AutoFish
收藏arXiv2025-01-07 更新2025-01-09 收录
下载链接:
https://vap.aau.dk/autofish/
下载链接
链接失效反馈官方服务:
资源简介:
AutoFish是一个用于鱼类细粒度分析的公开数据集,由奥尔堡大学等机构创建。该数据集包含1500张高质量图像,涵盖了454个独特的鱼类样本,每个样本都有实例分割掩码、ID和手动长度测量。数据集的创建过程包括在实验室环境中使用RGB相机采集图像,并通过手动点注释和Segment Anything Model (SAM)生成初始分割掩码,随后进行手动校正。数据集的应用领域包括可持续渔业管理和过度捕捞问题的解决,旨在通过自动化技术提供实时监测和数据分析,以支持渔业管理的透明性和生态保护。
AutoFish is a public dataset for fine-grained fish analysis, developed by institutions including Aalborg University. This dataset contains 1,500 high-quality images covering 454 unique fish specimens, each with instance segmentation masks, IDs, and manual length measurements. The dataset was constructed by collecting images using RGB cameras in a laboratory environment, generating initial segmentation masks via manual point annotations and the Segment Anything Model (SAM), followed by manual correction. Its application fields include sustainable fisheries management and addressing overfishing, aiming to provide real-time monitoring and data analysis through automated technologies to support the transparency of fisheries management and ecological conservation.
提供机构:
奥尔堡大学视觉分析与感知实验室,丹麦;哥本哈根人工智能先锋中心,丹麦;奥尔堡大学生物与环境科学系,丹麦
创建时间:
2025-01-07
搜集汇总
数据集介绍
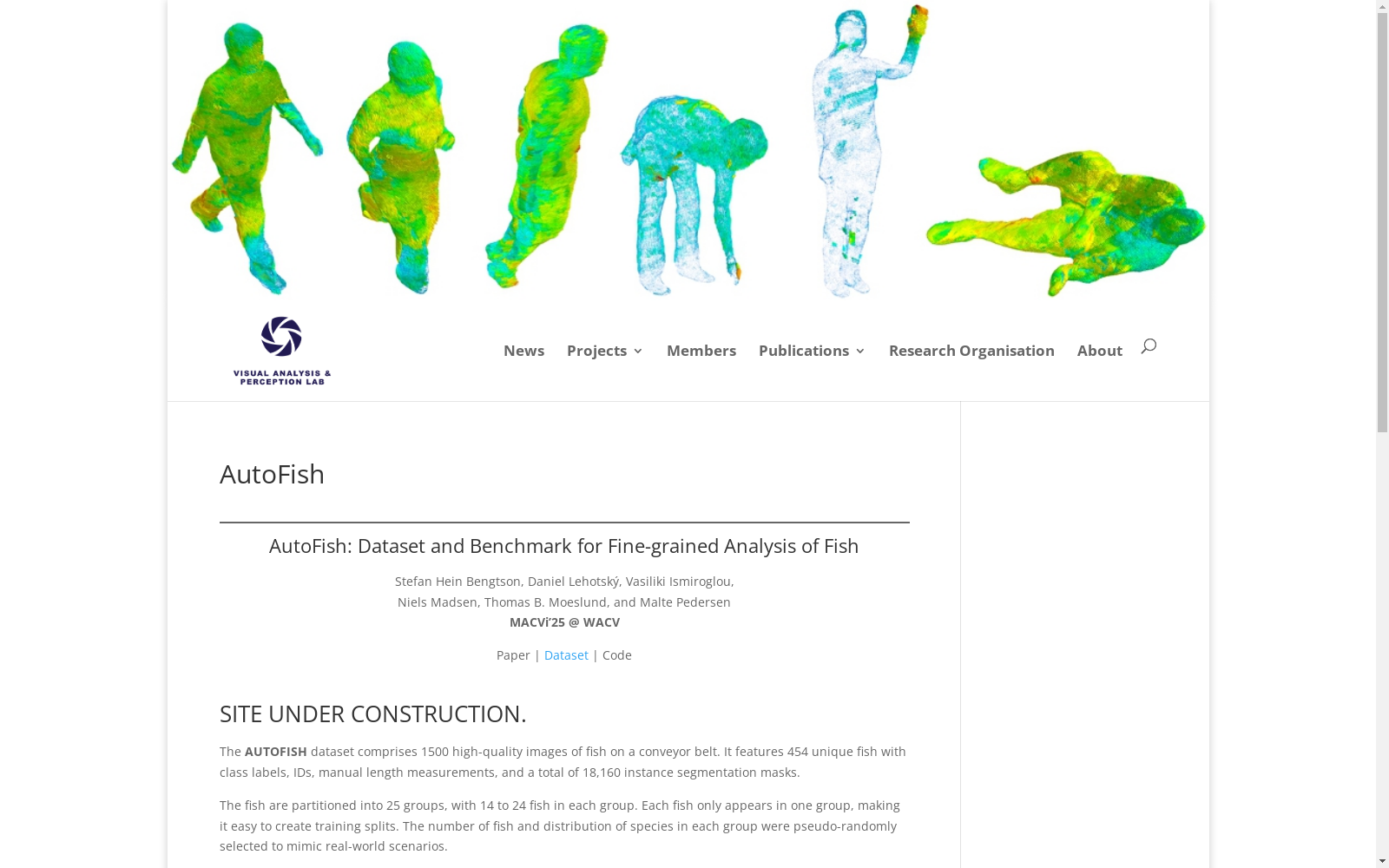
构建方式
AutoFish数据集的构建过程始于在丹麦北海水域的商业渔船上捕获的鱼类样本。这些样本主要包括鳕鱼、黑线鳕和鳕鱼科的其他成员,这些鱼类在视觉上具有相似的特征。数据集中的图像是在实验室环境中使用定制的白色传送带和RGB相机拍摄的,确保了图像的高质量和一致性。每张图像中的鱼类都被精确地标注了实例分割掩码、ID和手动测量的长度。标注过程结合了手动点标注和Segment Anything Model (SAM)的初始分割掩码,随后进行了手动校正,以确保标注的准确性。
特点
AutoFish数据集包含了1,500张高质量图像,涵盖了454个独特的鱼类样本,总计18,160个实例分割掩码。该数据集的一个显著特点是其包含了同一鱼类在不同方向和遮挡情况下的多次出现,这为细粒度分析提供了丰富的数据支持。此外,数据集还提供了每张图像中鱼类的ID和手动测量的长度信息,使其成为目前唯一公开的包含此类信息的鱼类数据集。这些特点使得AutoFish在鱼类识别、长度估计等任务中具有重要的应用价值。
使用方法
AutoFish数据集的使用方法主要集中在实例分割和长度估计任务上。研究人员可以使用该数据集来训练和评估深度学习模型,如Mask2Former架构,以实现鱼类的精确分割。此外,数据集中的长度信息可以用于开发基于卷积神经网络(CNN)的回归模型,以估计鱼类的长度。通过结合实例分割和长度估计,AutoFish数据集为自动化渔业管理提供了强有力的工具,能够帮助监测渔获物的组成,促进可持续渔业的发展。
背景与挑战
背景概述
AutoFish数据集由丹麦奥尔堡大学的视觉分析与感知实验室(Visual Analysis and Perception Lab)与Pioneer Centre for AI合作开发,旨在通过计算机视觉技术解决渔业管理中的自动化鱼类识别与长度估计问题。该数据集于2025年发布,包含1,500张高分辨率图像,涵盖了454条不同鱼类样本的实例分割掩码、ID和手动长度测量数据。AutoFish的创建背景源于全球海洋生态系统面临的过度捕捞问题,传统渔业管理方法已无法有效应对这一挑战。通过提供精细的鱼类分析数据,AutoFish为开发实时自动化监测系统提供了重要支持,推动了可持续渔业管理的发展。
当前挑战
AutoFish数据集在解决鱼类实例分割和长度估计问题时面临多重挑战。首先,鱼类作为非刚性物体,其形态多变且易受遮挡影响,导致实例分割的精度难以保证。其次,长度估计任务在鱼类重叠或遮挡情况下尤为复杂,传统图像处理方法难以准确捕捉鱼类的真实长度。此外,数据集的构建过程中也面临挑战,包括在受控环境中模拟真实渔业场景、确保数据标注的准确性以及处理大量高分辨率图像的存储与处理需求。尽管AutoFish通过引入Segment Anything Model(SAM)和手动校正提高了标注质量,但在实际应用中,如何进一步提升模型在复杂场景下的鲁棒性仍是一个亟待解决的问题。
常用场景
经典使用场景
AutoFish数据集在渔业管理和海洋生态保护领域具有广泛的应用潜力。其经典使用场景包括通过计算机视觉技术对鱼类进行细粒度分析,如物种识别、实例分割和长度估计。该数据集特别适用于自动化渔业监控系统,能够在鱼类捕捞过程中实时记录和分类捕获的鱼类,从而为可持续渔业管理提供数据支持。
衍生相关工作
AutoFish数据集的发布推动了多个相关领域的研究进展。基于该数据集,研究者开发了多种深度学习模型,如Mask2Former和MobileNetV2,用于鱼类实例分割和长度估计。此外,该数据集还启发了鱼类重识别技术的研究,通过利用鱼类ID信息,进一步提升了长度估计的精度。这些衍生工作不仅扩展了AutoFish的应用范围,也为渔业管理和生态保护提供了更多技术解决方案。
数据集最近研究
最新研究方向
近年来,AutoFish数据集在渔业管理和海洋生态保护领域的研究方向主要集中在自动化鱼类识别与长度估计技术的优化上。随着深度学习技术的快速发展,基于计算机视觉的鱼类监测系统逐渐成为研究热点。AutoFish数据集通过提供高质量的实例分割掩码和长度测量数据,为鱼类识别和长度估计任务提供了坚实的基础。当前的研究重点包括利用Mask2Former等先进的实例分割模型提升鱼类识别的精度,以及通过卷积神经网络(CNN)和经典图像处理技术(如骨架化)相结合的方法,优化鱼类长度估计的准确性。特别是在鱼类重叠和遮挡场景下,CNN模型展现出更强的鲁棒性,能够有效处理复杂的图像数据。此外,AutoFish数据集中的鱼类ID信息为个体级别的精细分析提供了可能,未来研究可进一步探索鱼类重识别技术,以实现更高效的渔业管理和生态监测。
相关研究论文
- 1AutoFish: Dataset and Benchmark for Fine-grained Analysis of Fish奥尔堡大学视觉分析与感知实验室,丹麦;哥本哈根人工智能先锋中心,丹麦;奥尔堡大学生物与环境科学系,丹麦 · 2025年
以上内容由遇见数据集搜集并总结生成


