cardiffnlp/tweet_eval
收藏Hugging Face2024-01-04 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/cardiffnlp/tweet_eval
下载链接
链接失效反馈官方服务:
资源简介:
TweetEval数据集是一个包含多种任务的Twitter文本分类数据集,涵盖了七个不同的任务,包括表情符号分类、情感分类、仇恨言论检测、讽刺检测、冒犯性语言检测、情感分析和立场分析。每个任务都有固定的训练、验证和测试集划分。数据集中的文本均为英文,且数据集的规模从小于1K到接近1M不等。
The TweetEval dataset is a multi-task Twitter text classification dataset encompassing seven distinct tasks, including emoji classification, sentiment classification, hate speech detection, sarcasm detection, offensive language detection, sentiment analysis, and stance analysis. Each task has fixed splits for training, validation, and test sets. All texts in the dataset are in English, and the sizes of the task-specific datasets range from less than 1K to nearly 1M.
提供机构:
cardiffnlp
原始信息汇总
数据集概述
基本信息
- 数据集名称: TweetEval
- 语言: 英语
- 许可证: 未知
- 多语言性: 单语种
- 数据集大小分类: 包括多个大小类别,从小于1K到大于100K不等
- 源数据集: 扩展自其他推特数据集
- 任务类别: 文本分类
- 任务ID: 意图分类、多类分类、情感分类
配置名称
- emoji
- emotion
- hate
- irony
- offensive
- sentiment
- stance_abortion
- stance_atheism
- stance_climate
- stance_feminist
- stance_hillary
数据集详情
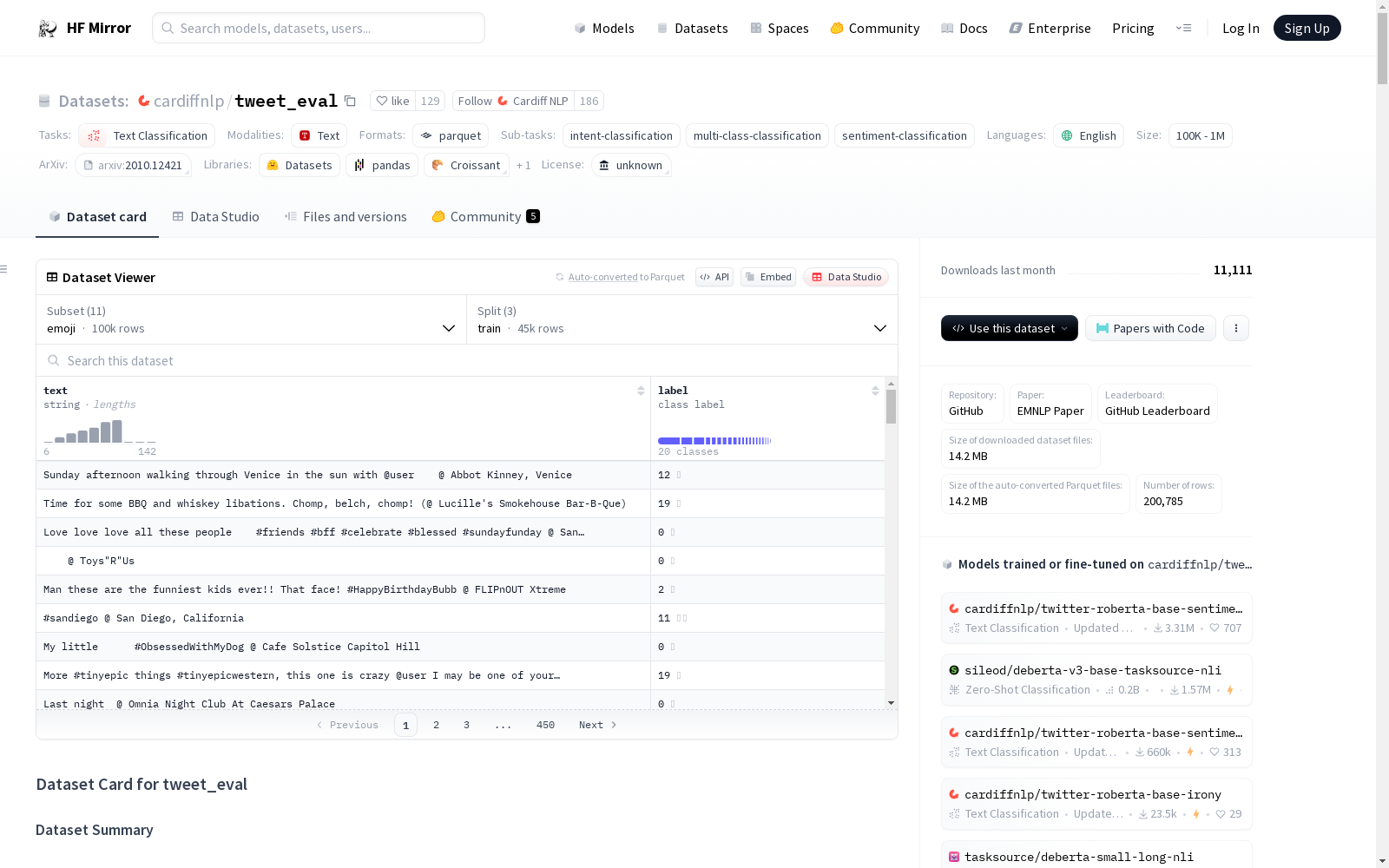
emoji
- 特征:
text: 字符串类型label: 分类标签,包括20种表情符号
- 数据分割:
- 训练集: 45000条
- 验证集: 5000条
- 测试集: 50000条
emotion
- 特征:
text: 字符串类型label: 分类标签,包括4种情绪(愤怒、喜悦、乐观、悲伤)
- 数据分割:
- 训练集: 3257条
- 验证集: 374条
- 测试集: 1421条
hate
- 特征:
text: 字符串类型label: 分类标签,包括2种(非仇恨、仇恨)
- 数据分割:
- 训练集: 9000条
- 验证集: 1000条
- 测试集: 2970条
irony
- 特征:
text: 字符串类型label: 分类标签,包括2种(非讽刺、讽刺)
- 数据分割:
- 训练集: 2862条
- 验证集: 955条
- 测试集: 784条
offensive
- 特征:
text: 字符串类型label: 分类标签,包括2种(非冒犯、冒犯)
- 数据分割:
- 训练集: 11916条
- 验证集: 1324条
- 测试集: 860条
sentiment
- 特征:
text: 字符串类型label: 分类标签,包括3种(负面、中性、正面)
- 数据分割:
- 训练集: 45615条
- 验证集: 2000条
- 测试集: 12284条
stance_abortion
- 特征:
text: 字符串类型label: 分类标签,包括3种(无立场、反对、支持)
- 数据分割:
- 训练集: 587条
- 验证集: 66条
- 测试集: 280条
stance_atheism
- 特征:
text: 字符串类型label: 分类标签,包括3种(无立场、反对、支持)
- 数据分割:
- 训练集: 461条
- 验证集: 52条
- 测试集: 220条
stance_climate
- 特征:
text: 字符串类型label: 分类标签,包括3种(无立场、反对、支持)
- 数据分割:
- 训练集: 355条
- 验证集: 40条
- 测试集: 169条
stance_feminist
- 特征:
text: 字符串类型label: 分类标签,包括3种(无立场、反对、支持)
- 数据分割:
- 训练集: 597条
- 验证集: 67条
- 测试集: 285条
stance_hillary
- 特征:
text: 字符串类型label: 分类标签,包括3种(无立场、反对、支持)
- 数据分割:
- 训练集: 620条
- 验证集: 69条
- 测试集: 295条
搜集汇总
数据集介绍
构建方式
TweetEval数据集是由Cardiff NLP团队构建的,它包含了七个不同的Twitter文本分类任务,包括讽刺、仇恨、冒犯、立场、表情符号、情感和情感。每个任务都统一到一个基准中,以相同格式呈现,并具有固定的训练、验证和测试分割。
特点
TweetEval数据集的特点是其多样性和综合性。它涵盖了广泛的情感表达和社交互动,从简单的表情符号到复杂的情感和立场。数据集以英文为主,适用于英语语言处理和文本分析研究。
使用方法
TweetEval数据集可以用于训练和评估文本分类模型,特别是使用HuggingFace的SentenceClassification模型。用户可以根据需要选择不同的任务配置,并使用训练、验证和测试分割进行模型训练和评估。数据集的每个实例都包含文本和标签信息,方便进行分类任务的研究和应用。
背景与挑战
背景概述
在社交媒体的海洋中,推文作为信息交流的重要载体,其内容的多义性和语境的多样性为文本分析带来了诸多挑战。TweetEval数据集应运而生,它是由Cardiff NLP团队创建的,旨在提供一个统一的基准,用于评估和比较不同推文分类任务的性能。该数据集涵盖了表情符号识别、情绪分析、仇恨言论检测、讽刺识别、冒犯性内容检测、立场分析和情感分析等多个任务。TweetEval的创建为研究人员和开发人员提供了一个宝贵的资源,以促进自然语言处理技术在社交媒体文本分析中的应用和研究。
当前挑战
TweetEval数据集在多个方面面临着挑战。首先,推文文本的多样性和多义性使得分类任务变得复杂,特别是在讽刺和冒犯性内容的识别上。其次,推文数据往往包含大量的非正式语言、俚语和网络用语,这些都增加了自然语言处理模型的难度。此外,由于数据集的构建依赖于Twitter平台,因此数据收集和标注过程需要遵守Twitter的服务条款和API使用政策,这可能会对数据的完整性和可用性产生影响。最后,数据集的规模和多样性也要求在模型训练和评估过程中采用有效的数据处理和模型调整策略,以应对不同任务的特定挑战。
常用场景
经典使用场景
作为社交媒体文本分析的标准基准之一,TweetEval数据集广泛应用于自然语言处理领域,特别是文本分类任务。该数据集包含了多样化的微博内容,涵盖了情感、立场、讽刺、侮辱、仇恨言论等多个维度,为研究者提供了丰富的实验材料。例如,在情感分析任务中,研究者可以训练模型识别微博中的正面、中立或负面情绪;在立场分析任务中,模型需要判断用户对于某一特定议题的支持或反对态度。TweetEval数据集的多样性和规模使其成为评估文本分类模型性能的重要参考。
解决学术问题
TweetEval数据集解决了自然语言处理中微博文本分类的多样性问题,为模型训练提供了全面的数据支持。通过将多个相关任务整合在一个统一框架下,TweetEval促进了跨任务模型共享和知识迁移的研究。此外,该数据集的标准化格式和数据分割方式为模型训练和评估提供了统一的基准,有助于研究者之间的公平比较和交流。TweetEval数据集的出现对文本分类任务的研究产生了深远影响,推动了社交媒体文本分析领域的发展。
衍生相关工作
TweetEval数据集的发布衍生了大量的相关研究工作,推动了社交媒体文本分析领域的深入探索。例如,基于该数据集的研究者们提出了多种改进的文本分类模型,如深度学习模型、注意力机制模型等,显著提高了微博文本分类的性能。此外,TweetEval数据集还激发了跨模态信息融合的研究,将文本信息与其他模态信息(如图像、视频等)相结合,实现更全面、更准确的微博内容分析。这些研究成果为社交媒体文本分析领域的发展提供了有力支持,促进了相关技术的创新和应用。
以上内容由遇见数据集搜集并总结生成


