ccmusic-database/music_genre
收藏Hugging Face2026-02-27 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/ccmusic-database/music_genre
下载链接
链接失效反馈官方服务:
资源简介:
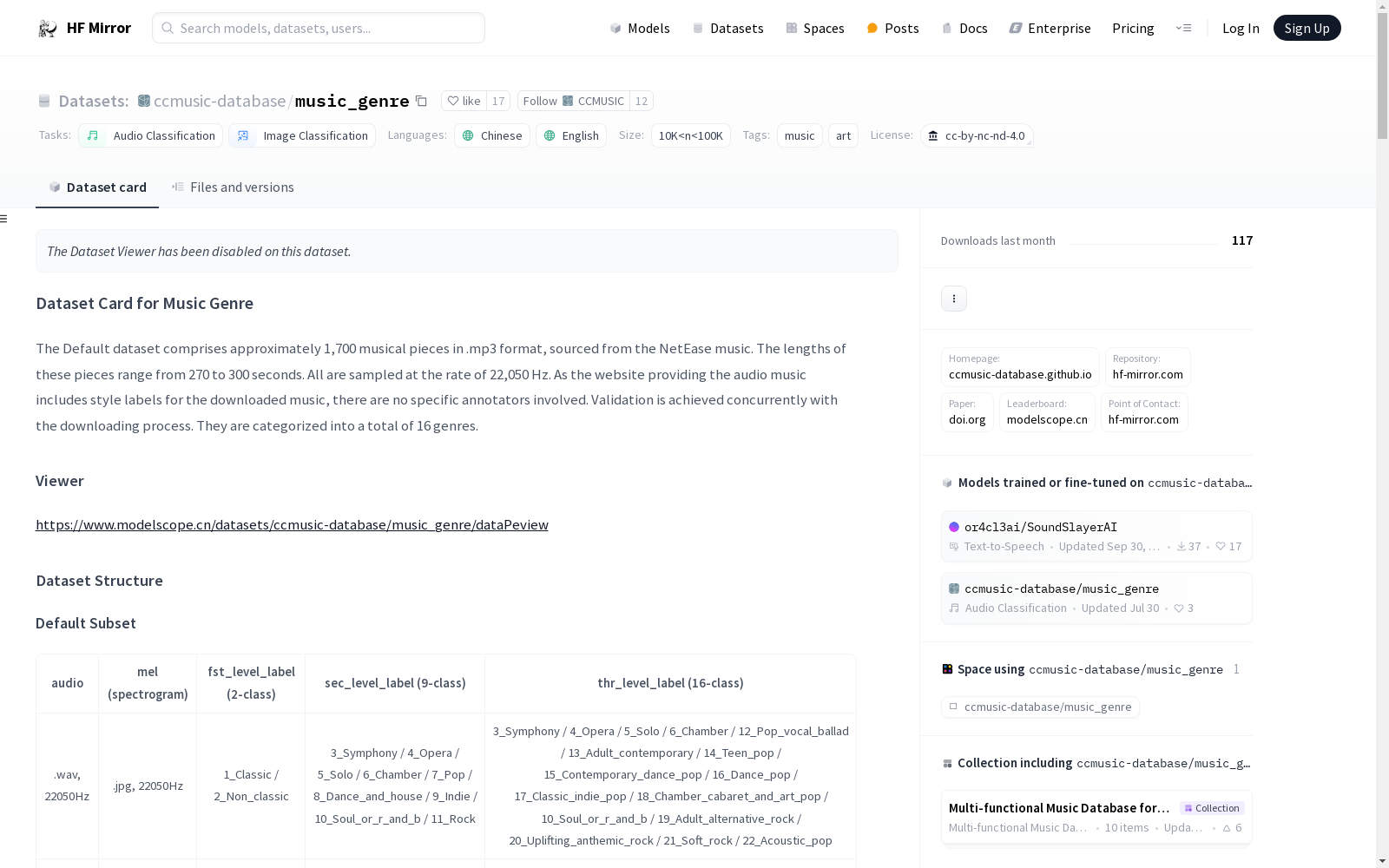
该数据集包含约1700首音乐片段,格式为.mp3,时长在270到300秒之间,采样率为22,050 Hz。这些音乐片段来自网易云音乐,并根据风格标签分为16种类型。数据集分为Raw Subset和Eval Subset,分别包含不同的音频特征和标签。数据集的创建目的是促进音乐行业AI的发展,主要由学生收集和标注。数据集的使用涉及音频分类任务,支持多语言。
该数据集包含约1700首音乐片段,格式为.mp3,时长在270到300秒之间,采样率为22,050 Hz。这些音乐片段来自网易云音乐,并根据风格标签分为16种类型。数据集分为Raw Subset和Eval Subset,分别包含不同的音频特征和标签。数据集的创建目的是促进音乐行业AI的发展,主要由学生收集和标注。数据集的使用涉及音频分类任务,支持多语言。
提供机构:
ccmusic-database
原始信息汇总
数据集概述
基本信息
- 名称: Music Genre Dataset
- 许可证: MIT
- 语言: 中文、英文
- 标签: 音乐、艺术
- 大小: 10K<n<100K
数据集描述
- 概述: 包含约1700首音乐作品,格式为.mp3,时长270至300秒,采样率22,050 Hz。这些音乐作品被分为16种不同的音乐风格。
- 来源: 数据源自NetEase音乐,音乐下载时已包含风格标签。
- 分类: 共16种音乐风格。
数据集结构
- 音频格式: .mp3
- 采样率: 22,050 Hz
- 时长范围: 270至300秒
- 标签体系: 三级分类,包括初级(2类)、中级(9类)和高级(16类)。
使用示例
- 加载数据集: 使用
load_dataset函数加载数据集,支持eval和default两种子集。 - 数据处理: 数据集包含训练、验证和测试集,支持音频分类任务。
数据集创建
- 采集与标注: 由CCMUSIC的学生收集并标注,共1700首音乐作品,分为17种风格。
- 版权处理: 由于版权问题,数据集中仅提供音乐的频谱图。
注意事项
- 语言偏差: 数据集中大部分为英文歌曲。
- 样本平衡: 数据集中的样本分布不够均衡。
许可证
- 类型: MIT License
- 版权所有者: CCMUSIC
- 使用条件: 允许免费使用、复制、修改、合并、发布、分发、转授权和销售软件副本,但需包含版权声明和许可声明。
引用信息
- 作者: Monan Zhou, Shenyang Xu, Zhaorui Liu, Zhaowen Wang, Feng Yu, Wei Li, Baoqiang Han
- 标题: CCMusic: an Open and Diverse Database for Chinese and General Music Information Retrieval Research
- 出版年: 2024
- 版本: 1.2
- URL: https://huggingface.co/ccmusic-database
搜集汇总
数据集介绍
构建方式
该数据集由约1,700首音乐片段组成,这些片段以.mp3格式存储,采样率为22,050 Hz,时长介于270至300秒之间。这些音乐片段源自NetEase音乐平台,并根据平台提供的风格标签进行分类。数据集的构建过程包括直接从平台下载音乐文件,并在下载过程中进行验证,确保标签的准确性。最终,这些音乐片段被分为16个不同的音乐流派。
特点
此数据集的显著特点在于其多层次的标签系统,包括两类、九类和十六类的音乐流派标签,这为音频分类任务提供了丰富的信息。此外,数据集还包含了音频文件的梅尔频谱图(mel spectrogram)、恒定Q变换(CQT)和色度图(chroma),这些特征图谱为音乐分析提供了多维度的视角。尽管数据集在流派分布上存在一定的不平衡,但其多样性和多语言支持(中文和英文)使其成为音乐信息检索和分类研究的宝贵资源。
使用方法
使用该数据集进行音乐流派分类任务时,用户可以通过HuggingFace的datasets库加载数据集。数据集分为默认子集(Default Subset)和评估子集(Eval Subset),每个子集都包含训练、验证和测试集。用户可以根据需要选择不同的子集进行加载,并通过遍历数据集的各个部分来获取音频文件及其对应的标签信息。此外,数据集还提供了详细的文档和示例代码,帮助用户快速上手并进行相关研究。
背景与挑战
背景概述
音乐流派的分类一直是音乐信息检索和人工智能领域的重要研究课题。ccmusic-database/music_genre数据集由Zhaorui Liu和Monan Zhou等研究人员于2024年创建,旨在推动音乐行业中AI技术的发展。该数据集包含了约1,700首时长为270至300秒的.mp3格式音乐片段,这些片段来源于网易云音乐,并被分类为16种不同的音乐流派。数据集的构建不仅为音乐流派的自动分类提供了丰富的资源,还为相关领域的研究提供了新的基准。
当前挑战
尽管ccmusic-database/music_genre数据集在音乐流派分类方面提供了宝贵的资源,但其构建过程中仍面临若干挑战。首先,数据集中的样本分布不均衡,某些流派的样本数量较少,这可能影响模型的泛化能力。其次,由于数据集主要包含英文歌曲,可能存在语言和文化偏见,限制了其在多语言环境中的应用。此外,数据集的标注过程依赖于学生收集和分类,可能引入人为误差。这些挑战需要在未来的研究中加以解决,以提升数据集的质量和应用范围。
常用场景
经典使用场景
在音乐信息检索领域,ccmusic-database/music_genre数据集被广泛用于音乐流派分类任务。该数据集包含约1,700首音乐片段,涵盖16种不同的音乐流派,为研究人员提供了丰富的音频和声谱图数据。通过这些数据,研究者可以训练和验证音乐流派分类模型,从而提升音乐信息检索系统的准确性和效率。
实际应用
在实际应用中,ccmusic-database/music_genre数据集被用于开发智能音乐推荐系统。通过分析用户的音乐偏好,系统可以推荐符合用户口味的音乐,提升用户体验。此外,该数据集还支持音乐版权管理,通过自动分类识别未经授权的音乐使用,保护音乐创作者的权益。
衍生相关工作
基于ccmusic-database/music_genre数据集,研究者们开发了多种音乐流派分类模型,如基于深度学习的卷积神经网络(CNN)和循环神经网络(RNN)。这些模型在音乐推荐、音乐情感分析和音乐版权管理等领域取得了显著成果。此外,该数据集还激发了关于音乐数据不平衡问题的研究,推动了数据增强和模型优化方法的发展。
以上内容由遇见数据集搜集并总结生成


