rag-consistency-test-14
收藏Hugging Face2026-05-13 更新2026-05-15 收录
下载链接:
https://huggingface.co/datasets/llm-consistency/rag-consistency-test-14
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是一个用于评估和比较大型语言模型在帮助性、安全性、真实性等维度上表现的多配置偏好对齐数据集,包含两个主要配置:get_help_steer_3_no_history 和 help_steer_3,每个配置下包含多个由不同模型生成的数据子集。每个数据样本包括多轮对话上下文(由角色和内容组成)、两个候选回答(A和B)、人工标注的真实偏好标签(ground_truth),以及一系列用于深入分析模型行为的元数据和指标,如上下文长度、历史长度、解析失败次数、位置偏差(偏向第一个或第二个答案)、平局不一致性等,专门用于量化模型在生成答案时的系统性偏差。数据子集来源于多个知名AI模型和机构,如MiniMaxAI、Google Gemma、Swiss AI的Apertus模型、ZAI的GLM等,每个子集包含300个样本,使用不同的提示模板(如human_template, gepa_apertus8b_template)生成。该数据集适用于模型对齐研究、偏好建模、偏差检测、多模型比较等任务。
This dataset is a multi-configuration preference alignment dataset designed for evaluating and comparing the performance of large language models across dimensions such as helpfulness, safety, and truthfulness. It includes two main configurations: get_help_steer_3_no_history and help_steer_3, each containing multiple data subsets generated by different models. Each data sample consists of a multi-turn dialogue context (composed of roles and content), two candidate responses (A and B), a human-annotated ground truth preference label, and a series of metadata and metrics for in-depth analysis of model behavior. These metrics include context length, history length, parsing failures, position bias (favoring the first or second answer), tie inconsistency, etc., specifically designed to quantify systematic biases in model-generated answers. The data subsets are sourced from various well-known AI models and organizations, such as MiniMaxAI, Google Gemma, Swiss AIs Apertus model, ZAIs GLM, etc., with each subset containing 300 samples generated using different prompt templates (e.g., human_template, gepa_apertus8b_template). This dataset is suitable for tasks like model alignment research, preference modeling, bias detection, and multi-model comparison.
创建时间:
2026-05-13
搜集汇总
数据集介绍
构建方式
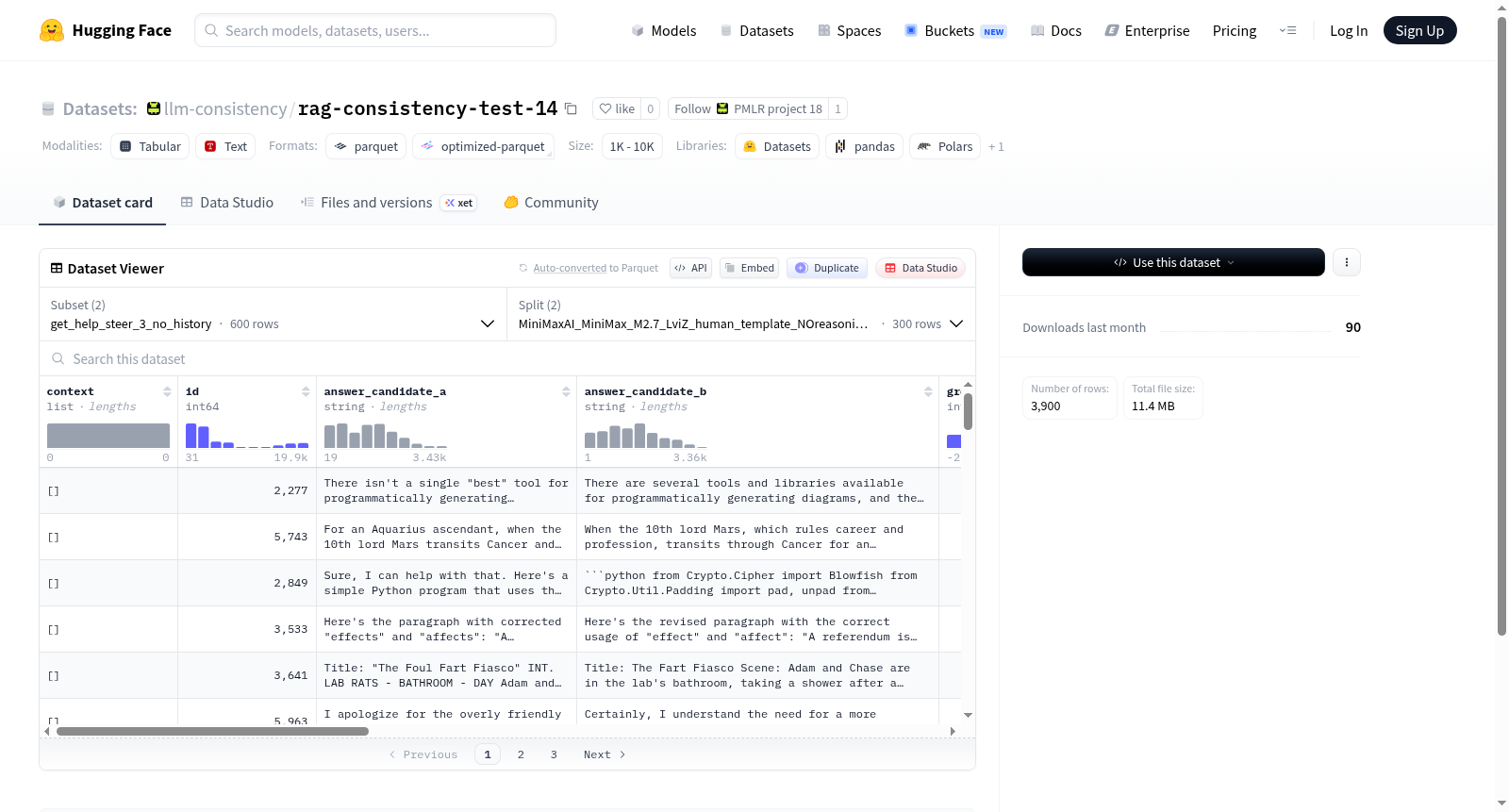
在检索增强生成(RAG)系统的评估中,模型输出的一致性至关重要。rag-consistency-test-14数据集旨在系统性地测评大语言模型在RAG场景下的回答一致性,通过设计包含对话上下文、两个候选答案(answer_candidate_a与answer_candidate_b)及其对应的真实标签(ground_truth)的结构化样本,构建了评估基准。数据集分为get_help_steer_3_no_history与help_steer_3两个配置,分别对应无历史记录与包含历史记录的交互场景。每个样本还记录了模型对候选答案的多轮提取标签(extracted_labels)、解析失败次数(parse_failures)以及位置偏差指标(如ab_difference、bias_toward_first_position等),从而全面捕捉答案排序与重复输出中的不一致性。
特点
该数据集的核心特点在于其精细的偏差与一致性度量体系,包括对位置偏差(bias_toward_first_position、bias_toward_second_position)和平局不一致性(tie_inconsistency)的二值化标注,以及通过ab_difference、ba_difference和shift等数值指标量化模型在正反顺序下选择偏好的变化程度。此外,数据集囊括了来自MiniMaxAI、swiss_ai、google、zai_org等多个机构的不同规模与版本的生成模型(如MiniMax_M2.7、Apertus系列、Gemma 4系列、GLM-4.7等)的评估结果,每个模型对应一个独立的数据拆分(split),包含300条样本,使得跨模型的一致性对比成为可能。
使用方法
研究者可通过HuggingFace Datasets库便捷加载本数据集,依据config_name参数选择无历史(get_help_steer_3_no_history)或含历史(help_steer_3)的子集,并借助split参数定位特定模型的评估结果。数据集中,context字段以对话角色与内容列表的形式呈现输入,answer_candidate_a与answer_candidate_b构成待比较的响应对,ground_truth提供参考基准。提取的labels及各种偏差指标可直接用于计算模型的一致性得分、位置敏感度或平局解析稳定性,支持对RAG系统输出质量的量化诊断与多模型比较分析。
背景与挑战
背景概述
在检索增强生成(RAG)系统蓬勃发展的当下,如何确保生成内容在不同上下文中的语义一致性与无偏性,已成为评估大语言模型(LLMs)可靠性的核心议题。该数据集由多个研究机构(如MiniMaxAI、Swiss AI及Google团队)共同构建,旨在系统性量化模型在给定上下文时对候选答案的偏好偏差。其核心研究问题聚焦于测试LLMs在面对相同语义但不同表述的答案对时,是否因位置、历史信息或指令模板差异而产生不稳定判断。该数据集通过人工与多种生成模板(如gepa、mipro)标注的对比样本,为评估模型在零推理场景下的鲁棒性提供了标准化基准,对推动RAG系统在事实性与一致性方面的优化具有显著影响力。
当前挑战
该数据集所解决的领域挑战在于揭示并校正RAG系统中模型对答案位置(如首位偏好或次位偏好)及模板变化的敏感性,避免因生成偏差导致信息误判。在构建过程中,首要挑战是设计能够消除语义歧义且严格等价的答案对,确保ground truth的唯一性并排除人为标注噪声;其次,需协调不同规模模型(如8B至70B参数)生成的答案差异,通过统一模板(如NOreasoning)控制变量,但各模型对指令的遵循程度仍会导致解析失败与标签提取偏差。此外,历史长度与上下文长度的多样性要求数据集具备跨对话场景的泛化能力,而身份偏差(如tie_inconsistency)的量化则依赖于大规模对比实验的精细化设计。
常用场景
经典使用场景
在检索增强生成(RAG)系统的评估领域,该数据集被广泛用于衡量模型对上下文与生成答案之间一致性的把握能力。其核心设计在于通过提供对话历史与候选答案,让研究者能够精准量化模型在面对不同检索片段时,其输出是否与给定上下文保持逻辑自洽,特别适用于判断模型是否存在位置偏差或平局不一致性等问题。
解决学术问题
该数据集聚焦于解决RAG系统中生成内容与检索上下文之间的一致性度量这一关键学术难题。传统评估多关注答案的准确性,却忽视了模型是否真正理解了检索到的信息并加以合理运用。通过精细标注的位置偏差与一致性指标,它使得研究者能够系统性地分析模型在复杂对话场景下的鲁棒性,推动了RAG系统评估从单纯性能比较向更深层次的认知一致性研究迈进。
衍生相关工作
基于该数据集已衍生出多项关于RAG一致性评测的经典研究工作,包括探索不同推理策略(如思维链)对减少位置偏差的影响,以及设计更细粒度的提示模板以增强模型对检索内容的依赖。此外,相关成果还推动了自动化评估管线的构建,这些管线利用数据集中提取的ab_difference与shift指标,实现了对模型一致性漂移的实时监控,为后续开发更鲁棒的RAG系统奠定了基础。
以上内容由遇见数据集搜集并总结生成


