local-deep-research/ldr-benchmarks
收藏Hugging Face2026-04-10 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/local-deep-research/ldr-benchmarks
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-4.0
task_categories:
- question-answering
language:
- en
tags:
- benchmark
- local-deep-research
- ldr
- simpleqa
- browsecomp
- xbench
- rag
- search
pretty_name: LDR Community Benchmarks
size_categories:
- n<1K
configs:
- config_name: all
data_files: leaderboards/all.csv
default: true
- config_name: simpleqa
data_files: leaderboards/simpleqa.csv
- config_name: browsecomp
data_files: leaderboards/browsecomp.csv
- config_name: xbench-deepsearch
data_files: leaderboards/xbench-deepsearch.csv
---
# LDR Community Benchmarks (Leaderboards)
Aggregated leaderboards for Local Deep Research (LDR) community benchmark
runs against SimpleQA, BrowseComp, and xbench-DeepSearch.
## 👉 Submit results, read raw YAMLs, open PRs:
## **[github.com/LearningCircuit/ldr-benchmarks](https://github.com/LearningCircuit/ldr-benchmarks)**
This Hugging Face dataset hosts **only the aggregated CSV leaderboards**.
It is regenerated automatically on every merge to `main` in the GitHub
repo above. Each CSV row represents one benchmark run (one strategy from
one YAML submission).
## Why the split?
- **GitHub** is the source of truth for raw YAML submissions, PR review,
CI validation, and leaderboard regeneration.
- **Hugging Face** renders the aggregated CSVs in its Dataset Viewer and
makes the leaderboards discoverable inside the ML community.
Raw per-run YAMLs — including configuration details, notes, and (where
permitted by the benchmark's sharing policy) per-question examples — live
in the GitHub repo under `results/`.
## Benchmarks covered
- **SimpleQA** — OpenAI, MIT-licensed. Full per-question examples allowed
in raw YAMLs on GitHub.
- **BrowseComp** — OpenAI, encrypted dataset with canary string. Only
aggregate metrics are accepted (no per-question examples in raw YAMLs).
- **xbench-DeepSearch** — xbench team, encrypted dataset. Only aggregate
metrics are accepted (no per-question examples in raw YAMLs).
See the GitHub repo's README for the full sharing policy.
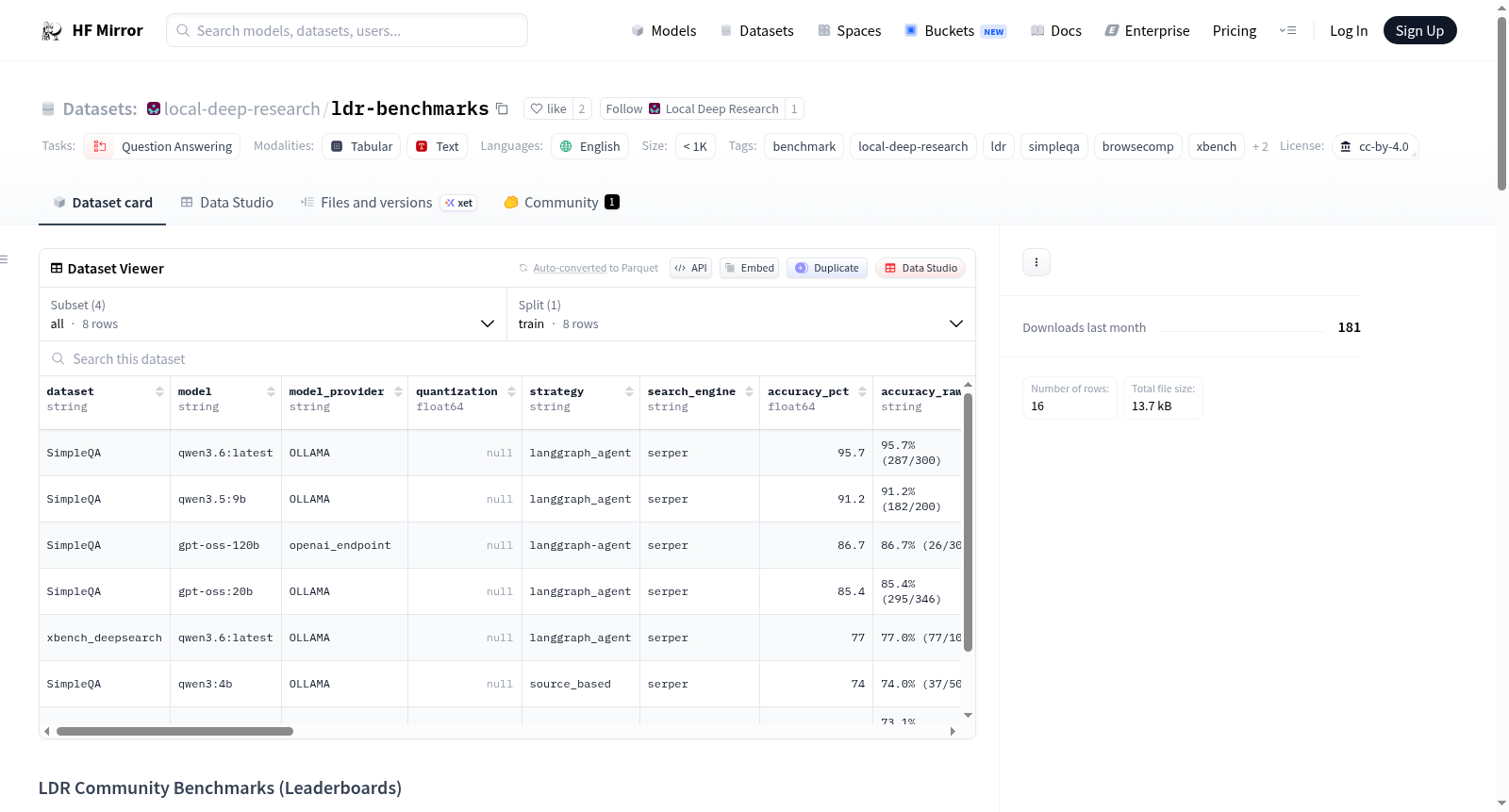
## Leaderboard columns
Each CSV row contains:
`dataset, model, model_provider, quantization, strategy, search_engine,
accuracy_pct, accuracy_raw, correct, total, iterations,
questions_per_iteration, avg_time_per_question, total_tokens_used,
temperature, context_window, max_tokens, hardware_gpu, hardware_ram,
hardware_cpu, evaluator_model, evaluator_provider, ldr_version,
date_tested, contributor, notes, source_file`
The `source_file` column points at the raw YAML in the GitHub repo.
## Configs
Use the dropdown at the top of the Dataset Viewer to switch between:
- `all` — every run, all benchmarks combined (default)
- `simpleqa` — SimpleQA runs only
- `browsecomp` — BrowseComp runs only
- `xbench-deepsearch` — xbench-DeepSearch runs only
## Considerations for using the data
This is a community-submitted leaderboard, not a controlled experiment.
Keep these caveats in mind when interpreting results:
- **Self-reported.** Runs are submitted by contributors. CI validates
schema and flags obvious issues, but the runs themselves are not
independently re-executed.
- **Evaluator bias.** Many submissions use an LLM grader (default is
Claude 3.7 Sonnet via OpenRouter). LLM evaluators have non-trivial
error rates; a manual audit of ~200 SimpleQA questions commonly
surfaces one or two grading mistakes.
- **Small sample sizes.** Many runs use 50–200 questions. Confidence
intervals at that scale are wide (roughly ±5–7 percentage points at
n=200). Small differences between rows are usually not significant.
- **Timing is environment-dependent.** `avg_time_per_question` depends on
hardware, network latency, search engine responsiveness, and model
server load.
- **Contamination risk.** SimpleQA is publicly distributed and may
appear in some models' training data. BrowseComp and xbench mitigate
this with encryption, but older model generations may still be
contaminated.
- **Strategy semantics drift.** LDR strategies evolve between versions.
Prefer comparing runs tagged with the same `ldr_version`.
## Attribution
- **SimpleQA** © OpenAI — [MIT License](https://github.com/openai/simple-evals/blob/main/LICENSE)
- **BrowseComp** © OpenAI — see the [BrowseComp paper](https://cdn.openai.com/pdf/5e10f4ab-d6f7-442e-9508-59515c65e35d/browsecomp.pdf)
and [openai/simple-evals](https://github.com/openai/simple-evals)
- **xbench** © xbench team — see [xbench-ai/xbench-evals](https://github.com/xbench-ai/xbench-evals)
Plain-text distribution of BrowseComp and xbench questions or answers
is prohibited.
## Contributors
<!-- CONTRIBUTORS:START -->
Thanks to everyone who has contributed benchmark runs:
- **LearningCircuit** — 2 submissions
- **kwhyte7** — 1 submission
<!-- CONTRIBUTORS:END -->
## Citation
```bibtex
@misc{ldr_community_benchmarks,
title = {LDR Community Benchmarks},
author = {The Local Deep Research community},
year = {2026},
publisher = {Hugging Face / GitHub},
howpublished = {\url{https://huggingface.co/datasets/local-deep-research/ldr-benchmarks}}
}
```
## License
This dataset is licensed under
[Creative Commons Attribution 4.0 International (CC BY 4.0)](https://creativecommons.org/licenses/by/4.0/).
If you use the data in research, publications, or derivative analyses,
please cite it using the BibTeX entry above.
Individual benchmark datasets (SimpleQA, BrowseComp, xbench) retain
their own upstream licenses — see the *Attribution* section.
提供机构:
local-deep-research
搜集汇总
数据集介绍
构建方式
在本地深度研究领域,该数据集通过社区协作的方式构建,其核心机制依赖于GitHub仓库作为原始提交的权威来源。社区成员以YAML格式提交基准测试运行结果,涵盖模型配置、评估指标及运行环境等详细信息。每次提交均经过持续集成流程的自动化验证,确保数据格式的合规性。每当GitHub主分支合并新的提交时,系统会自动重新聚合所有有效数据,生成结构化的CSV排行榜,并同步至Hugging Face平台,从而形成动态更新的公开基准。
特点
该数据集作为社区驱动的基准测试聚合平台,其显著特征在于整合了多个权威评估任务,包括SimpleQA、BrowseComp与xbench-DeepSearch。数据集以多维度的CSV表格呈现,每一行记录代表一次完整的基准测试运行,详尽收录了模型提供商、量化策略、搜索引擎、准确率、硬件配置及评估模型等数十项元数据。特别值得注意的是,数据集通过加密与许可限制,妥善处理了不同基准的数据公开性问题,并在设计上明确区分了汇总指标与原始细节的存储位置,兼顾了社区协作的开放性与数据使用的规范性。
使用方法
研究者可通过Hugging Face数据集查看器直接访问该资源,并利用顶部的配置下拉菜单,灵活选择查看全部基准或聚焦于单一任务(如SimpleQA)的排行榜。数据集中的每一行数据均关联至GitHub仓库中的原始YAML文件,便于深度追溯实验细节。在使用时,需审慎考虑数据特性:由于结果基于社区自报告且样本量有限,直接比较不同运行间的微小差异可能缺乏统计显著性。建议在相同LDR版本和相似硬件条件下进行对比分析,并注意不同基准的评估协议与数据污染风险,以得出稳健的研究结论。
背景与挑战
背景概述
在检索增强生成与本地深度研究技术快速演进的背景下,LDR社区基准数据集应运而生,旨在系统评估不同模型与策略在复杂问答及网络浏览任务上的性能。该数据集由LearningCircuit等社区贡献者于2026年发起并维护,其核心研究问题聚焦于如何量化比较各类本地深度研究策略在真实信息检索场景下的准确性与效率。通过整合SimpleQA、BrowseComp及xbench-DeepSearch等多个权威基准,该数据集为研究人员提供了一个公开、可复现的评估平台,显著推动了RAG系统与智能代理领域的标准化进程与技术创新。
当前挑战
该数据集致力于解决复杂开放域问答与多步网络信息检索任务的评估挑战,其核心难点在于如何设计能够准确反映模型深层推理与实时信息整合能力的评测标准。在构建过程中,数据集面临多重挑战:首先,需协调不同基准(如SimpleQA、BrowseComp、xbench)的许可协议与数据加密要求,确保合规分发;其次,社区提交的结果存在自我报告偏差,且依赖LLM评估器可能引入评分误差;此外,样本规模有限导致统计置信区间宽泛,而策略版本迭代与模型训练数据污染风险进一步增加了跨实验比较的复杂性。
常用场景
经典使用场景
在检索增强生成(RAG)与本地深度研究(LDR)领域,该数据集作为社区基准测试的聚合平台,其经典使用场景在于系统性地评估不同模型与策略在复杂问答任务上的性能。研究者通过整合SimpleQA、BrowseComp和xbench-DeepSearch等多个权威基准,能够横向比较各类模型在准确性、响应时间及资源消耗等维度的表现,从而为优化LDR框架提供实证依据。
解决学术问题
该数据集有效应对了RAG系统中模型评估标准化不足的学术挑战。通过汇集社区提交的多样化运行结果,它为解决模型污染风险、评估偏差以及小样本统计显著性等问题提供了透明化的数据基础。其意义在于促进了开放、可复现的评估生态,推动了深度研究策略的迭代与验证,为学术界建立更稳健的评估范式贡献了关键资源。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在评估方法学与策略创新层面。社区基于其公开的提交结果,发展了针对LLM评估偏差的校正技术,以及跨版本策略语义漂移的对比分析框架。此外,许多研究利用其聚合数据探索了搜索引擎集成、上下文窗口优化等方向,进一步推动了本地深度研究工具链的成熟与普及。
以上内容由遇见数据集搜集并总结生成


