OpenBahasa-CoT
收藏Hugging Face2026-05-18 更新2026-05-20 收录
下载链接:
https://huggingface.co/datasets/hadadxyz/OpenBahasa-CoT
下载链接
链接失效反馈官方服务:
资源简介:
OpenBahasa-CoT是一个高质量的印度尼西亚语数据集,专门设计用于增强大语言模型在训练过程中的推理能力。它侧重于提升结构化思维、逐步推理和跨多种任务的连贯回答生成,所有示例均使用自然印度尼西亚语编写,以确保与真实世界使用场景和语言模式对齐。数据集中的每个样本都经过精心设计,展示清晰且逻辑性强的思维过程,帮助模型学习如何以一致、可解释的方式推理问题,并将问题分解为逻辑步骤。数据集涵盖基础推理、中级推理、高级推理和复杂推理等多个难度级别,适用于训练/预训练、监督微调、指令微调和推理增强等应用场景。它包含user、reasoning和assistant三个必需字段,其中assistant字段整合了推理过程和最终答案。目前,数据集被分为多个子集,并仍在持续扩展和改进中。
OpenBahasa-CoT is a high-quality Indonesian language dataset specifically designed to enhance the reasoning capabilities of large language models during training. It focuses on improving structured thinking, step-by-step reasoning, and coherent answer generation across multiple tasks. All examples in the dataset are written in natural Indonesian, ensuring better alignment with real-world usage scenarios and language patterns. Each sample is carefully designed to demonstrate clear and logical thought processes, enabling models to better understand how to reason through problems in a consistent, interpretable, and explainable manner. The dataset covers multiple difficulty levels, including basic, intermediate, advanced, and complex reasoning tasks, and is suitable for applications such as training/pre-training, supervised fine-tuning, instruction fine-tuning, and reasoning enhancement pipelines. It includes three required fields: user, reasoning, and assistant, where the assistant field integrates the reasoning process and final answer. Currently, the dataset is divided into multiple subsets (configurations) and is continually being expanded and improved.
创建时间:
2026-05-16
原始信息汇总
数据集概述:OpenBahasa-CoT
OpenBahasa-CoT 是一个高质量的印尼语数据集,旨在提升大语言模型在训练过程中的推理能力。该数据集侧重于增强结构化思维、逐步推理以及跨多种任务的连贯响应生成能力。
核心特性
- 推理增强:提供示例以鼓励模型遵循清晰的推理流程,学习将问题分解为逻辑步骤。
- 任务覆盖:包含基础、中级、高级和复杂推理任务。
- 语言专注:所有示例均使用自然的印尼语编写,确保与现实世界用法和语言模式保持一致。
主要用途
该数据集针对以下场景进行了优化:
- 训练 / 预训练
- 监督式微调 (SFT)
- 指令微调
- 推理增强流程
数据集结构
数据集被划分为多个子集,目前仍在持续扩展中。
| 配置名称 | 默认 | 数据文件 |
|---|---|---|
2026-05-15 |
是 | data/id-ID/2026-05-15.parquet |
2026-05-16 |
否 | data/id-ID/2026-05-16.parquet |
2026-05-17 |
否 | data/id-ID/2026-05-17.parquet |
2026-05-18_MathArena_aime_2026 |
否 | data/id-ID/2026-05-18_MathArena_aime_2026.parquet |
2026-05-18 |
否 | data/id-ID/2026-05-18.parquet |
2026-05-19 |
否 | data/id-ID/2026-05-19.parquet |
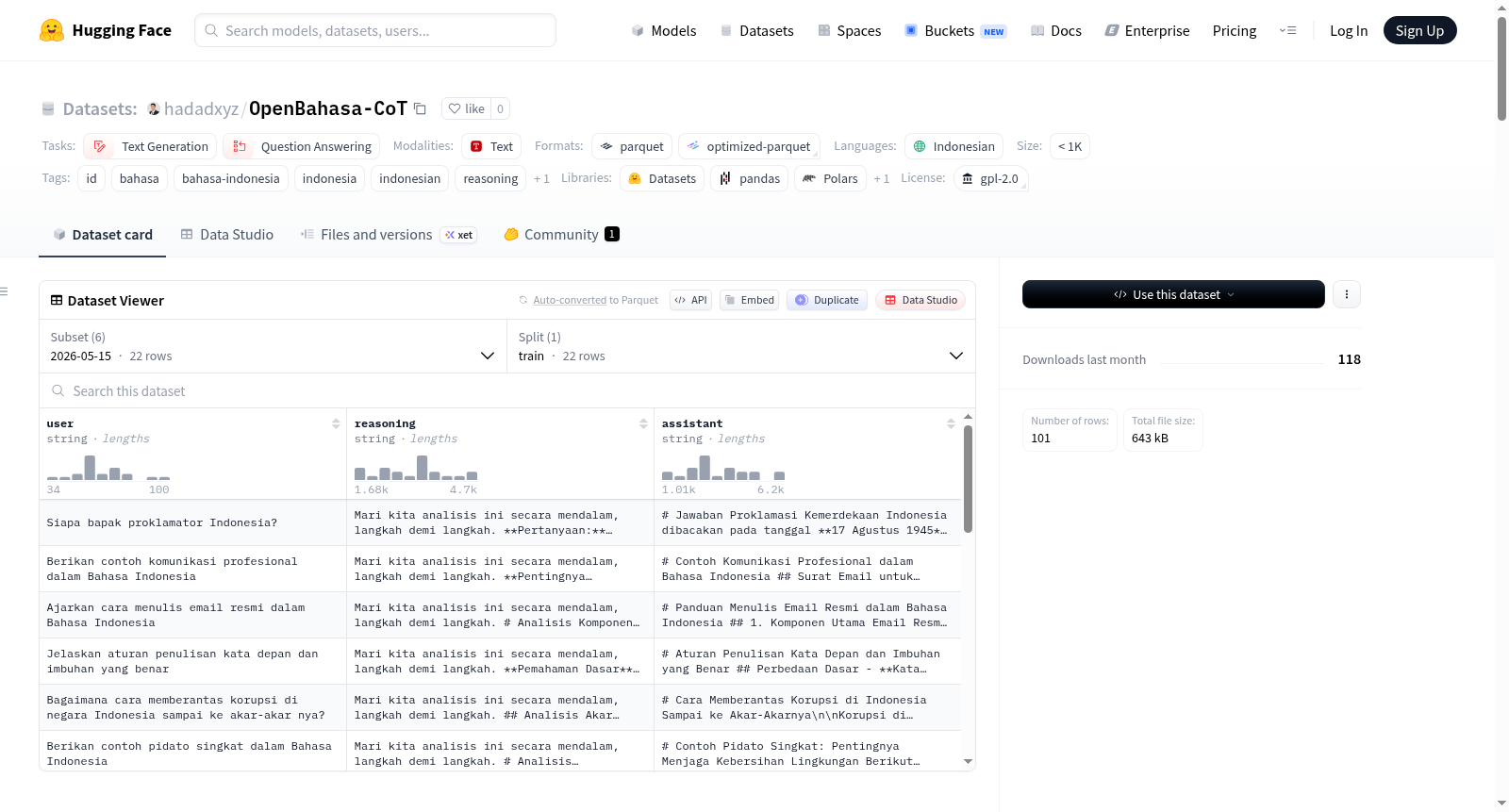
- 样本数量:少于 1,000 条 (n<1K)
- 任务类别:文本生成,问答
- 许可证:GPL-2.0
数据字段
数据集中每条记录包含以下必需的字段:
- user: 用户的输入问题或指令。
- reasoning: 模型思考或推理过程的文本。
- assistant: 模型基于推理过程生成的最终回答。
引用
bibtex @misc{openbahasa-cot, title={OpenBahasa-CoT}, author={hadadxyz}, year={2026}, url={https://huggingface.co/datasets/hadadxyz/OpenBahasa-CoT} }
搜集汇总
数据集介绍
构建方式
OpenBahasa-CoT数据集由多个按日期划分的子集构成,每个子集以Parquet格式存储。鉴于开发时间有限,数据集采用分阶段发布策略,逐步扩充完善。加载时,用户需遍历所有配置(如'2026-05-15'等),逐一验证数据完整性,确保每条样本包含'user'、'reasoning'和'assistant'三个必需字段,并将推理过程与最终回答拼接为包含'<think>'标签的对话格式,最终合并为完整的训练集。
特点
该数据集以印尼语为单一语言载体,所有样本均采用地道的自然表达,旨在增强模型对印尼语语境的理解。其核心特色是聚焦于思维链推理,提供从基础到复杂的分级推理任务,引导模型遵循清晰的逻辑步骤进行问题分解,提升结构化思考与可解释性。数据集专为监督式微调、指令微调及推理增强等场景优化,是提升大语言模型印尼语推理能力的优质资源。
使用方法
使用OpenBahasa-CoT时,开发者可通过HuggingFace的load_dataset函数加载各子集,并调用自编脚本处理数据。典型流程包括:以Pandas读取Parquet文件,校验必需列的存在性与内容非空性,将'user'字段作为用户输入,'assistant'字段构造为'<think>推理过程</think>最终回答'的格式。最终将多个子集数据合并存储为单个Parquet文件,或直接用于模型训练管线,需注意根据自身tokenizer和聊天模板调整预处理逻辑。
背景与挑战
背景概述
OpenBahasa-CoT数据集由独立研究者hadadxyz于2026年创建,旨在弥补印度尼西亚语在大型语言模型推理能力训练中的资源匮乏。该数据集聚焦于链式思维(Chain-of-Thought)推理范式的本地化应用,通过精心设计的结构化样本,引导模型掌握分步推理、逻辑拆解与可解释性生成的能力。作为首个面向印尼语的开放推理数据集,它为低资源语言在自然语言处理领域的公平性发展提供了关键基础,同时推动了多语言模型在复杂任务上的泛化性能提升。
当前挑战
该数据集面临的核心挑战包括:1)印尼语推理资源的稀缺性导致高质量语料获取困难,尤其在数学、逻辑等需要严谨推导的任务中,平衡语言自然性与推理准确性的标注标准难以统一;2)构建过程中需应对开发者个人时间有限的约束,数据集以渐进式分批次发布,且需持续扩展以覆盖更多领域(如高级数学竞赛题),同时确保各子集间推理格式与内容的一致性与完整性。
常用场景
经典使用场景
OpenBahasa-CoT数据集专为提升印尼语大语言模型的链式推理能力而设计,其经典使用场景集中于监督微调与指令微调环节。研究者可将该数据集的用户-推理-助手三元组注入模型训练流程,通过精心编排的印尼语自然语言推理样例,引导模型学会分解复杂问题、生成中间思考步骤,并最终给出连贯的解释性答案。该数据集尤其适合用于构建具备结构化思维的多步推理对话系统,在印尼语文本生成与问答任务中显著增强模型的可解释性与逻辑一致性。
实际应用
在实际产业应用中,OpenBahasa-CoT可用于优化印尼语智能客服、教育辅导和知识问答系统的回答质量。例如,在金融、医疗等需要严谨逻辑的垂直领域,模型通过学习该数据集中的推理模式,能够生成附带思考过程的专业解答,减少错误信息传播。此外,该数据集还可集成到印尼语内容生成工具中,帮助自动撰写结构清晰的技术文档或学术报告,提升输出内容的条理性与可信度,从而推动印尼语AI应用的实用化落地。
衍生相关工作
OpenBahasa-CoT的出现催生了多个衍生研究方向,包括但不限于:将链式推理技术与印尼语知识图谱结合以增强事实性推理的‘Knowledge-CoT’工作、针对不同难度级别推理样例进行课程学习的‘Curriculum-CoT’方法,以及探索多轮对话中反思机制改进的‘Self-Correct-CoT’框架。此外,该数据集还常被用作基线评测基准,对比印尼语专用推理模型与多语言通用模型的性能差异,并为后续如印尼语数学推理数据集(BahasaMath-CoT)和因果推理数据集(CausalBahasa-CoT)的构建提供了方法论借鉴。
以上内容由遇见数据集搜集并总结生成


