ljnlonoljpiljm/megalith-qa-resized
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/ljnlonoljpiljm/megalith-qa-resized
下载链接
链接失效反馈官方服务:
资源简介:
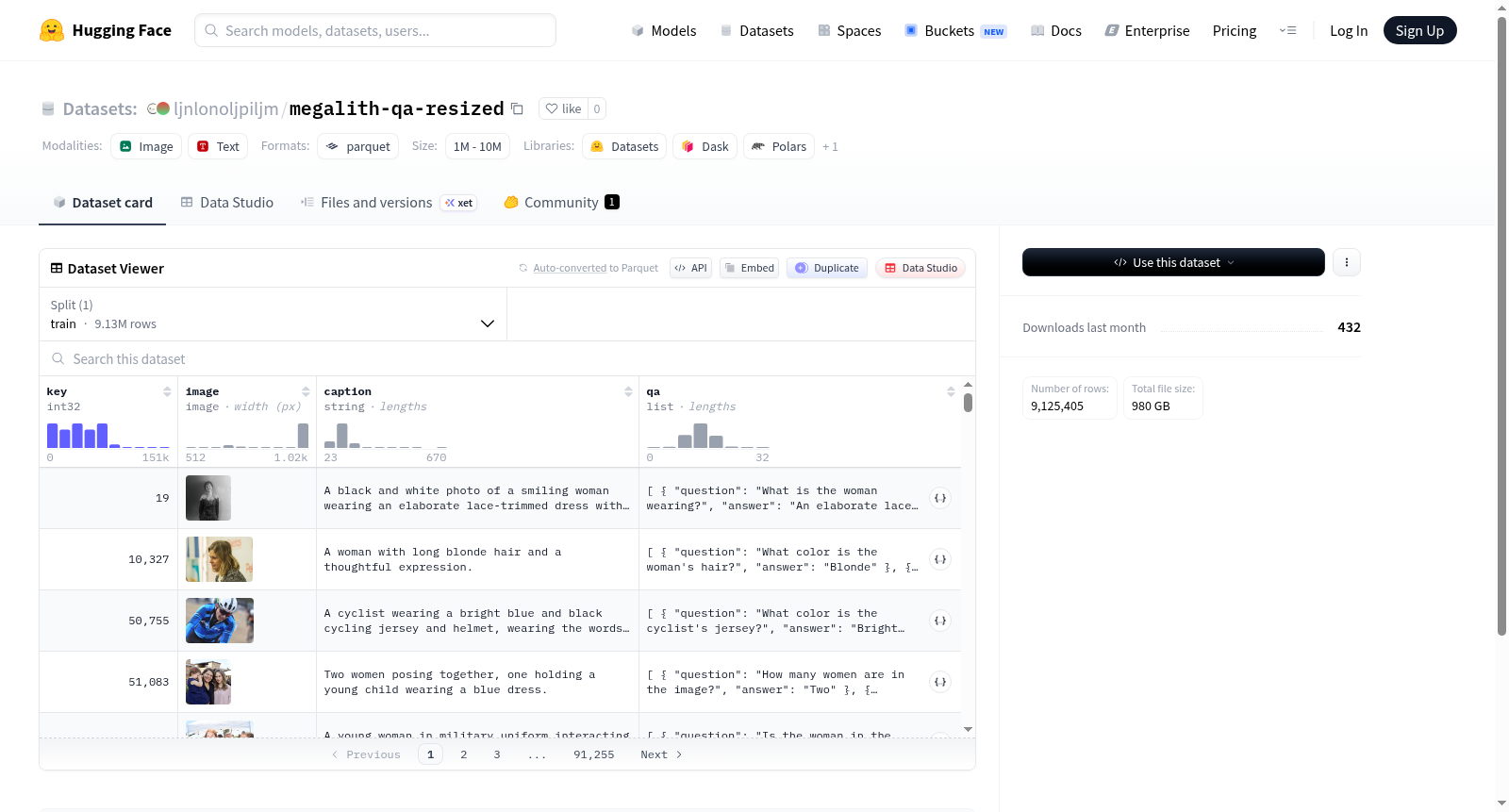
该数据集是一个包含图像和文本的多模态数据集,主要特征包括:key(整型标识符)、image(图像数据)、caption(图像描述文本)和qa(问答对列表,每个问答对包含问题和答案)。数据集仅提供训练集,包含约912万样本,总大小约为982GB。
This dataset is a multimodal dataset containing images and text. The main features include: key (integer identifier), image (image data), caption (image description text), and qa (a list of QA pairs, each containing a question and an answer). The dataset only provides a training set with approximately 9.12 million samples and a total size of about 982GB.
提供机构:
ljnlonoljpiljm
搜集汇总
数据集介绍
构建方式
该数据集基于大规模图像与文本对构建,其核心结构包含图像、文本描述及问答对三个维度。每一条样本均以图像为中心,辅以对应文本描述,并在此基础上扩展出多组问答对,从而形成多层次的信息结构。数据集的构建旨在覆盖海量视觉场景,其训练集包含超过九百万条样本,规模庞大,确保了数据在视觉与语言任务中的广泛适用性。数据以Parquet格式存储,便于高效加载与处理。
使用方法
使用时,可通过加载图像、文本描述及问答对字段直接构建多模态训练或评估流程。图像字段可直接用于视觉特征提取,而文本描述和问答对则提供语义监督信号。推荐使用HuggingFace Datasets库加载数据,利用其高效的分批读取功能处理大规模数据。数据集的问答对部分可独立用于微调视觉语言模型或作为检索任务的基准。开发者应关注图像与问答对的对齐关系,以充分发挥其结构化特点。
背景与挑战
背景概述
在视觉语言理解与推理领域,大规模多模态数据集的构建是推动模型性能跃升的关键基石。Megalith-QA-Resized数据集由研究团队于近年创建,旨在应对视觉问答(VQA)任务中训练数据规模不足与场景多样性的挑战。该数据集包含约912.5万样本,每一样本由图像、描述文本及问答对构成,覆盖广泛的生活场景与知识领域。其诞生源于对现有数据集(如COCO-QA、VQA v2)在规模与复杂度上的突破,为多模态大模型(如LLaVA、BLIP-2)的预训练与微调提供了海量标注资源。该数据集的出现显著推动了视觉语言联合表示学习的研究进展,成为评估模型细粒度理解能力的重要基准。
当前挑战
该数据集所解决的领域挑战主要集中在两点:其一,视觉问答任务中模型依赖浅层语言先验而忽视图像内容的固有问题,通过大规模、高多样性的图文对及显式推理问答设计,迫使模型学习跨模态对齐与逻辑推演。其二,构建过程中面临图像与问答质量平衡的挑战:将原始图像缩放到统一尺寸可能丢失细节,需权衡分辨率与模型计算效率;同时,从网络自动收集的问答对存在噪声,需设计过滤机制确保语义规范的准确性,这对清洗算法公平性构成考验。此外,数据集的体量(约1TB)对存储与分布式训练框架的稳定性提出工程化要求。
常用场景
经典使用场景
megalith-qa-resized数据集是一个大规模视觉问答(VQA)数据集,包含超过900万个图像-问题-答案三元组,每个样本由图像、对应的自然语言问题和答案组成。该数据集最经典的使用场景是训练和评估多模态理解模型,尤其在视觉与语言联合推理任务中发挥核心作用。研究者通常利用它来开发能够同时解析图像语义与文本信息的深度学习架构,例如基于Transformer的多模态融合模型,以提升模型在复杂视觉问答、图像描述生成等任务中的表现。该数据集的庞大规模和多样性使其成为推动视觉语言预训练模型发展的基石资源。
解决学术问题
该数据集有效解决了视觉问答领域中数据规模不足和多样性匮乏的学术瓶颈。传统VQA数据集如VQA v2通常包含数十万样本,难以支撑深度模型对多样化视觉概念和语言模式的彻底学习。megalith-qa-resized通过提供近千万级别的标注数据,显著提升了模型对细粒度视觉细节的捕捉能力、对复杂问题的逻辑推理能力及对领域外数据的泛化性能。其意义在于为构建鲁棒、通用的视觉语言理解系统提供了基准测试平台,推动了多模态领域从特定任务模型向统一基础模型的范式转变。
实际应用
在实际应用中,该数据集训练出的模型可广泛应用于智能辅助系统,如为视障人士提供实时环境问答服务、应用于在线教育中的自动习题解答、支持医疗影像分析中的诊断提问响应,以及电商平台中以图搜图和商品属性问答。此外,在智能客服、交互式搜索和车载视觉导航系统中,基于该数据集开发的模型能有效理解用户对图像内容的自然语言查询,从而提升人机交互的效率和准确性。
数据集最近研究
最新研究方向
大规模多模态问答数据集的兴起成为视觉语言模型能力跃升的关键基石。megalith-qa-resized作为包含超过900万图文对与问答样本的巨量资源,正推动研究从简单的图像描述向复杂的视觉推理演进。当前前沿方向聚焦于利用此类海量数据训练能理解细微视觉差异、执行多步推理并生成精准回答的通用视觉助手。该数据集的规模化特性使其成为评估和提升模型在开放世界场景中上下文理解能力的核心基准,其影响力已延伸至具身智能与自动报告生成等下游任务,标志着视觉语言领域正式迈入数据驱动的新范式。
以上内容由遇见数据集搜集并总结生成


