Face4FairShifts
收藏Hugging Face2025-05-19 更新2025-05-20 收录
下载链接:
https://huggingface.co/datasets/LYM619/Face4FairShifts
下载链接
链接失效反馈官方服务:
资源简介:
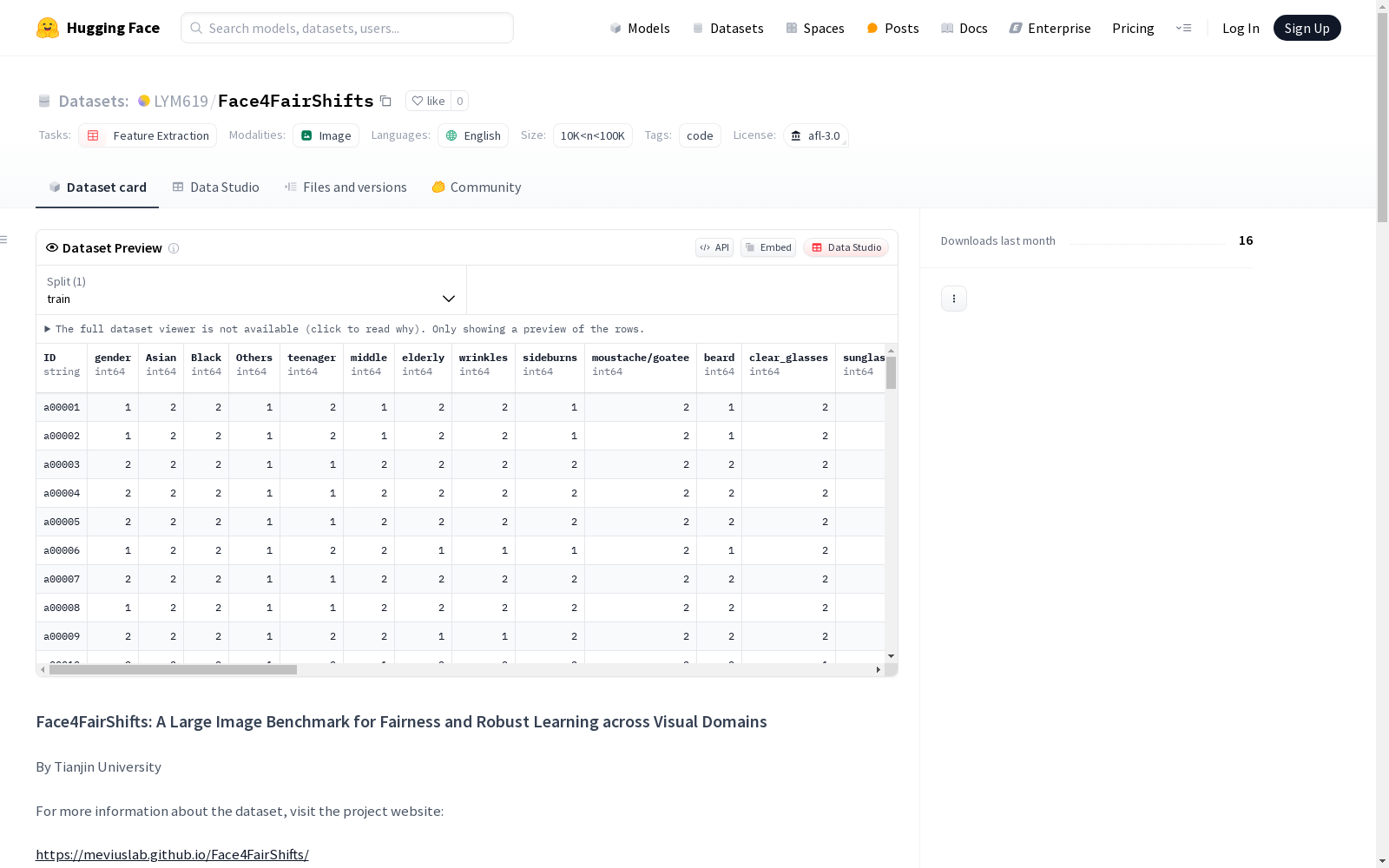
Face4FairShifts是一个由天津大学创建的大型图像数据集,旨在为公平性和跨视觉域的鲁棒学习提供基准。该数据集包含10万张原始人脸图像,跨越四个领域:照片、艺术、卡通和草图。此外,数据集还提供了42种属性的标注信息,包括与公平性相关的敏感属性(如性别、种族、年龄)以及详细的面部特征(如胡须、眼镜、眼睛、嘴巴、笑容、鼻子、下巴、头发、辫子、配饰等)和主观特征(如吸引力)。
创建时间:
2025-05-19
原始信息汇总
Face4FairShifts 数据集概述
基本信息
- 许可证: AFL-3.0
- 任务类别: 特征提取
- 语言: 英语
- 标签: 代码
- 数据集名称: LYM619/Face4FairShifts
- 规模: 10K < n < 100K
数据集描述
Face4FairShifts 是一个大型图像基准数据集,旨在支持公平性和鲁棒性学习在不同视觉领域中的应用。数据集由天津大学开发,仅限非商业研究和教育用途。
文件信息
面部图像 (Img/)
- Photo.zip: 30,000 张照片
- Art.zip: 25,000 张艺术图像
- Cartoon.zip: 25,000 张卡通图像
- Sketch.zip: 20,000 张素描图像
- 总计: 100,000 张原始面部图像
属性标注 (Anno/)
- photo_attr.json
- art_attr.json
- cartoon_attr.json
- sketch_attr.json
- 标注内容: 42 个标注项,涵盖 15 个属性,包括性别、种族、年龄等敏感属性,以及详细的面部特征和主观特征(如吸引力)。
属性描述
主要属性
- 性别: 男性 (1), 女性 (2)
- 种族: 亚洲人 (1), 黑人 (2), 其他 (2)
- 年龄: 青少年 (1), 中年 (2), 老年 (3)
- 外貌: 有吸引力 (1), 一般 (2), 无吸引力 (3)
面部特征
- 胡须: 包括络腮胡、山羊胡等
- 眼镜: 包括透明眼镜和太阳镜
- 眼睛: 睁眼、眉毛可见
- 嘴巴: 张嘴、露齿
- 微笑: 闭唇微笑、开唇微笑
- 耳朵: 可见、耳环
- 鼻子: 尖鼻、圆鼻
- 下巴: 尖下巴、圆下巴
- 头发: 秃头、稀疏头发、短发、长发、直发、卷发、刘海
- 辫子: 单辫、多辫
- 头饰: 帽子、其他头饰
使用限制
- 用途限制: 仅限非商业研究和教育用途
联系方式
- 联系人: Yumeng Lin (lym619@tju.edu.cn)
项目网站
https://meviuslab.github.io/Face4FairShifts/
搜集汇总
数据集介绍
构建方式
Face4FairShifts数据集构建于多模态视觉领域,旨在促进公平性与鲁棒性学习研究。该数据集精心收集了10万张人脸图像,涵盖照片、艺术画、卡通和素描四种视觉域,分别包含30,000、25,000、25,000和20,000张图像。每张图像均标注了42维属性,包括性别、种族、年龄等敏感属性,以及眼镜、发型等细粒度面部特征,所有标注均采用标准化编码体系进行规范化处理。
特点
该数据集最显著的特点是跨域视觉表征的多样性,四种不同风格的人脸图像为域适应研究提供了天然实验场景。标注体系包含15类共42个属性,其中主观审美评价与客观生物特征并存,为多任务学习创造了条件。数据分布上刻意保持各域的样本量差异,模拟现实世界中的长尾分布现象,特别适合研究算法在数据不平衡场景下的公平性表现。
使用方法
研究者可通过解压Photo/Art/Cartoon/Sketch四个压缩包获取原始图像,配套的属性标注以JSON格式存储,包含详细的二进制编码说明。典型应用场景包括:使用跨域图像验证模型鲁棒性,基于敏感属性分析算法偏差,或联合多属性进行细粒度人脸分析。需注意根据license要求,该数据集仅限非商业研究和教育用途,使用时需遵守项目网站规定的伦理准则。
背景与挑战
背景概述
Face4FairShifts数据集由天津大学研究团队开发,旨在为公平性和鲁棒性学习提供跨视觉领域的大规模图像基准。该数据集包含10万张人脸图像,覆盖照片、艺术、卡通和素描四个视觉领域,并标注了42种属性,涵盖性别、种族、年龄等敏感属性以及详细的面部特征。这一数据集的创建推动了计算机视觉领域在公平性、偏见缓解和跨域学习方面的研究,为算法在多元视觉环境中的泛化能力提供了重要评估工具。
当前挑战
Face4FairShifts数据集面临的核心挑战包括跨域视觉表征的一致性学习与公平性保障。具体而言,不同视觉领域(如照片与素描)间的特征分布差异显著,增加了模型跨域泛化的难度;同时,敏感属性标注的精细度要求模型在避免偏见的同时保持高分类性能。构建过程中的挑战则体现在大规模多域数据的采集与清洗,以及主观属性(如吸引力评分)的标准化标注,需平衡标注者主观性与数据客观性。
常用场景
经典使用场景
在计算机视觉与机器学习领域,Face4FairShifts数据集因其跨域特性与丰富的标注信息,成为研究公平性与鲁棒性学习的经典基准。该数据集通过整合照片、艺术画、卡通和素描四种视觉域的人脸图像,为跨域特征迁移、域适应算法验证提供了标准化测试平台。研究者常利用其多模态特性探索模型在不同视觉风格下的泛化能力,特别是在处理风格迁移与域偏移问题时,该数据集能够有效验证算法在保持公平性前提下的跨域性能。
衍生相关工作
基于该数据集衍生的研究包括跨域公平性度量框架FairCross、基于风格解耦的偏见缓解方法StyleDebias等经典工作。在CVPR等顶会上,多篇论文采用其多域特性验证域不变特征学习算法,如对抗域适应网络AD-Fair和元学习框架MetaFair。这些工作显著推动了视觉计算与社会计算领域的交叉创新。
数据集最近研究
最新研究方向
随着人工智能在视觉领域的广泛应用,公平性和鲁棒性成为研究热点。Face4FairShifts数据集凭借其跨域人脸图像和丰富的敏感属性标注,为公平性和鲁棒学习提供了重要基准。当前研究聚焦于跨域泛化能力的提升,探索不同视觉域(如照片、艺术、卡通和素描)间的特征不变性。同时,该数据集推动了基于敏感属性(如性别、种族和年龄)的公平性算法评估,助力消除模型偏见。此外,结合主观特征(如吸引力)的鲁棒性研究也备受关注,为构建更具包容性的人工智能系统提供了数据支持。
以上内容由遇见数据集搜集并总结生成


