community-datasets/yahoo_answers_topics
收藏Hugging Face2024-06-24 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/community-datasets/yahoo_answers_topics
下载链接
链接失效反馈官方服务:
资源简介:
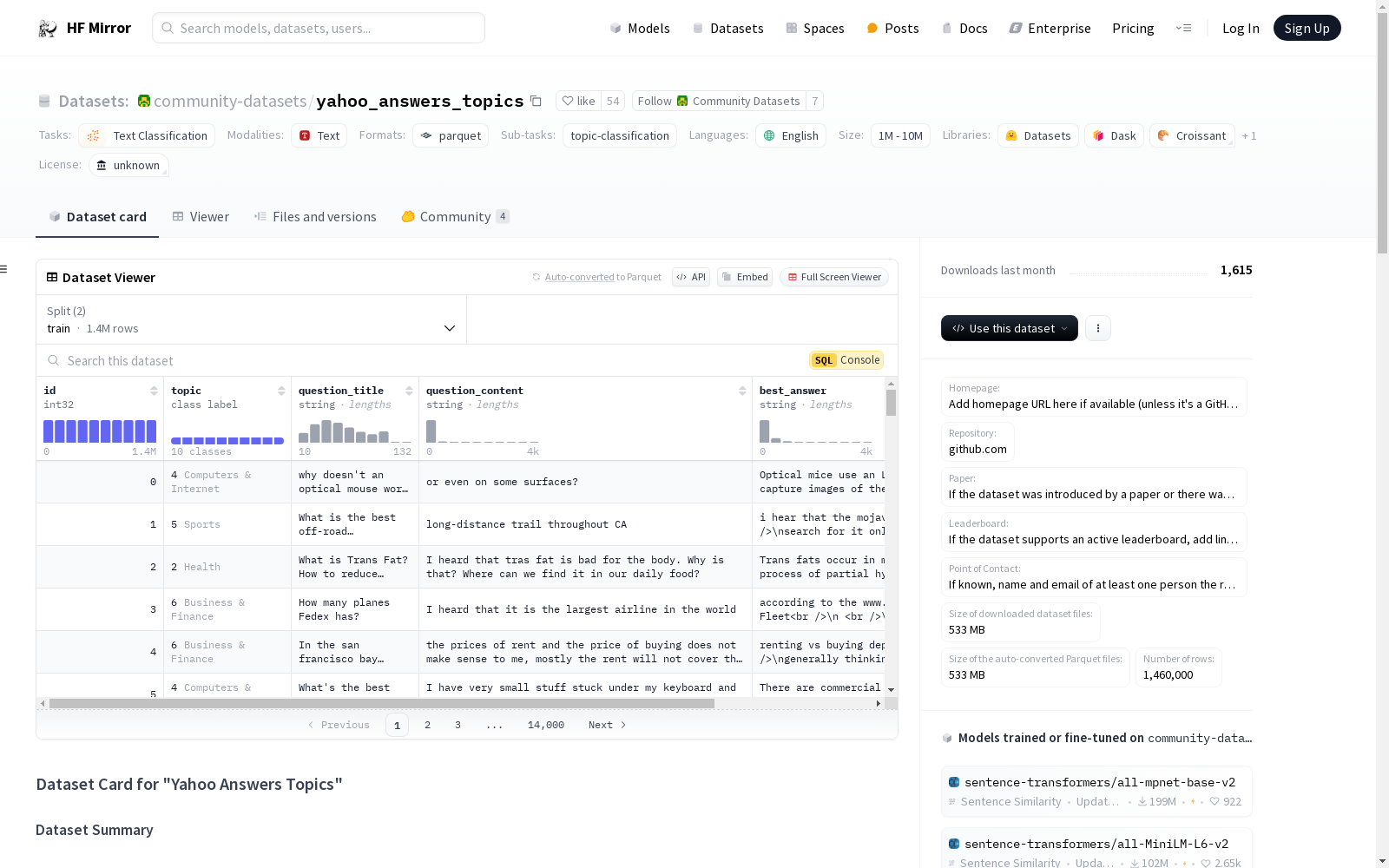
该数据集是一个用于文本分类任务的Yahoo Answers主题分类数据集。数据集包含140万条训练数据和6万条测试数据,每条数据包括问题标题、问题内容、最佳答案以及对应的主题标签。主题标签涵盖了10个类别,如社会与文化、科学与数学、健康等。数据集的语言为英语,且为单语数据集。
This is a Yahoo Answers topic classification dataset designed for text classification tasks. It contains 1.4 million training samples and 60,000 test samples. Each sample includes the question title, question content, best answer, and the corresponding topic label. The topic labels cover 10 categories such as Society & Culture, Science & Mathematics, Health and others. The dataset is in English and is a monolingual dataset.
提供机构:
community-datasets
原始信息汇总
数据集卡片 for "Yahoo Answers Topics"
数据集描述
数据集摘要
- annotations_creators: found
- language_creators: found
- language: en
- license: unknown
- multilinguality: monolingual
- size_categories: 1M<n<10M
- source_datasets: extended|other-yahoo-answers-corpus
- task_categories: text-classification
- task_ids: topic-classification
- pretty_name: YahooAnswersTopics
数据集结构
数据字段
- id: int32
- topic: class_label
- names:
- 0: Society & Culture
- 1: Science & Mathematics
- 2: Health
- 3: Education & Reference
- 4: Computers & Internet
- 5: Sports
- 6: Business & Finance
- 7: Entertainment & Music
- 8: Family & Relationships
- 9: Politics & Government
- names:
- question_title: string
- question_content: string
- best_answer: string
数据分割
- train:
- num_bytes: 760285695
- num_examples: 1400000
- test:
- num_bytes: 32653862
- num_examples: 60000
数据集创建
数据集信息
- config_name: yahoo_answers_topics
- download_size: 533429663
- dataset_size: 792939557
配置
- config_name: yahoo_answers_topics
- data_files:
- split: train path: yahoo_answers_topics/train-*
- split: test path: yahoo_answers_topics/test-*
- default: true
- data_files:
训练评估索引
- config: yahoo_answers_topics
- task: text-classification
- task_id: multi_class_classification
- splits:
- train_split: train
- eval_split: test
- col_mapping:
- question_content: text
- topic: target
- metrics:
- type: accuracy name: Accuracy
- type: f1 name: F1 macro args: average: macro
- type: f1 name: F1 micro args: average: micro
- type: f1 name: F1 weighted args: average: weighted
- type: precision name: Precision macro args: average: macro
- type: precision name: Precision micro args: average: micro
- type: precision name: Precision weighted args: average: weighted
- type: recall name: Recall macro args: average: macro
- type: recall name: Recall micro args: average: micro
- type: recall name: Recall weighted args: average: weighted
搜集汇总
数据集介绍
构建方式
Yahoo Answers Topics数据集的构建基于Yahoo Answers平台上的问答内容,涵盖了多个主题类别。该数据集通过从Yahoo Answers语料库中提取并扩展数据,形成了包含140万条训练样本和6万条测试样本的规模。每条数据实例包括问题ID、主题类别、问题标题、问题内容以及最佳答案,确保了数据的多维度特性。
特点
Yahoo Answers Topics数据集的主要特点在于其丰富的主题分类和多样的文本内容。数据集涵盖了10个不同的主题类别,如社会与文化、科学与数学、健康等,为文本分类任务提供了广泛的应用场景。此外,数据集的规模适中,适合用于大规模文本分类模型的训练与评估。
使用方法
Yahoo Answers Topics数据集适用于文本分类任务,特别是多类别分类问题。用户可以通过加载数据集并使用问题内容和主题类别作为输入特征和目标标签,进行模型训练和评估。数据集提供了详细的字段映射和评估指标,如准确率、F1分数等,便于用户进行模型性能的量化分析。
背景与挑战
背景概述
Yahoo Answers Topics数据集是由Yahoo Answers平台上的用户生成内容构建而成,主要用于文本分类任务中的主题分类。该数据集包含了超过140万条训练样本和6万条测试样本,涵盖了10个不同的主题类别,如社会与文化、科学与数学、健康等。数据集的核心研究问题在于如何有效地对用户提出的问题进行主题分类,这对于信息检索和自然语言处理领域具有重要意义。尽管数据集的创建时间和主要研究人员信息未明确提及,但其对文本分类领域的贡献不容忽视,尤其是在处理大规模用户生成内容时,该数据集为研究者提供了一个宝贵的资源。
当前挑战
Yahoo Answers Topics数据集在构建过程中面临了多个挑战。首先,数据集的来源是用户生成内容,这意味着数据的质量和一致性可能存在问题,如何处理噪声和冗余信息是一个重要挑战。其次,主题分类任务本身具有一定的复杂性,尤其是在处理多类别分类时,模型需要具备较高的泛化能力。此外,数据集的标注过程未详细说明,可能存在标注不一致或偏差的问题,这会影响模型的训练效果。最后,数据集的许可信息未知,使用时需谨慎考虑其法律和伦理影响。
常用场景
经典使用场景
Yahoo Answers Topics数据集的经典使用场景主要集中在文本分类任务中,特别是主题分类。该数据集包含了来自Yahoo Answers平台的大量问答对,每个问题都被标注了特定的主题类别,如社会与文化、科学与数学、健康等。研究者可以利用这些数据训练和评估文本分类模型,以自动识别和分类用户提出的问题,从而提升信息检索和问答系统的效率。
实际应用
在实际应用中,Yahoo Answers Topics数据集可以用于构建智能问答系统、信息检索引擎以及内容推荐系统。例如,在客户服务领域,企业可以利用该数据集训练模型,自动分类用户咨询的问题,从而快速分配给相应的专家处理。此外,该数据集还可用于教育领域,帮助学生快速找到与其学习内容相关的答案,提升学习效率。
衍生相关工作
基于Yahoo Answers Topics数据集,研究者们开发了多种文本分类模型和算法,推动了自然语言处理技术的进步。例如,一些研究工作利用该数据集进行深度学习模型的训练,探索了卷积神经网络(CNN)和循环神经网络(RNN)在文本分类中的应用。此外,该数据集还被用于多任务学习、迁移学习等新兴研究方向,进一步拓展了其在学术界和工业界的应用范围。
以上内容由遇见数据集搜集并总结生成


