tasksource/mmlu
收藏Hugging Face2025-07-18 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/tasksource/mmlu
下载链接
链接失效反馈官方服务:
资源简介:
MMLU数据集(在HuggingFace上称为`hendrycks_test`)是一个去除了辅助训练数据的轻量级版本,比原始版本更小(7MB vs 162MB)且更快。该数据集适用于文本分类、多项选择、问答等任务,并且是多任务学习的基准数据集。
The MMLU dataset (referred to as `hendrycks_test` on HuggingFace) is a lightweight variant that excludes auxiliary training data. It is smaller (7 MB versus 162 MB) and faster than the original version. This dataset is applicable to tasks such as text classification, multiple choice, and question answering, and serves as a benchmark dataset for multi-task learning.
提供机构:
tasksource
原始信息汇总
数据集概述
基本信息
- 许可证: Apache-2.0
- 任务类别:
- 文本分类
- 多选题
- 问答
- 任务ID:
- 多选题问答
- 开放领域问答
- 封闭领域问答
- 语言: 英语
- 标签:
- 多任务
- 多任务学习
- MMLU
- hendrycks_test
- 美观名称: mmlu
数据集特点
- 此版本为MMLU (
hendrycks_teston huggingface)的简化版,不包含辅助训练数据。 - 相较于原版,此版本更轻量(7MB vs 162MB)且加载速度更快。
引用信息
- 原始数据集参考: Measuring Massive Multitask Language Understanding
- 学术论文:
- 标题: Measuring Massive Multitask Language Understanding
- 作者: Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, Jacob Steinhardt
- 期刊: Proceedings of the International Conference on Learning Representations (ICLR)
- 年份: 2021
搜集汇总
数据集介绍
构建方式
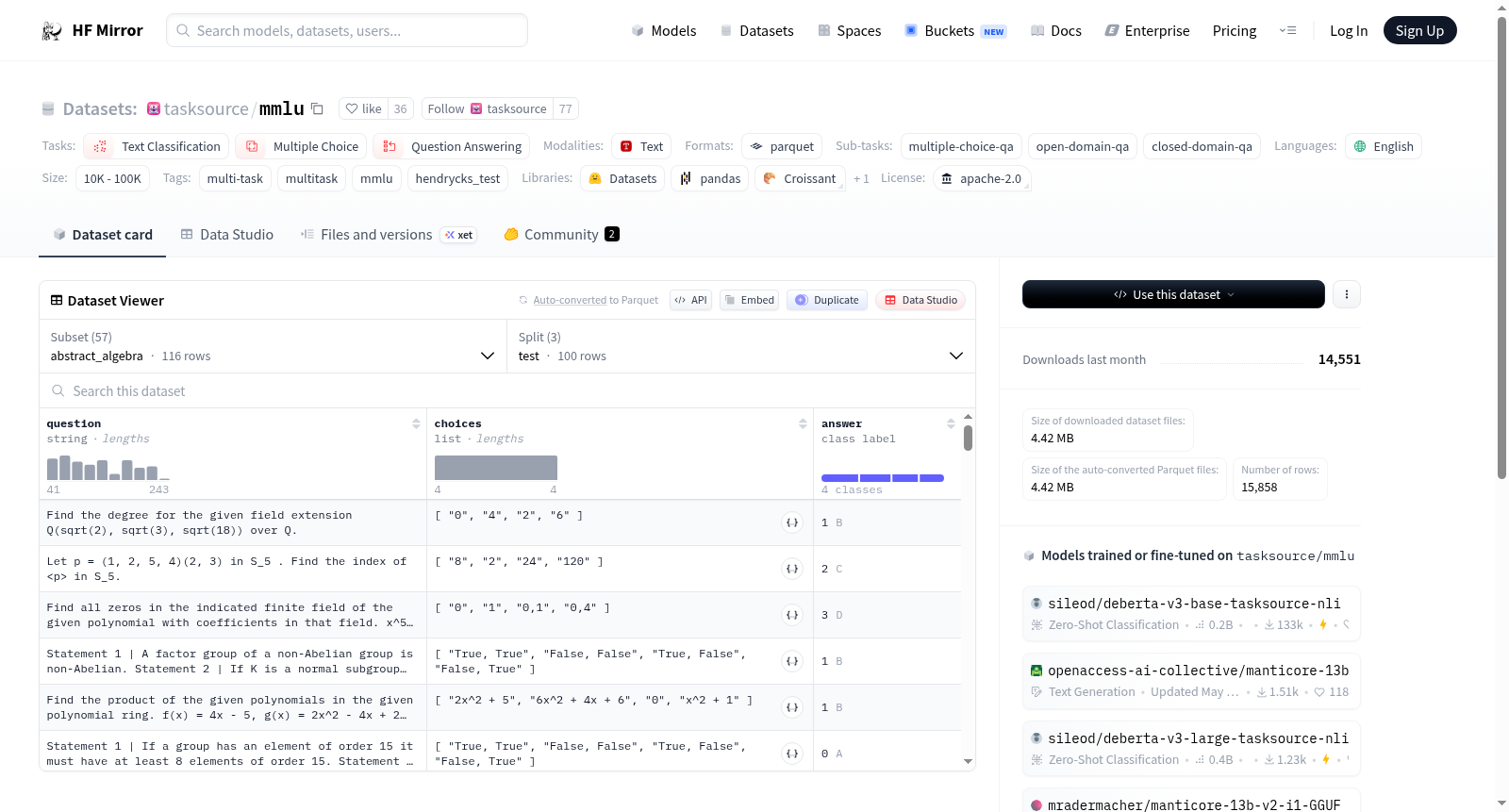
在人工智能领域,大规模多任务语言理解(MMLU)数据集的构建旨在全面评估模型的多学科知识掌握能力。该数据集通过精心筛选涵盖57个不同学科领域的专业问题,每个问题均采用四选一的多项选择题形式。构建过程涉及从权威教材、学术文献和标准化考试中提取高质量内容,确保问题具有明确的正确答案和严谨的学科代表性。数据被划分为测试集、验证集和开发集,以支持模型的训练、调优和评估,为语言模型的综合能力测评提供了坚实的基准。
特点
MMLU数据集以其广泛的学科覆盖和深度知识层次而著称,涵盖了从基础学科如初等数学到专业领域如医学遗传学的多样化主题。每个子数据集均包含结构化的问答对,问题设计注重逻辑严谨性和知识准确性,选项设置避免了歧义性。数据集的规模庞大,总计包含超过15,000个问题,且每个学科的问题数量经过平衡设计,确保了评估的全面性和公平性。这种多维度、高难度的特性使其成为衡量语言模型跨领域推理能力的黄金标准。
使用方法
使用MMLU数据集时,研究人员可通过HuggingFace平台直接加载特定学科的子集,例如“abstract_algebra”或“clinical_knowledge”。数据集适用于多项选择题回答任务,模型需根据问题文本从四个选项中选择正确答案。典型流程包括利用开发集进行少量样本学习,使用验证集进行超参数调优,最终在测试集上评估模型性能。该数据集支持零样本、少样本和微调等多种评估范式,为语言模型的泛化能力和知识迁移研究提供了灵活的实验框架。
背景与挑战
背景概述
在人工智能领域,大规模多任务语言理解(MMLU)数据集由Dan Hendrycks及其团队于2020年创建,旨在评估模型在广泛学科知识上的综合理解能力。该数据集覆盖了从基础科学到人文社科的57个学科,共计超过15,000道多项选择题,其核心研究问题聚焦于衡量模型在复杂、专业语境下的推理与知识应用水平。MMLU的出现标志着自然语言处理从单一任务评估向多维度、跨领域能力验证的转变,为大型语言模型的性能基准设立了新的标准,对推动通用人工智能的发展产生了深远影响。
当前挑战
MMLU数据集旨在解决模型在多样化、专业化知识领域的理解与推理挑战,其问题设计需平衡深度与广度,确保涵盖从抽象代数到临床医学的广泛主题,同时避免偏见与歧义。在构建过程中,挑战主要源于学科知识的准确性与时效性维护,以及高质量标注数据的获取,这要求团队具备跨学科专家协作与严格的质量控制流程。此外,数据集的规模与复杂性对评估方法的标准化提出了更高要求,以确保模型比较的公平性与可重复性。
常用场景
经典使用场景
在自然语言处理领域,大规模多任务语言理解(MMLU)数据集作为评估模型跨学科知识能力的基准工具,其经典使用场景集中于对语言模型进行零样本或少样本的多选题测试。该数据集覆盖了从基础科学到人文社科的57个学科,研究者通过模型在未见过的学科问题上的表现,系统性地衡量其泛化能力和知识广度。这种评估方式不仅揭示了模型在特定领域的理解深度,还为比较不同架构或训练策略的性能提供了标准化平台。
解决学术问题
MMLU数据集有效解决了人工智能研究中模型知识评估碎片化与片面性的核心问题。传统评估往往局限于单一领域,难以全面反映模型的世界知识水平。该数据集通过构建多学科、多难度的标准化测试集,使研究者能够量化模型在专业领域的认知边界,识别其知识盲区。这一工具推动了语言模型从表层模式匹配向深层知识推理的转变,为构建具备人类水平理解能力的通用人工智能奠定了评估基础。
衍生相关工作
围绕MMLU数据集衍生的经典研究包括Chain-of-Thought提示策略的优化、专家混合模型的架构创新以及知识增强型预训练方法的探索。例如,研究者通过分析模型在不同学科的错误模式,提出了分层知识注入技术;基于MMLU的细粒度性能分析,催生了针对专业领域的适配器微调范式。这些工作不仅提升了模型在MMLU上的表现,更推动了知识密集型NLP任务的整体进展,形成了以学科知识评估为核心的研究脉络。
以上内容由遇见数据集搜集并总结生成


