CAGE-seq clusters
收藏DataCite Commons2022-10-22 更新2024-07-29 收录
下载链接:
https://figshare.com/articles/dataset/CAGE-seq_clusters/21257703
下载链接
链接失效反馈官方服务:
资源简介:
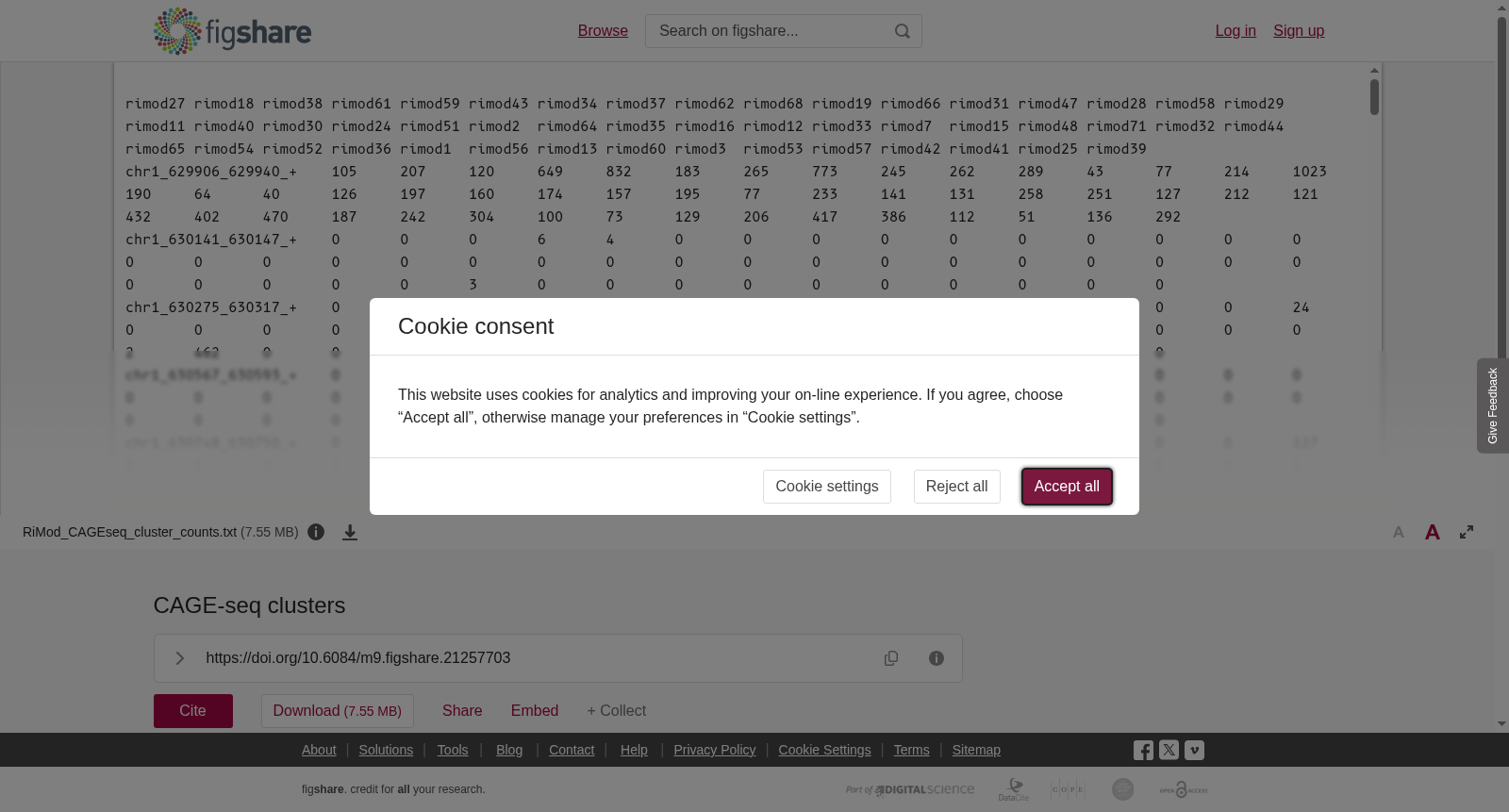
Cluster count table from frontal CAGE-seq data of RiMod-FTD resource (https://www.rimod-ftd.org/). <br> The data was processed as follows: Sequencing adapters and barcodes in CAGE-seq FastQ files were trimmed using Skewer (v.0.1.126). Sequencing artefacts were removed using TagDust (v1.0)1 Processed reads were then aligned against the human genome hg38 using STAR (v.2.4.1). On average, 16,306,077 could be uniquely mapped per sample (76% uniquely mapped on average reads per sample). CAGE detected TSS (CTSS) files were created using CAGEr (v1.10.0). With CAGEr, we removed the first G nucleotide if it was a mismatch. CTSS were clustered using the ‘distclu’ method with a maximum distance of 20 bp. For exact commands used we refer to the reader to the scripts used in this pipeline: https://github.com/dznetubingen/cageseq-pipeline-mf. In total, we could identify 47,298 different peaks. Data was normalized to counts per million (CPM) for visualization on the website.
本数据集源自RiMod-FTD数据库(https://www.rimod-ftd.org/)的额叶CAGE-seq数据聚类计数表。
数据处理流程如下:使用Skewer(版本0.1.126)对CAGE-seq的FastQ文件中的测序接头与条形码序列进行剪切修剪;随后利用TagDust(版本1.0)去除测序伪影。经预处理的读段已通过STAR(版本2.4.1)比对至人类参考基因组hg38,每个样本平均可获得16,306,077条唯一比对读段,平均唯一比对率达76%。
借助CAGEr(版本1.10.0)生成CAGE检测的转录起始位点(Transcription Start Site, TSS)文件(又称CTSS文件),在该分析流程中,若首碱基G存在错配则将其剔除。随后采用‘distclu’聚类算法对CTSS进行聚类,聚类最大间距设置为20 bp。
如需获取本流程所用的具体命令,请参考配套分析脚本:https://github.com/dznetubingen/cageseq-pipeline-mf。本研究共鉴定得到47,298个不同的转录峰。为便于在网站上进行可视化展示,数据已标准化为每百万计数(CPM, counts per million)。
提供机构:
figshare
创建时间:
2022-10-22
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集提供了前额叶CAGE-seq数据的簇计数表,经过严格的序列处理和比对分析,识别出47,298个不同的转录起始位点峰,并以每百万计数(CPM)标准化,适用于转录组学和基因组学研究。
以上内容由遇见数据集搜集并总结生成


