uv-scripts/build-atlas
收藏Hugging Face2026-04-04 更新2025-09-13 收录
下载链接:
https://hf-mirror.com/datasets/uv-scripts/build-atlas
下载链接
链接失效反馈官方服务:
资源简介:
本数据集是一个工具,用于生成和部署交互式嵌入可视化到HuggingFace Spaces。它支持从HuggingFace Hub加载数据集,生成或使用预计算的嵌入,并创建静态Web应用以展示数据。
This dataset is a tool for generating and deploying interactive embedding visualizations to HuggingFace Spaces. It supports loading datasets from HuggingFace Hub, generating or using pre-computed embeddings, and creating static web applications to display the data.
提供机构:
uv-scripts
搜集汇总
数据集介绍
构建方式
在数据可视化领域,构建大规模嵌入空间的可交互探索工具对理解高维数据分布至关重要。该数据集通过集成Apple开源的Embedding Atlas库,并设计了一套端到端的自动化流水线,实现了从原始数据到可视化空间的快速转换。其构建过程依托HuggingFace的存储桶、任务作业和空间服务,首先创建存储桶以托管数据,随后提交GPU任务进行高效的嵌入计算与UMAP降维,最终部署为可交互的Docker空间,整个过程支持百万级数据点的实时渲染与检索。
特点
该数据集工具集的核心特点在于其高度优化的处理流程与灵活的部署选项。它充分利用GPU加速技术,通过cuml.accel实现UMAP降维的数十倍速度提升,显著降低了大规模数据集的处理时间成本。同时,工具支持多种输入格式,包括HuggingFace数据集、Parquet分片、Lance格式以及预计算嵌入,并允许通过文本或图像列生成嵌入。其架构设计实现了计算与可视化的分离,轻量级查看器通过HTTP范围请求按需获取远程数据,既保证了交互性能,又避免了本地存储的负担。
使用方法
用户可通过提供的多种脚本适配不同规模与需求的数据可视化任务。对于快速原型验证,可使用`atlas-export.py`脚本一键完成从数据集加载到空间部署的全过程。面对海量数据,推荐采用基于存储桶的流水线,先通过`atlas-build-gpu.py`在GPU任务中高效生成嵌入与降维结果并写入存储桶,再使用`atlas-deploy.py`部署可视化空间。工具支持丰富的参数配置,如指定嵌入模型、数据列、采样数量以及隐私设置,并能处理经过DuckDB预处理或过滤的增强数据,为多维数据的探索分析提供了强大而便捷的解决方案。
背景与挑战
背景概述
Embedding Atlas 是由苹果公司开发的开源库,旨在通过 WebGPU 加速技术,为高维嵌入空间创建交互式、基于浏览器的可视化呈现。该库能够渲染数百万数据点,支持实时搜索与过滤,并自动生成聚类标签。build-atlas 数据集作为配套工具集,由 Hugging Face 社区的 uv-scripts 团队维护,其核心研究问题聚焦于如何高效地将大规模数据集转化为直观的可视化空间,从而帮助研究人员深入理解嵌入向量的分布与结构。这一工具集通过整合存储桶、计算任务与部署空间,显著降低了构建交互式嵌入可视化的技术门槛,对机器学习、自然语言处理及计算机视觉等领域的数据探索与分析流程产生了积极影响。
当前挑战
构建大规模嵌入可视化系统面临多重挑战。在领域问题层面,核心挑战在于如何对海量高维嵌入数据进行有效的降维与可视化,同时保持数据的局部与全局结构,并实现低延迟的交互式探索。在构建过程中,技术挑战尤为突出:处理数百万级数据点时,传统的 CPU 降维算法如 UMAP 计算耗时极长,难以满足实际应用需求;此外,如何将生成的可视化数据高效部署并提供稳定的远程访问,同时管理存储与计算资源成本,也是构建流程中需要解决的关键问题。
常用场景
经典使用场景
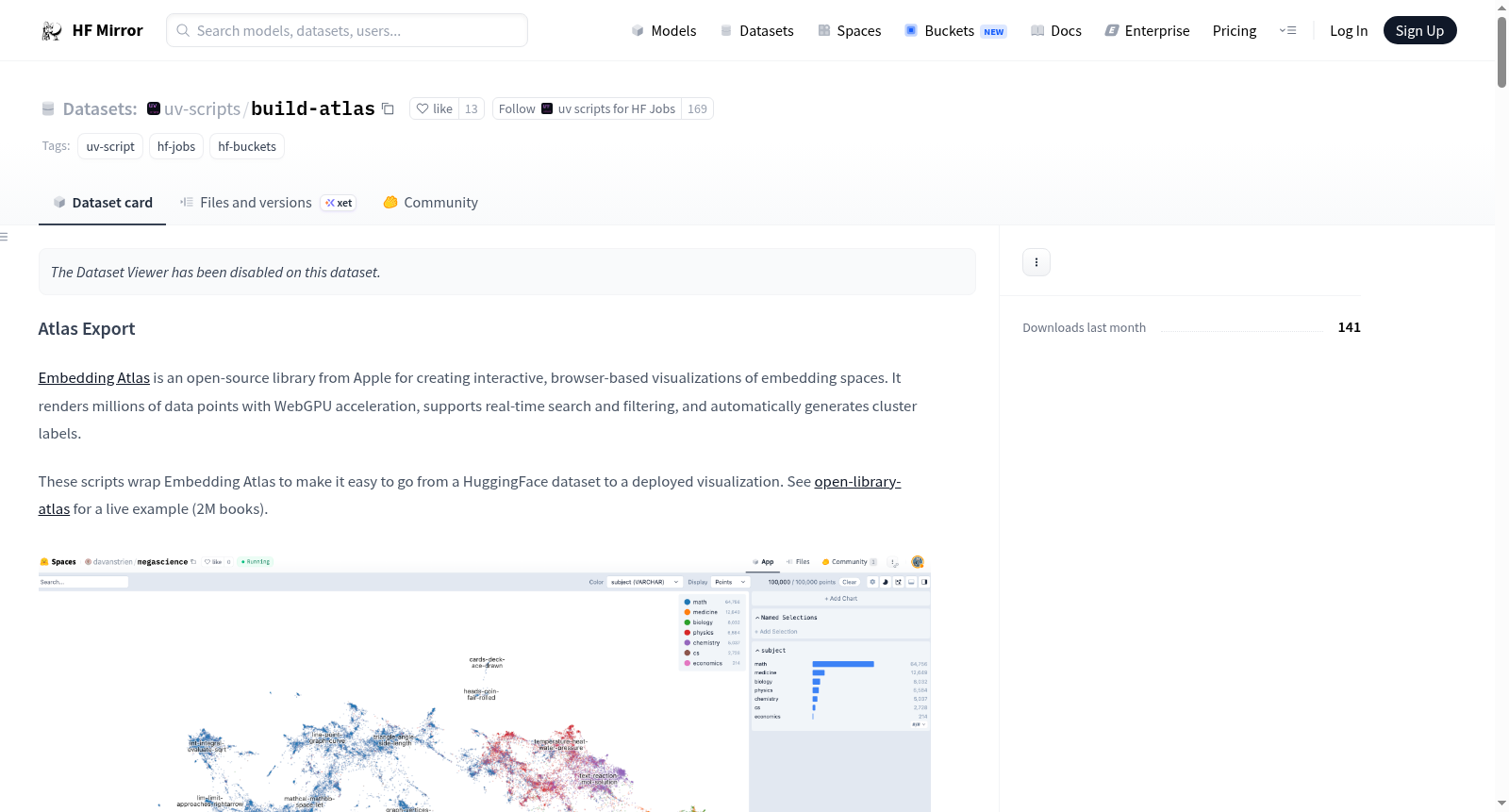
在数据可视化与探索性分析领域,build-atlas数据集工具集的核心应用场景在于为大规模嵌入向量提供交互式可视化解决方案。通过集成Apple开源的Embedding Atlas库,该工具能够将数百万数据点以WebGPU加速方式渲染成浏览器可交互的二维投影图,典型案例如对IMDB影评数据集进行语义空间映射,研究者可直观观察文本情感分布的聚类特征与异常值,实现从抽象向量到视觉模式的直接转换。
实际应用
在实际工业应用中,该工具集被广泛部署于大规模数据质量监控与知识图谱可视化场景。科技企业利用其流水线架构,可将千万级商品描述文本或用户行为序列嵌入投影至二维空间,运营团队通过实时筛选功能快速识别语义异常区域。例如在内容审核系统中,管理员可通过交互式界面定位敏感话题聚集区域;在学术出版领域,机构能够可视化展示海量论文的学科交叉网络,辅助科研决策。
衍生相关工作
基于该工具集的范式,衍生出多项经典研究工作与开源项目。Open Library Atlas项目实现了200万图书元数据的多维可视化,开创了文化遗产数字化展示的新模式;Nemotron-v3-Atlas工作则聚焦于大语言训练数据的质量评估,通过可视化暴露数据分布偏差。这些衍生工作共同推动了交互式机器学习可视化范式的标准化,催生了诸如Lance格式数据集直接可视化、GPU加速UMAP流水线等技术创新生态。
以上内容由遇见数据集搜集并总结生成


