June30916/multimodality-poc-llama31-ruler16k
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/June30916/multimodality-poc-llama31-ruler16k
下载链接
链接失效反馈官方服务:
资源简介:
---
license: other
task_categories:
- feature-extraction
language:
- en
tags:
- kv-cache
- attention
- llama
- ruler
- multimodality
- gaussian-mixture
- expected-attention
pretty_name: Pre-RoPE query / hidden state corpus for KV-cache compression research (Llama-3.1-8B, RULER-16K)
size_categories:
- 10B<n<100B
---
# Multimodality PoC corpus — Llama-3.1-8B-Instruct on RULER-16K
Raw pre-RoPE query and hidden-state tensors captured during prefill, used
to study whether the per-(layer, kv_head) query distribution is unimodal
Gaussian (the assumption underpinning Expected Attention's MGF closed-form
in [`kvpress`](https://github.com/NVIDIA/kvpress)).
## What's in here
- 65 `.npz` files, one per (RULER task, prompt_index) pair (13 tasks × 5
prompts).
- Each file (~414 MB) contains:
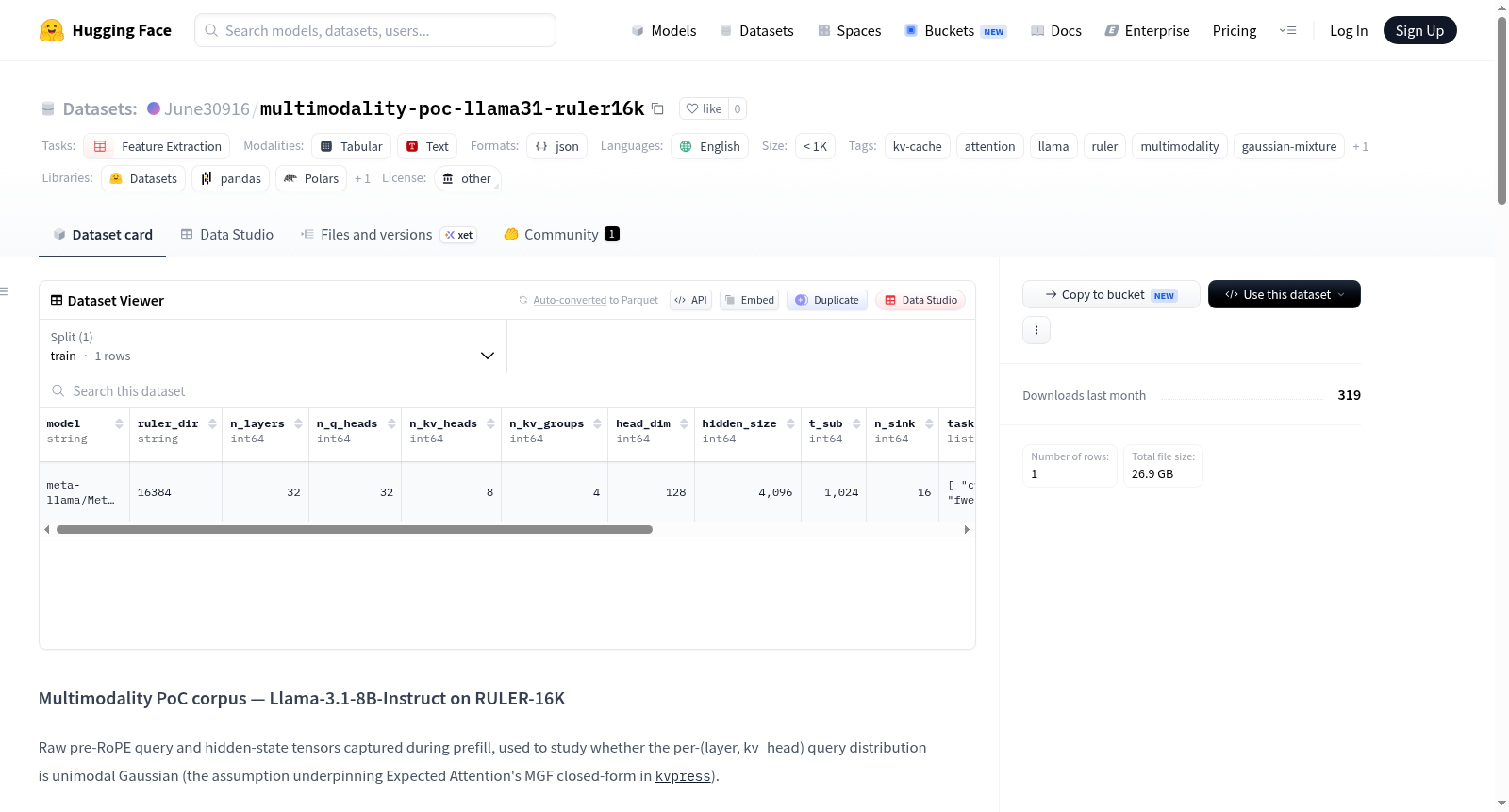
| field | dtype | shape | meaning |
|--------------|----------|--------------------------------------|------------------------------------------------------|
| `hidden` | float16 | `[n_layers=32, T_sub=1024, 4096]` | input hidden state to each attention block |
| `queries` | float16 | `[n_layers=32, n_q_heads=32, T_sub=1024, head_dim=128]` | pre-RoPE queries via `q_proj(hidden)` |
| `positions` | int32 | `[1024]` | sub-sampled prefill positions |
| `task` | str | scalar | RULER task name |
| `prompt_idx` | int64 | scalar | row index into the RULER subset |
| `k_len` | int64 | scalar | original prompt length |
- `meta.json` — global config + per-task list of prompt_idx values.
Total size: ~26 GB.
## Capture details
- Model: `meta-llama/Meta-Llama-3.1-8B-Instruct`, bf16, flash-attention-2.
- Dataset: [`simonjegou/ruler`](https://huggingface.co/datasets/simonjegou/ruler), `data_dir="16384"`, split `test`.
- For each (task, prompt) pair:
1. Run a single prefill (`use_cache=False`).
2. Capture `hidden_states` via a `forward_pre_hook` on each
`LlamaDecoderLayer.self_attn`.
3. Apply each layer's `q_proj` to the captured hidden to get pre-RoPE
queries.
4. Drop the first 16 tokens (sink prefix) and uniformly sub-sample 1024
positions (deterministic seed).
- T_sub=1024, n_sink=16, max_length=16384.
## Reproducing the capture
The collector is in the source repo at `PoC/multimodality_poc.py`:
```bash
python PoC/multimodality_poc.py \
--model meta-llama/Meta-Llama-3.1-8B-Instruct \
--device cuda:0
```
## Loading
```python
import numpy as np
from huggingface_hub import hf_hub_download
path = hf_hub_download(
repo_id="June30916/multimodality-poc-llama31-ruler16k",
repo_type="dataset",
filename="prompt_niah_multikey_1__p0.npz",
)
z = np.load(path, allow_pickle=False)
print(z["hidden"].shape, z["queries"].shape, str(z["task"]))
```
To pull everything:
```python
from huggingface_hub import snapshot_download
local = snapshot_download(
repo_id="June30916/multimodality-poc-llama31-ruler16k",
repo_type="dataset",
)
```
## Findings on this corpus
Run on this data:
- 98 % of (L, h_kv, prompt) units reject K=1 (Expected Attention's
Gaussianity assumption) by ΔBIC > 10.
- Median best-K (BIC) = 5 at the kv-head granularity.
- GMM is well-specified: 98 % pass PIT-Kolmogorov-Smirnov goodness-of-fit
for the BIC-best K; GMM\* dominates a Silverman-bandwidth KDE in
log-likelihood for 100 % of units.
- K is task-conditional and prompt-conditional; the unit-level mean K\*
is rank-stable across prompts (Spearman ρ = 0.927).
See `MULTIMODALITY_ANALYSIS.md` in the source repo for the full writeup.
## License & ethics
The captured tensors are intermediate activations of
`meta-llama/Meta-Llama-3.1-8B-Instruct` over public RULER prompts. Use is
governed by Meta's Llama 3.1 community license. No human data, no PII.
## Citation
If you use this corpus, please cite the source repository (TBA) and the
underlying datasets:
- `simonjegou/ruler` (RULER benchmark)
- `meta-llama/Meta-Llama-3.1-8B-Instruct`
A pre-RoPE query / hidden-state corpus for KV-cache compression research, consisting of raw tensors captured during prefill of the Llama-3.1-8B-Instruct model on the RULER-16K dataset. The dataset includes 65 .npz files, each ~414 MB, totaling ~26 GB. Each file contains hidden states, pre-RoPE queries, sub-sampled prefill positions, task name, prompt index, and original prompt length. The dataset is used to study whether the per-(layer, kv_head) query distribution is unimodal Gaussian, the assumption underpinning Expected Attentions MGF closed-form.
提供机构:
June30916
搜集汇总
数据集介绍
构建方式
本数据集旨在为键值缓存压缩研究提供底层神经活动数据,其构建依托于Llama-3.1-8B-Instruct模型在RULER-16K基准上的预填充过程。具体而言,针对RULER的13项任务,每项任务随机抽取5条提示构成60个独立样本。在每一样本的预填充阶段,通过将前向预钩子挂载至每个解码器层的自注意力模块,捕获各层输入隐藏状态;其后利用各层的查询投影矩阵将这些隐藏状态转换为旋转位置编码之前的原始查询张量。为控制数据规模,在剔除起始16个标记后,采用确定性种子均匀子采样得到1024个位置,最终储存为65个npz文件,合计约26 GB。
特点
该数据集的核心特点在于其专为探究注意力查询分布的多模态性而设计,每个npz文件包含32层的隐藏状态、预旋转位置编码的查询张量、子采样位置索引及任务与提示元信息。基于此数据集的实证分析揭示,98%的(层、键值头、提示)组合均拒绝单一高斯分布的假设,且最优高斯混合模型的分量数中位数为5。进一步统计检验表明混合模型具有良好拟合优度,其分布特性呈现任务条件性与提示条件性,且键值头层级的最优分量数在跨提示间保持高度秩稳定性。
使用方法
用户可通过HuggingFace Hub便捷获取数据。推荐使用huggingface_hub库的snapshot_download函数一键下载全部文件至本地目录。亦可针对特定样本,使用hf_hub_download指定文件名后以numpy.load加载单个npz文件,解析其中的张量进行自定义分析。数据集的元配置文件meta.json提供了全局参数及每任务对应的提示索引列表,便于批量处理与任务对齐。原始捕获脚本PoC/multimodality_poc.py亦发布于源仓库,支持用户调整参数后复现采集过程或扩展至其他模型。
背景与挑战
背景概述
在大型语言模型(LLM)的推理优化领域,键值缓存(KV-cache)压缩技术是提升长序列处理效率的核心手段。现有方法如Expected Attention基于每层每个KV头(kv_head)的查询分布服从单峰高斯分布的假设,以闭式矩母函数(MGF)实现近似压缩。然而,该假设的普适性尚未经过系统验证。为此,研究者于2024年构建了multimodality-poc-llama31-ruler16k数据集,基于Llama-3.1-8B-Instruct模型在RULER-16K基准(13种任务、5个提示共65个样本)上捕获了预填充阶段的预RoPE查询与隐藏状态张量。该数据集由June30916主导创建,旨在系统检验查询分布的多模态性,为构建更鲁棒的KV-cache压缩方案提供实证基础,对高效LLM推理研究具有重要的方法论推动作用。
当前挑战
该数据集所应对的核心领域挑战在于:Expected Attention等KV-cache压缩方法依赖的查询单峰高斯假设缺乏实证检验,而实际中查询分布可能呈现多模态特性,导致压缩质量不稳定。具体挑战包括:1)验证假设的困难:需要在大规模、多任务场景下捕获中间张量,计算密集且存储开销巨大(本数据集达26GB);2)分布评估的维度问题:需在32层、32个查询头的粒度下,联合评估13种不同RULER任务(如键值检索、多键追踪)的查询分布差异,计算效率和统计显著性难以平衡;3)数据获取的复杂性:捕获过程需精细处理预填充阶段(16K长度)、下采样策略(移除16个sink token后均匀采样1024位置),并确保跨提示的复现性与一致性,对工程实现要求严苛。
常用场景
经典使用场景
在长上下文Transformer模型的高效推理研究中,multimodality-poc-llama31-ruler16k数据集扮演着关键角色。该数据集捕获了Llama-3.1-8B-Instruct模型在RULER-16K基准上预填充阶段产生的预RoPE查询与隐藏状态张量,为探索键值缓存压缩技术提供了微观层面的数据支撑。其经典使用场景集中于验证“期望注意力”机制中关于查询向量呈单峰高斯分布的核心假设——这一假设是NVIDIA kvpress库中矩生成函数闭式解的理论基石。通过提供每个注意力层和键值头在1024个均匀子采样位置上的原始张量数据,研究者能够精细地检验高斯混合模型对多头注意力行为的拟合优度。
实际应用
在实际部署中,该数据集直接服务于大语言模型的推理加速与内存优化。随着上下文窗口扩展至16K token以上,键值缓存的内存占用成为服务端推理的核心瓶颈。基于此数据集的研究成果,工程师能够设计出非参数化的键值缓存压缩方案,例如利用高斯混合模型对注意力查询分布进行在线建模,从而在不牺牲生成质量的前提下选择性缓存关键张量。同时,该数据集也为硬件协同设计提供了参考——分析出的最优混合成分数分布可指导定制化注意力核的实现,通过预计算查询密度函数来跳过冗余的注意力计算。这种数据驱动的压缩策略有望将长序列推理的端到端吞吐量提升数倍,使超长上下文应用如文档问答和代码库理解变得经济可行。
衍生相关工作
该语料库的发布催生了一系列高阶研究工作。一方面,它推动了注意力分布的非参数建模浪潮,如混合稀疏注意力方法利用数据集揭示的层间分布异质性,为不同层级定制差异化压缩率。另一方面,跨提示分布稳定性分析启发了分布预测式缓存调度策略,研究者利用Spearman相关系数在0.927水平的观测,开发出基于历史缓存的查询密度预测器。此外,高斯混合模型拟合优度检验方法被反向移植到模型剪枝领域,衍生出通过注意力头冗余度进行结构化剪枝的新框架。这些后代工作共同构筑了从统计建模到系统优化的完整技术链条,而本数据集作为关键验证基准,持续影响着大模型推理基础设施的设计哲学。
以上内容由遇见数据集搜集并总结生成


