有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
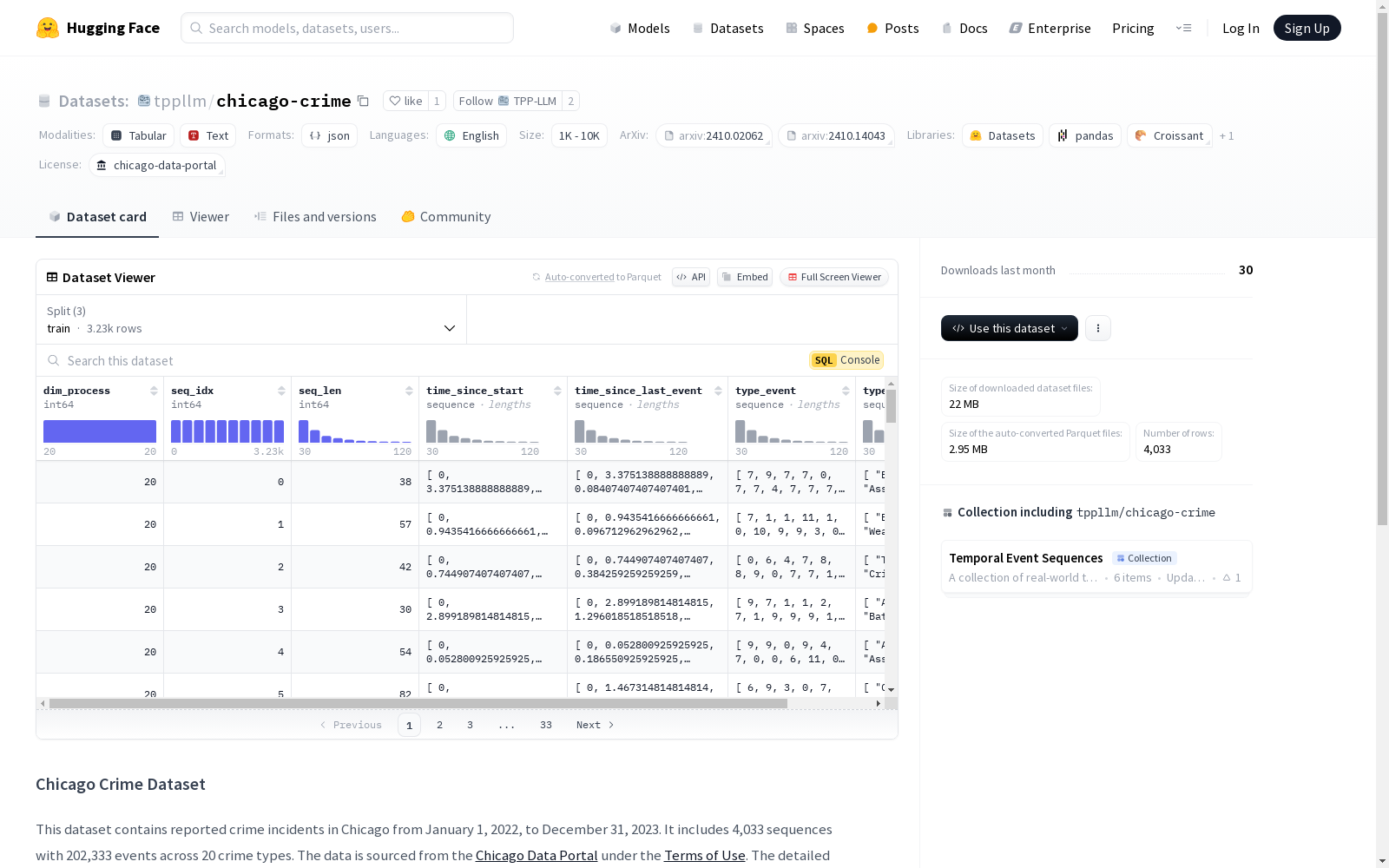
学生课堂行为数据集 (SCB-dataset3)
学生课堂行为数据集(SCB-dataset3)由成都东软学院创建,包含5686张图像和45578个标签,重点关注六种行为:举手、阅读、写作、使用手机、低头和趴桌。数据集覆盖从幼儿园到大学的不同场景,通过YOLOv5、YOLOv7和YOLOv8算法评估,平均精度达到80.3%。该数据集旨在为学生行为检测研究提供坚实基础,解决教育领域中学生行为数据集的缺乏问题。
arXiv 收录
Hang Seng Index
恒生指数(Hang Seng Index)是香港股市的主要股票市场指数,由恒生银行旗下的恒生指数有限公司编制。该指数涵盖了香港股票市场中最具代表性的50家上市公司,反映了香港股市的整体表现。
www.hsi.com.hk 收录
OpenSonarDatasets
OpenSonarDatasets是一个致力于整合开放源代码声纳数据集的仓库,旨在为水下研究和开发提供便利。该仓库鼓励研究人员扩展当前的数据集集合,以增加开放源代码声纳数据集的可见性,并提供一个更容易查找和比较数据集的方式。
github 收录
LUNA16
LUNA16(肺结节分析)数据集是用于肺分割的数据集。它由 1,186 个肺结节组成,在 888 次 CT 扫描中进行了注释。
OpenDataLab 收录
TCIA
TCIA(The Cancer Imaging Archive)是一个公开的癌症影像数据集,包含多种癌症类型的医学影像数据,如CT、MRI、PET等。这些数据通常与临床和病理信息相结合,用于癌症研究和临床试验。
www.cancerimagingarchive.net 收录