有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
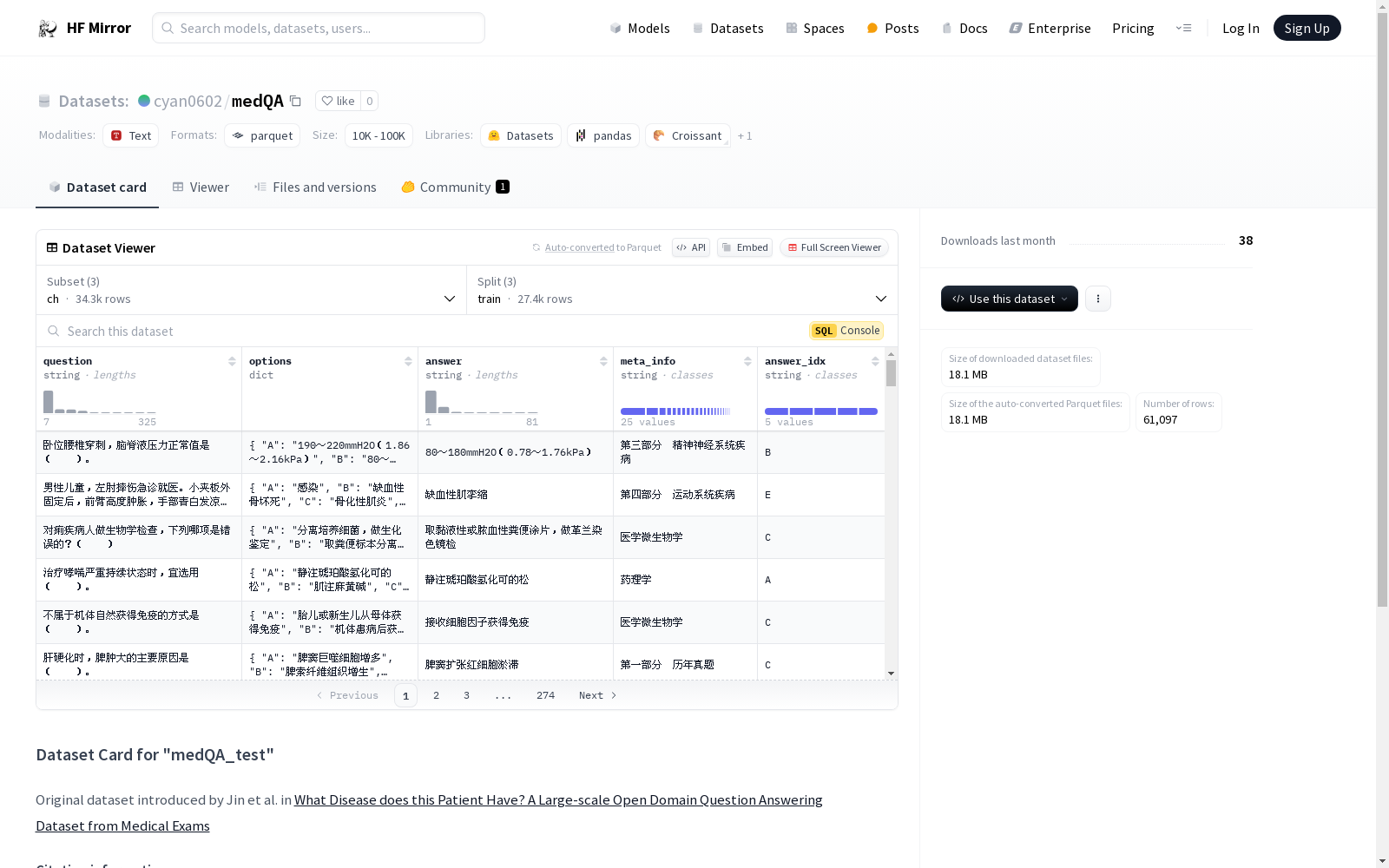
特征信息:
question: 数据类型为字符串。options: 结构化数据,包含选项A、B、C、D、E,每个选项的数据类型均为字符串。answer: 数据类型为字符串。meta_info: 数据类型为字符串。answer_idx: 数据类型为字符串。数据分割:
train: 大小为8541530字节,包含27400个样本。dev: 大小为1074279字节,包含3425个样本。test: 大小为1074680字节,包含3426个样本。下载大小: 7034515字节。
数据集大小: 10690489字节。
特征信息:
question: 数据类型为字符串。options: 结构化数据,包含选项A、B、C、D,每个选项的数据类型均为字符串。answer: 数据类型为字符串。meta_info: 数据类型为字符串。answer_idx: 数据类型为字符串。数据分割:
train: 大小为4410178字节,包含11298个样本。dev: 大小为553868字节,包含1412个样本。test: 大小为563240字节,包含1413个样本。下载大小: 4105642字节。
数据集大小: 5527286字节。
特征信息:
question: 数据类型为字符串。answer: 数据类型为字符串。options: 结构化数据,包含选项A、B、C、D、E,每个选项的数据类型均为字符串。meta_info: 数据类型为字符串。answer_idx: 数据类型为字符串。数据分割:
train: 大小为9470204字节,包含10178个样本。dev: 大小为1184039字节,包含1272个样本。test: 大小为1211382字节,包含1273个样本。下载大小: 6952745字节。
数据集大小: 11865625字节。
AISHELL/AISHELL-1
Aishell是一个开源的中文普通话语音语料库,由北京壳壳科技有限公司发布。数据集包含了来自中国不同口音地区的400人的录音,录音在安静的室内环境中使用高保真麦克风进行,并下采样至16kHz。通过专业的语音标注和严格的质量检查,手动转录的准确率超过95%。该数据集免费供学术使用,旨在为语音识别领域的新研究人员提供适量的数据。
hugging_face 收录
MedDialog
MedDialog数据集(中文)包含了医生和患者之间的对话(中文)。它有110万个对话和400万个话语。数据还在不断增长,会有更多的对话加入。原始对话来自好大夫网。
github 收录
Beijing Traffic
The Beijing Traffic Dataset collects traffic speeds at 5-minute granularity for 3126 roadway segments in Beijing between 2022/05/12 and 2022/07/25.
Papers with Code 收录
HIT-UAV
HIT-UAV数据集包含2898张红外热成像图像,这些图像从43,470帧无人机拍摄的画面中提取。数据集涵盖了多种场景,如学校、停车场、道路和游乐场,在不同的光照条件下,包括白天和夜晚。
github 收录
VisDrone2019
VisDrone2019数据集由AISKYEYE团队在天津大学机器学习和数据挖掘实验室收集,包含288个视频片段共261,908帧和10,209张静态图像。数据集覆盖了中国14个不同城市的城市和乡村环境,包括行人、车辆、自行车等多种目标,以及稀疏和拥挤场景。数据集使用不同型号的无人机在各种天气和光照条件下收集,手动标注了超过260万个目标边界框,并提供了场景可见性、对象类别和遮挡等重要属性。
github 收录