CCB/cis5300-text-classification
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/CCB/cis5300-text-classification
下载链接
链接失效反馈官方服务:
资源简介:
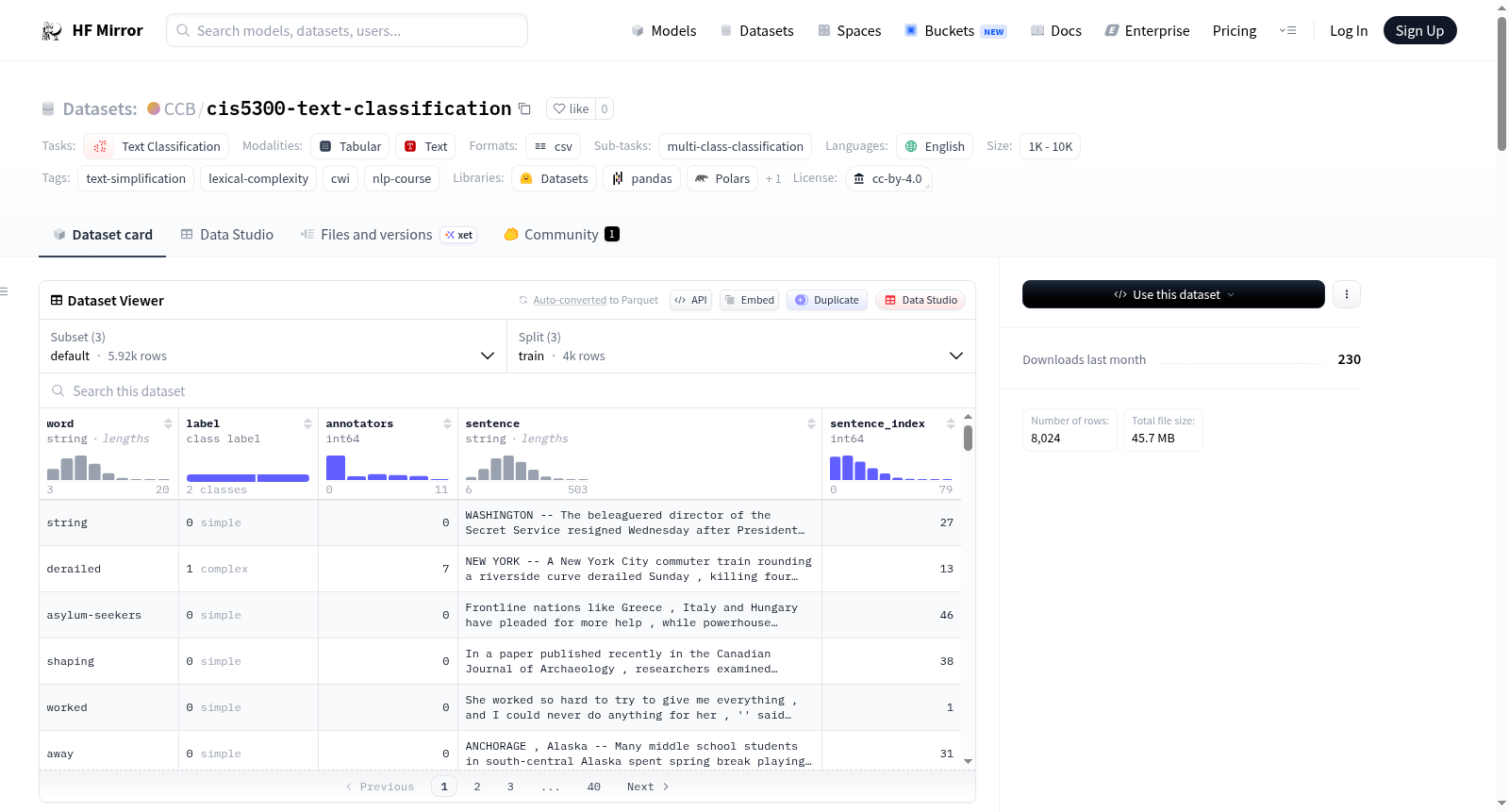
该数据集支持复杂词识别(CWI)任务:给定上下文中的一个词,预测其是否为复杂词(可能对非母语者、儿童或有阅读障碍的人造成困难)或简单词。CWI是词汇简化的第一步——即重写文本使其更易于理解的任务。在简化一个词之前,需要先识别哪些词需要简化。数据集包括一个主配置(包含训练、验证和测试集)和两个用于评估模型泛化能力的领域特定测试集(生物医学和新闻领域)。数据集中的每个词由约10名标注者独立标注,标注结果通过阈值转换为二元标签(简单或复杂)。数据集来源于新闻文章,由母语和非母语的英语使用者标注,旨在识别对非母语者、儿童或有阅读障碍的人可能困难的词。
This dataset supports the Complex Word Identification (CWI) task: given a word in context, predict whether it is complex (likely to be difficult for non-native speakers, children, or people with reading disabilities) or simple. CWI is the first step in lexical simplification — the task of rewriting text to make it more accessible. Before you can simplify a word, you need to identify which words need simplification. The dataset includes a main configuration with train, validation, and test splits, as well as two additional domain-specific test sets (biomedical and news) for evaluating model generalization. Each word in the dataset was independently labeled by approximately 10 annotators, and the labels were binarized using a threshold (simple or complex). The dataset is drawn from news articles and annotated by both native and non-native English speakers to identify words that could be difficult for non-native speakers, children, or people with reading disabilities.
提供机构:
CCB
搜集汇总
数据集介绍
构建方式
该数据集以复杂词汇识别任务为核心,源自Kriz等人于NAACL-HLT 2018提出的词汇简化研究。核心数据从新闻语料中抽取词汇,经由约10名标注者(涵盖母语与非母语英语使用者)独立判断该词是否对非母语者、儿童或阅读障碍者构成理解困难。基于标注一致性,数据通过二值化阈值进行筛选:当所有标注者均判定为简单时(标注者计数为0),标记为简单类;当至少三名标注者认定复杂时(计数≥3),标记为复杂类;而介于1至2名标注者的模糊样本则被剔除,确保了标签的清晰可靠性。此外,数据集扩展了两个领域泛化测试集——生物医学领域源自CompLex数据,新闻领域源自CWI 2018共享任务,均将连续复杂度分数以0.5为阈值二值化,形成统一标签体系。
特点
数据集具备结构化的多领域特性与精细的标注信息。核心配置包含训练集4000例、验证集1000例及测试集922例,每个样本提供目标词汇、完整上下文句子、词汇在句中的索引位置以及标注者计数。标签采用明确的简单/复杂二分类,且仅保留标注共识清晰的样本,排除了中间模糊地带,提高了监督信号的信噪比。此外,数据集专设生物医学与新闻两个领域泛化配置,分别包含289和1813个测试样本,便于评估模型跨领域迁移能力。配套的Google Books N-gram词频文件(约870万条)可作为额外的特征资源,丰富了实验设计的灵活性。
使用方法
该数据集通过HuggingFace Datasets库便捷加载,默认可通过load_dataset('CCB/cis5300-text-classification')获取训练、验证与测试划分。针对领域泛化评估,通过指定config参数为'biomedical'或'news'即可加载对应测试集。每个样本以字典形式返回,包含word、label、sentence等字段,可直接用于文本分类模型的输入。补充的n-gram计数文件需通过huggingface_hub库下载并解压后以字典形式读取,用以提取词频特征。该数据集设计紧密贴合NLP课程作业,支持从基于规则(如词长、词频阈值)到机器学习模型(如朴素贝叶斯、逻辑回归),再到自定义特征工程的渐进式实验流程,并鼓励在跨领域场景下进行鲁棒性分析。
背景与挑战
背景概述
该数据集由宾夕法尼亚大学Reno Kriz、Eleni Miltsakaki、Marianna Apidianaki及Chris Callison-Burch于2018年创建,源自NAACL-HLT会议论文,聚焦复杂词汇识别任务,旨在通过上下文判断单词是否对非母语者、儿童或阅读障碍人群构成理解障碍。作为词汇简化的基础步骤,该任务对提升文本可读性与包容性具有关键意义。数据集基于新闻语料,经母语与非母语者联合标注,采用严格阈值筛选清晰案例,并引入生物医学与新闻两个领域测试集以评估模型泛化能力,已成为自然语言处理教学中文本分类任务的标志性资源。
当前挑战
领域挑战在于词汇复杂度判定高度依赖上下文与受众认知差异,同一词汇在不同语境或群体中复杂度迥异,而现有模型常因缺乏对语义、语用及语言背景的深层理解,难以准确识别。构建过程中,标注者间一致性低是核心难题,原始注释通过十人标注后仅保留极端明确样本(无人标记为简单或三人以上标记为复杂),剔除歧义区间,牺牲数据量以保质量。此外,跨领域泛化要求模型适应生物医学抽象与新闻话语的词汇分布鸿沟,而额外词频特征的处理亦需高效集成以增强分类鲁棒性。
常用场景
经典使用场景
在自然语言处理领域,词汇复杂性识别是文本简化任务的关键前置步骤。cis5300-text-classification数据集专为复杂词汇识别这一二分类任务而设计,其经典使用场景聚焦于判断给定上下文中某个词汇是否属于复杂词——即对非母语者、儿童或阅读障碍群体而言难以理解的词汇。该数据集提供了包含目标词汇、完整句子、标注者信息及句子索引的结构化样本,训练集、验证集和测试集分别包含4000、1000和922个实例,为构建并评估从简单基线模型到机器学习分类器的各类方法提供了标准化基准。
解决学术问题
该数据集致力于解决词汇简化研究中一个基础且核心的学术问题:如何自动、准确地从连续文本中甄别出需要被简化的复杂词汇。通过对词汇进行清晰标注,并排除标注者意见分歧的模糊区域,它有效定义了词汇复杂性的二元边界,为研究词汇层面可读性度量、文本自适应及辅助技术提供了可靠的实验平台。该数据集的发布推动了复杂词汇识别任务从规则驱动向数据驱动方法的转变,其引入的跨领域测试集(生物医学与新闻)更是促使学界关注模型在不同语体间的泛化能力,从而深化了对词汇复杂性本质的理解。
衍生相关工作
围绕这一核心数据集,学术界已衍生出多项具有影响力的经典工作。其中,Kriz等人(2018)将其作为上下文相关词汇替换与释义简化系统的评估基准,开创性地将词汇识别与下游简化任务相联结。生物医学配置源自CompLex数据集(Shardlow等,2020),它催生了对专业领域术语复杂性建模的专门研究;新闻配置则继承自CWI 2018共享任务(Yimam等,2018),该任务自设立以来已成为词汇简化领域的重要比较平台。这些衍生产物不仅拓展了CWI任务的疆域,更推动了多领域、多视角下词汇复杂性量化研究的繁荣发展。
以上内容由遇见数据集搜集并总结生成


