MTMask6M
收藏arXiv2025-03-18 更新2025-03-20 收录
下载链接:
https://github.com/PriNing/Marten
下载链接
链接失效反馈官方服务:
资源简介:
MTMask6M数据集是由美团、上海交通大学和北京理工大学联合构建的大规模图像-文本掩膜对数据集,包含600万条图像-文本掩膜对。该数据集通过一个创新的图像-文本对齐方法VQAMask构建,旨在为视觉文档理解任务提供空间感知的特征表示学习。数据集的构建过程中,使用了聚类算法对文本区域进行二值化处理,并通过掩膜生成模块来确保图像中的视觉文本与其对应的图像区域在空间上对齐。该数据集的应用领域主要是为了解决视觉文档理解中的空间对齐问题,提升模型在文档理解任务上的性能。
The MTMask6M dataset is a large-scale image-text mask pair dataset jointly constructed by Meituan, Shanghai Jiao Tong University, and Beijing Institute of Technology, which contains 6 million image-text mask pairs. Constructed via an innovative image-text alignment method named VQAMask, this dataset aims to provide spatially-aware feature representation learning for visual document understanding tasks. During its construction process, clustering algorithms are used to binarize text regions, and a mask generation module is employed to ensure the spatial alignment between visual text in the image and its corresponding image region. The main application scenario of this dataset is to address the spatial alignment issue in visual document understanding, thereby improving the performance of models on document understanding tasks.
提供机构:
美团, 上海交通大学, 北京理工大学
创建时间:
2025-03-18
搜集汇总
数据集介绍
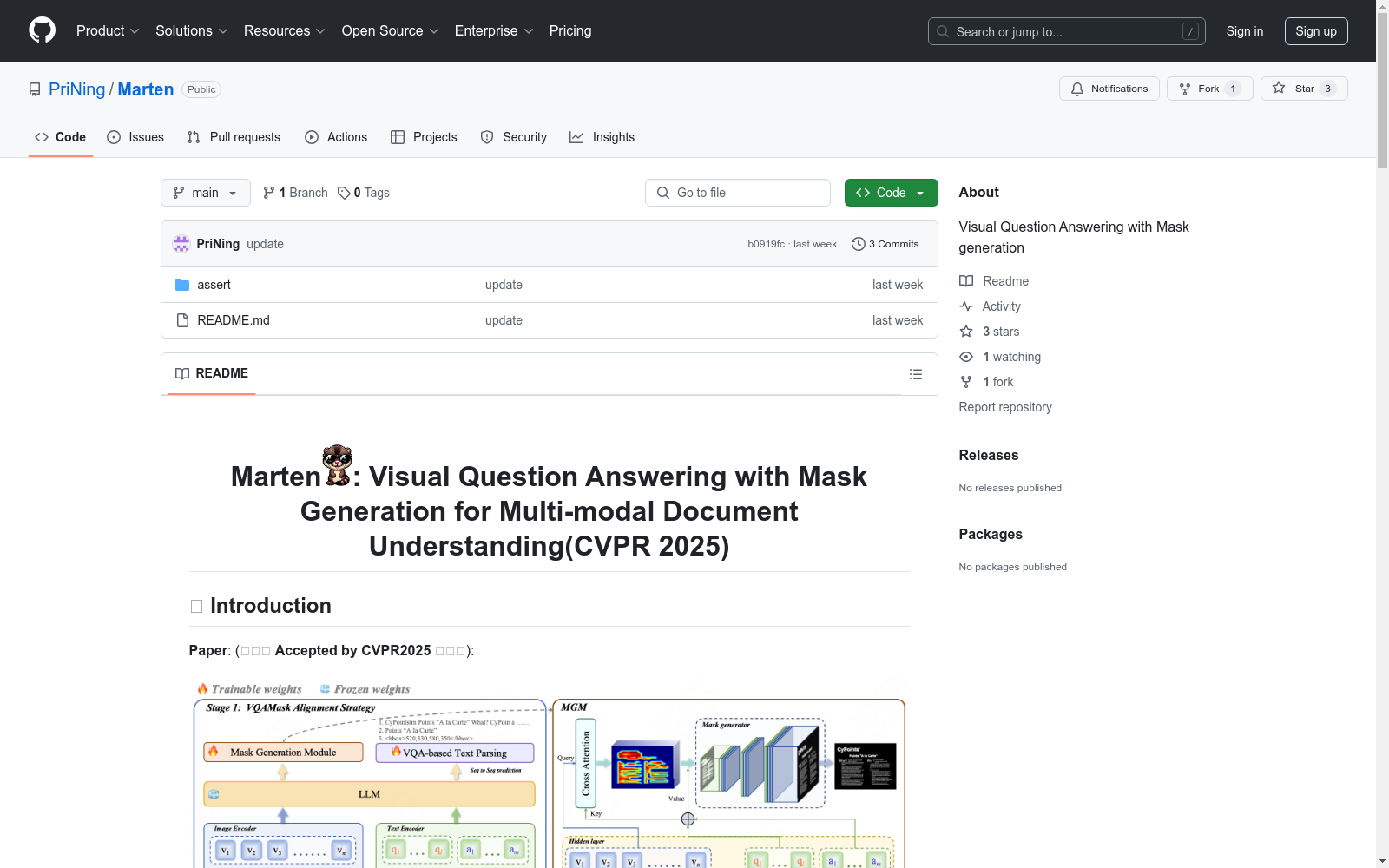
构建方式
MTMask6M数据集的构建基于一种创新的视觉-语言对齐方法,即带有掩码生成的视觉问答(VQAMask)任务。该方法通过同时优化基于视觉问答的文本解析和掩码生成任务,实现了图像与文本在语义和空间感知层面的对齐。具体而言,数据集的构建过程包括使用PaddleOCR检测图像中的文本区域,并通过K-means聚类方法生成文本掩码。最终,数据集包含了600万张图像-掩码对,涵盖了文档、表格、图表等多种形式的图像。
特点
MTMask6M数据集的特点在于其大规模和高多样性。数据集不仅包含了丰富的文档图像,还通过掩码生成任务引入了空间感知的监督信号,使得模型能够在解析视觉文本时避免幻觉现象。此外,数据集的构建过程完全自动化,无需人工标注,确保了数据的高效生成和广泛适用性。数据集的多模态特性使其特别适用于视觉文档理解任务,尤其是在需要同时处理图像和文本的场景中。
使用方法
MTMask6M数据集的使用方法主要围绕视觉-语言对齐任务展开。在训练阶段,模型通过VQAMask任务同时进行视觉问答和掩码生成,以增强图像与文本的对齐能力。掩码生成任务在推理阶段被丢弃,因此不会增加额外的计算成本。数据集可用于训练多模态大语言模型(MLLM),如Marten模型,以提升其在文档理解任务中的表现。具体使用时,用户可以通过加载数据集并配置相应的训练任务,结合视觉编码器和语言模型进行联合优化。
背景与挑战
背景概述
MTMask6M数据集由美团与上海交通大学等机构的研究团队于2025年提出,旨在解决多模态大语言模型(MLLMs)在文档理解中的视觉与语言模态对齐问题。该数据集的核心研究问题是通过视觉问答与掩码生成任务(VQAMask)来优化文档级别的视觉文本解析与空间对齐。MTMask6M包含600万图像-掩码对,支持模型在语义和空间感知层面进行特征表示学习。该数据集的提出显著提升了多模态文档理解的性能,尤其在文档、表格、图表等复杂场景下的文本解析任务中表现突出。
当前挑战
MTMask6M数据集面临的挑战主要包括两个方面。首先,在领域问题方面,文档图像中的文本通常具有高分辨率、密集排版和多样化的形式,这增加了视觉文本解析的难度。现有的方法主要依赖语义对齐,缺乏对文本空间位置的显式监督,容易导致模型幻觉。其次,在数据集构建过程中,生成高质量的掩码标签是一个关键挑战。研究团队通过设计自动化的掩码生成流水线,避免了手动标注的高成本,但仍需确保掩码的准确性和一致性,以支持模型的空间感知学习。
常用场景
经典使用场景
MTMask6M数据集在多模态文档理解领域具有广泛的应用,尤其是在视觉问答(VQA)与掩码生成任务中。该数据集通过结合视觉与语言模态,支持模型在文档图像中同时进行文本解析和掩码生成,从而提升模型对文档内容的空间感知能力。经典使用场景包括文档图像中的文本识别、表格解析、图表理解等任务,模型能够通过视觉问答任务隐式地对齐图像与文本的语义信息,并通过掩码生成任务显式地对齐图像中的文本区域与对应的视觉特征。
实际应用
MTMask6M数据集在实际应用中具有广泛的价值,特别是在需要处理复杂文档的场景中。例如,在金融、医疗和法律领域,文档通常包含大量的表格、图表和公式,MTMask6M支持的模型能够高效地提取这些结构化信息,并将其转换为可编辑的格式(如Markdown、LaTeX或CSV)。此外,该数据集还可用于自动化文档处理系统,帮助用户快速定位和提取关键信息,提升工作效率。
衍生相关工作
MTMask6M数据集推动了多模态文档理解领域的多项经典工作。基于该数据集,研究者提出了Marten模型,该模型通过结合视觉问答与掩码生成任务,显著提升了文档理解任务的性能。此外,MTMask6M还启发了其他相关工作,如KOSMOS-2.5的视觉文本定位任务、mPLUG-DocOWL的结构感知文档解析任务等。这些工作进一步扩展了多模态大语言模型在文档理解中的应用范围,推动了该领域的技术进步。
以上内容由遇见数据集搜集并总结生成


