, evaluation, reranking, or translation quality estimation.
创建时间:
2026-05-11
原始信息汇总
根据您提供的数据集详情页面内容,以下是该数据集的概述:
数据集概述
- 数据集名称:EN-DE-MT
- 提供机构:HUFS-DILAB
- 任务类型:机器翻译(English → German)
数据来源与构成
- 源文本(src):来自 WMT14 英语-德语数据集,使用训练集拆分,包含 500,000 个句子。
- 参考译文(ref):原始参考译文。
翻译候选与评分
- 候选译文:包含 5 个翻译候选(h1, h2, h3, h4, h5),每个候选附有对数概率分数,按降序排列。
模型与参数
- 翻译模型:Helsinki-NLP/opus-mt-en-de
- 翻译方向:英语 → 德语
- 束搜索配置:束宽(num_beams)= 5,返回序列数(num_return_sequences)= 5
搜集汇总
数据集介绍
构建方式
该数据集源自WMT14英德翻译任务的训练子集,从中精选了50万句对作为原始语料。在构建过程中,采用Helsinki-NLP/opus-mt-en-de模型作为翻译引擎,通过波束搜索策略生成五个候选翻译序列,波束宽度与返回序列数均设为5。每个候选翻译均附带对数概率分数,并按降序排列,从而构建出包含源句、参考译文及五组候选译文及其概率分数的多候选翻译质量评估数据集。
特点
数据集的核心特色在于其多候选翻译结构,不仅提供了单一参考译文,更收录了五个由机器翻译模型生成的不同译法及其概率评分。这种设计使得研究者能够深入分析不同翻译候选在概率分布上的差异,从而评估模型输出的一致性与多样性。同时,数据集保留了源语言与参考译文的原始对应关系,为机器翻译任务的细粒度评估与改进提供了丰富的数据支撑。
使用方法
使用时,可直接加载数据集中src与ref字段作为标准输入输出对,用于基础翻译模型训练或评测。而h1至h5字段及其关联的概率分数,则适用于开展排序学习、重排序模型训练或翻译假设空间分析等进阶任务。研究者亦可提取候选译文与参考译文进行对比,或利用对数概率值进行模型置信度校准与不确定性量化研究。
背景与挑战
背景概述
机器翻译(Machine Translation, MT)作为自然语言处理领域的核心任务,其发展历程中,大规模平行语料库的构建与高质量翻译模型的评估始终是研究焦点。EN-DE-MT数据集诞生于这一背景下,基于WMT14英德翻译任务的训练集(包含50万句对),由赫尔辛基大学NLP团队创建的opus-mt-en-de模型驱动,旨在系统性地探索束搜索(beam search)策略对翻译质量的影响。该数据集通过提供源文本、参考译文及五组候选翻译序列及其对数概率分数,为神经机器翻译中的解码算法优化、概率校准研究及模型误差分析提供了标准化基准。自发布以来,EN-DE-MT已成为验证新一代解码策略(如多样化束搜索、对比搜索)的关键测试平台,对推动机器翻译系统的鲁棒性与多样性具有重要学术价值。
当前挑战
EN-DE-MT数据集所解决的领域问题聚焦于神经机器翻译中束搜索算法生成候选译文的质量评估与排序挑战。传统束搜索常因过度追求高概率而牺牲翻译多样性,导致输出重复或信息缺失,该数据集通过提供带概率分数的多候选序列,促使研究者探索如何在概率域中平衡准确性与新颖性。构建过程中,面临两大挑战:其一,需确保WMT14基准语料库的领域覆盖均衡性,避免医学、法律等专业文本的稀疏性引发模型偏见;其二,模型输出序列中通过束搜索生成的最佳候选概率虽高,但常与人类参考译文存在语义偏离,如何定义并量化这种概率-质量间的非线性关系成为核心难题。
常用场景
经典使用场景
EN-DE-MT数据集以其源自WMT14英德翻译任务的权威语料为根基,承载了500k句高质量平行句对,并创新性地引入了基于Helsinki-NLP/opus-mt-en-de模型生成的五条候选翻译序列及其对数概率得分。这一精心设计使其成为评估和优化神经机器翻译系统在束搜索策略下表现的首选基准。研究者可通过比对排序后的候选序列与人工参考译文,精准分析模型在解码过程中的不确定性分布,从而在翻译质量与多样性之间寻求精密平衡。该数据集特别适用于探索束搜索宽度对翻译效果的影响,以及概率校准技术在机器翻译中的有效性验证。
衍生相关工作
源自该数据集的经典工作在机器翻译研究版图中留下了深刻印记。基于其多候选概率结构,学术界衍生出关于对比学习优化排序的系列方法,如利用负采样训练策略改善翻译鲁棒性的开创性论文。同时,它为最小风险训练理论提供了标准实验平台,催生了多项基于期望效用最大化的解码优化算法。在质量评估领域,若干工作以该数据集为起点构建了预测候选排序一致性的元评估模型,进而推动了无参考译文评价指标的进步。此外,其结构化输出形式启发了关于生成式语言模型在非自回归解码场景中的适应性研究,持续影响着当代序列生成任务的框架设计。
数据集最近研究
最新研究方向
针对机器翻译质量评估与解码策略优化,该数据集EN-DE-MT通过提供WMT14英德平行语料子集及基于Helsinki-NLP模型的束搜索候选译文(含对数概率评分),为翻译假设空间的量化分析开辟了新路径。前沿研究正聚焦于利用此类带评分候选集,结合对比学习与概率校准技术,探索翻译多样性、模型置信度与输出质量间的内在关联,进而推动神经机器翻译在低熵场景下的鲁棒解码策略革新。这一方向不仅深化了对序列生成不确定性机制的理解,也为构建更透明、可解释的评估基准提供了数据基石,在跨语言信息交互日益频繁的背景下具有显著的应用潜力。
以上内容由遇见数据集搜集并总结生成


