MMPR
收藏魔搭社区2026-01-06 更新2024-11-23 收录
下载链接:
https://modelscope.cn/datasets/AI-ModelScope/MMPR
下载链接
链接失效反馈官方服务:
资源简介:
# MMPR
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL/tree/main/internvl_chat/shell/internvl2.0_mpo) [\[🆕 Blog\]](https://internvl.github.io/blog/2024-11-14-InternVL-2.0-MPO/) [\[📜 Paper\]](https://arxiv.org/abs/2411.10442) [\[📖 Documents\]](https://internvl.readthedocs.io/en/latest/internvl2.0/preference_optimization.html)
***`2025/04/11:` We release a new version of MMPR (i.e., [MMPR-v1.2](https://huggingface.co/datasets/OpenGVLab/MMPR-v1.2)), which greatly enhances the overall performance of InternVL3.***
***`2024/12/20:` We release a new version of MMPR (i.e., [MMPR-v1.1](https://huggingface.co/datasets/OpenGVLab/MMPR-v1.1)). Based on this dataset, InternVL2.5 outperforms its counterparts without MPO by an average of 2 points across all scales on the OpenCompass leaderboard.***
## Introduction
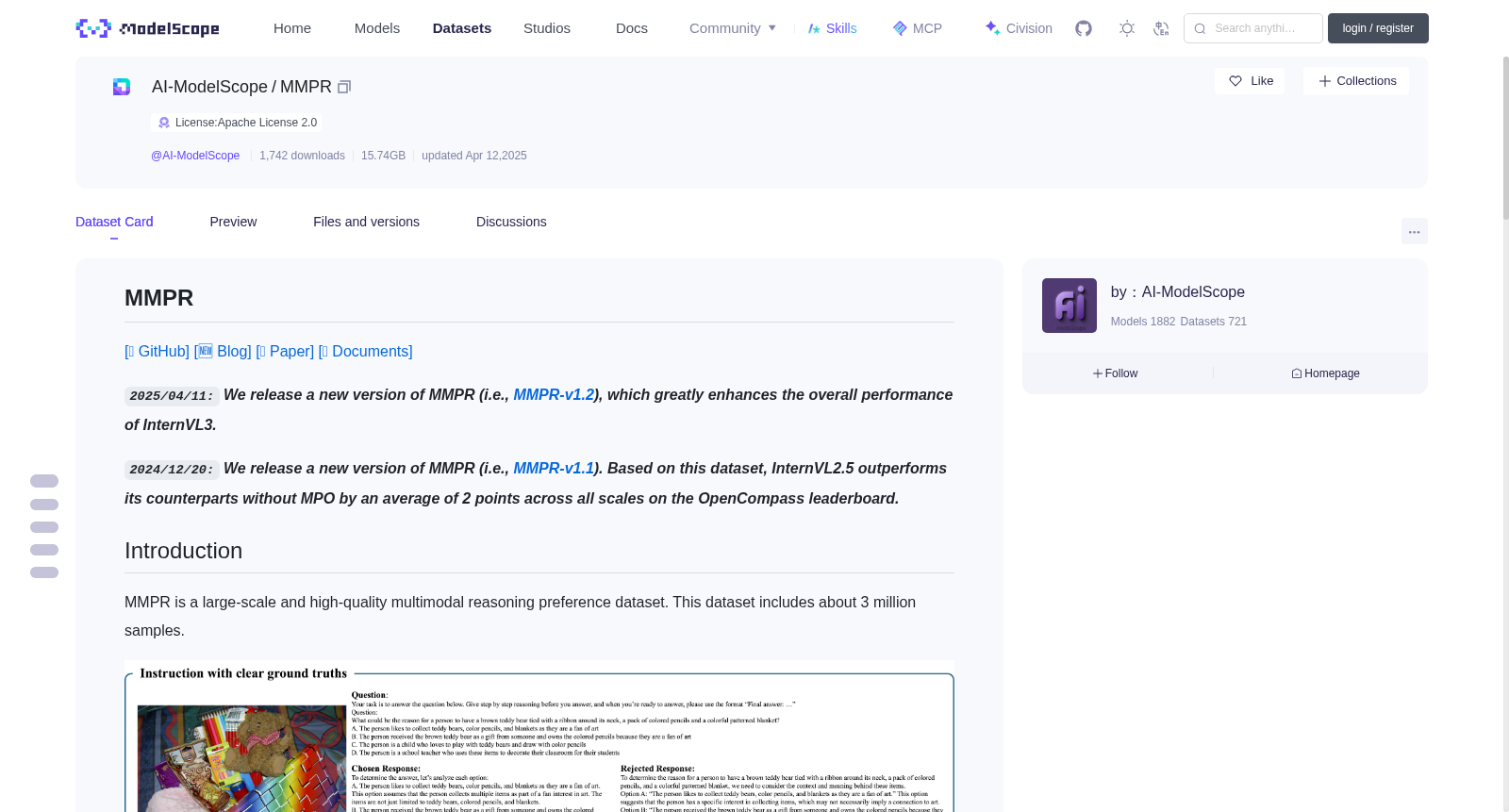
MMPR is a large-scale and high-quality multimodal reasoning preference dataset. This dataset includes about 3 million samples.


We finetune InternVL2-8B with [MPO](https://internvl.github.io/blog/2024-11-14-InternVL-2.0-MPO/#Mix-Preference-Optimization) using this dataset.
The resulting model, [InternVL2-8B-MPO](https://huggingface.co/OpenGVLab/InternVL2-8B-MPO), achieves superior performance across 8 benchmarks, particularly excelling in multimodal reasoning tasks.
**On the MathVista benchmark, our model achieves an accuracy of 67.0%**, outperforming InternVL2-8B by 8.7 points and achieving performance comparable to the \\(10\times\\) larger InternVL2-76B.
**On the MathVision benchmark, our model achieves an accuracy of 25.7%**, establishing a new state-of-the-art performance among open-source models.
These results demonstrate the effectiveness of our preference optimization approach in enhancing multimodal reasoning capabilities.
Additionally, on the POPE benchmark, our model exhibits a 1.2-point improvement over InterVL2-8B, demonstrating the effectiveness of the perception data contained in our MMPR dataset to mitigate hallucinations.
Furthermore, our model also shows superior performance compared to the InternVL2-8B on complex VQA benchmarks, indicating that the general abilities of our model are also improved, benefiting from enhanced reasoning abilities and mitigated hallucinations.
Please refer to our [paper](https://internvl.github.io/blog/2024-11-14-InternVL-2.0-MPO/) for more details.
| Model Name | M3CoT | MathVista | MathVision MINI | MMVet (GPT4-Turbo) | LLaVA-Bench | POPE | CRPE | MMHalBench |
| ----------------------- | :---: | :-------: | :-------------: | :----------------: | :---------: | :---: | :---: | :--------: |
| Gemini-1.5-Pro | - | 63.9 | 19.2 | - | - | - | - | - |
| GPT-4o | 64.3 | 63.8 | 30.4 | 69.1 | 97.6 | 86.9 | 76.6 | 4.0 |
| GPT-4o-Mini | 61.9 | 52.4 | 27.3 | 66.9 | 95.4 | 85.1 | 73.1 | 3.6 |
| LLaVA-1.5-13B | 39.5 | 27.6 | 11.1 | 36.3 | 70.7 | 85.9 | 55.6 | 2.4 |
| Qwen2-VL-7B | 57.8 | 58.2 | 21.1 | 60.6 | 67.7 | 88.1 | 74.4 | 3.4 |
| MiniCPM-V-2-6-8B | 56.0 | 60.6 | 23.4 | 57.4 | 83.4 | 87.3 | 75.2 | 3.6 |
| LLaVA-OneVision-7B | 52.3 | 63.2 | 18.4 | 51.4 | 79.9 | 88.4 | 73.7 | 3.1 |
| InternVL2-26B | 58.2 | 59.4 | 23.4 | 62.1 | 92.3 | 88.0 | 75.6 | 3.7 |
| InternVL2-40B | 63.6 | 63.7 | 21.4 | 65.5 | 100.5 | 88.4 | 77.3 | 3.9 |
| InternVL2-76B | 65.4 | 67.5 | 23.7 | 65.7 | 99.3 | 89.0 | 77.8 | 3.8 |
| InternVL2-Pro | 65.6 | 66.3 | 18.8 | 69.4 | 99.5 | 88.2 | 77.6 | 3.7 |
| InternVL2-8B | 59.3 | 58.3 | 20.4 | 54.2 | 73.2 | 86.9 | 75.0 | 3.3 |
| InternVL2-8B-MPO (ours) | 79.2 | 67.0 | 25.7 | 56.2 | 76.7 | 88.1 | 75.4 | 3.5 |
## Usage
Please refer to [our document](https://internvl.readthedocs.io/en/latest/internvl2.0/preference_optimization.html).
## Data fields
| Key | Description |
| ---------- | ----------------------------------- |
| `image` | Image path. |
| `question` | Input query. |
| `chosen` | Chosen response for the question. |
| `rejected` | Rejected response for the question. |
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{wang2024mpo,
title={Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization},
author={Wang, Weiyun and Chen, Zhe and Wang, Wenhai and Cao, Yue and Liu, Yangzhou and Gao, Zhangwei and Zhu, Jinguo and Zhu, Xizhou and Lu, Lewei and Qiao, Yu and Dai, Jifeng},
journal={arXiv preprint arXiv:2411.10442},
year={2024}
}
@article{chen2023internvl,
title={InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and Li, Bin and Luo, Ping and Lu, Tong and Qiao, Yu and Dai, Jifeng},
journal={arXiv preprint arXiv:2312.14238},
year={2023}
}
@article{chen2024far,
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={arXiv preprint arXiv:2404.16821},
year={2024}
}
```
# MMPR
[📂 GitHub](https://github.com/OpenGVLab/InternVL/tree/main/internvl_chat/shell/internvl2.0_mpo) [🆕 博客](https://internvl.github.io/blog/2024-11-14-InternVL-2.0-MPO/) [📜 论文](https://arxiv.org/abs/2411.10442) [📖 文档](https://internvl.readthedocs.io/en/latest/internvl2.0/preference_optimization.html)
***`2025/04/11:` 我们发布了MMPR的新版本(即[MMPR-v1.2](https://huggingface.co/datasets/OpenGVLab/MMPR-v1.2)),该版本大幅提升了InternVL3的整体性能。***
***`2024/12/20:` 我们发布了MMPR的更新版本(即[MMPR-v1.1](https://huggingface.co/datasets/OpenGVLab/MMPR-v1.1))。基于该数据集,InternVL2.5在OpenCompass排行榜的全尺度下,平均性能较未使用MPO的同类模型高出2个百分点。***
## 简介
MMPR是大规模高质量多模态推理偏好数据集,共包含约300万条样本。


我们使用该数据集结合[MPO(混合偏好优化,Mix Preference Optimization)](https://internvl.github.io/blog/2024-11-14-InternVL-2.0-MPO/#Mix-Preference-Optimization)对InternVL2-8B进行微调。
基于此得到的模型[InternVL2-8B-MPO](https://huggingface.co/OpenGVLab/InternVL2-8B-MPO)在8项基准测试中表现优异,尤其在多模态推理任务上性能突出。
**在MathVista基准测试中,我们的模型准确率达到67.0%**,较InternVL2-8B提升8.7个百分点,性能可与参数规模大10倍的InternVL2-76B相媲美。
**在MathVision基准测试中,我们的模型准确率达到25.7%**,创下开源模型的最新最优性能。
上述结果证明了我们的偏好优化方法在增强多模态推理能力上的有效性。
此外,在POPE基准测试中,我们的模型较InternVL2-8B提升1.2个百分点,表明MMPR数据集包含的感知数据可有效缓解模型幻觉问题。
同时,在复杂视觉问答(VQA)基准测试中,我们的模型相较InternVL2-8B同样表现更优,这说明得益于推理能力提升与幻觉问题缓解,模型的通用能力也得到了增强。
更多细节可参考我们的[论文](https://internvl.github.io/blog/2024-11-14-InternVL-2.0-MPO/)。
| 模型名称 | M3CoT | MathVista | MathVision MINI | MMVet (GPT4-Turbo) | LLaVA-Bench | POPE | CRPE | MMHalBench |
| ----------------------- | :---: | :-------: | :-------------: | :----------------: | :---------: | :---: | :---: | :--------: |
| Gemini-1.5-Pro | - | 63.9 | 19.2 | - | - | - | - | - |
| GPT-4o | 64.3 | 63.8 | 30.4 | 69.1 | 97.6 | 86.9 | 76.6 | 4.0 |
| GPT-4o-Mini | 61.9 | 52.4 | 27.3 | 66.9 | 95.4 | 85.1 | 73.1 | 3.6 |
| LLaVA-1.5-13B | 39.5 | 27.6 | 11.1 | 36.3 | 70.7 | 85.9 | 55.6 | 2.4 |
| Qwen2-VL-7B | 57.8 | 58.2 | 21.1 | 60.6 | 67.7 | 88.1 | 74.4 | 3.4 |
| MiniCPM-V-2-6-8B | 56.0 | 60.6 | 23.4 | 57.4 | 83.4 | 87.3 | 75.2 | 3.6 |
| LLaVA-OneVision-7B | 52.3 | 63.2 | 18.4 | 51.4 | 79.9 | 88.4 | 73.7 | 3.1 |
| InternVL2-26B | 58.2 | 59.4 | 23.4 | 62.1 | 92.3 | 88.0 | 75.6 | 3.7 |
| InternVL2-40B | 63.6 | 63.7 | 21.4 | 65.5 | 100.5 | 88.4 | 77.3 | 3.9 |
| InternVL2-76B | 65.4 | 67.5 | 23.7 | 65.7 | 99.3 | 89.0 | 77.8 | 3.8 |
| InternVL2-Pro | 65.6 | 66.3 | 18.8 | 69.4 | 99.5 | 88.2 | 77.6 | 3.7 |
| InternVL2-8B | 59.3 | 58.3 | 20.4 | 54.2 | 73.2 | 86.9 | 75.0 | 3.3 |
| InternVL2-8B-MPO (ours) | 79.2 | 67.0 | 25.7 | 56.2 | 76.7 | 88.1 | 75.4 | 3.5 |
## 使用方法
请参考[我们的文档](https://internvl.readthedocs.io/en/latest/internvl2.0/preference_optimization.html)。
## 数据字段
| 键名 | 描述 |
| ---------- | ---------------------------------- |
| `image` | 图像路径。 |
| `question` | 输入查询。 |
| `chosen` | 该问题的优选回复。 |
| `rejected` | 该问题的非优选回复。 |
## 引用
如果您的研究中用到本项目,请考虑引用以下文献:
BibTeX
@article{wang2024mpo,
title={Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization},
author={Wang, Weiyun and Chen, Zhe and Wang, Wenhai and Cao, Yue and Liu, Yangzhou and Gao, Zhangwei and Zhu, Jinguo and Zhu, Xizhou and Lu, Lewei and Qiao, Yu and Dai, Jifeng},
journal={arXiv preprint arXiv:2411.10442},
year={2024}
}
@article{chen2023internvl,
title={InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and Li, Bin and Luo, Ping and Lu, Tong and Qiao, Yu and Dai, Jifeng},
journal={arXiv preprint arXiv:2312.14238},
year={2023}
}
@article{chen2024far,
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={arXiv preprint arXiv:2404.16821},
year={2024}
}
提供机构:
maas
创建时间:
2024-11-21
搜集汇总
数据集介绍
背景与挑战
背景概述
MMPR是一个包含约300万样本的大规模多模态推理偏好数据集,用于提升模型在多模态任务中的性能,特别是在MathVista和MathVision等基准测试中表现突出。
以上内容由遇见数据集搜集并总结生成


