s-emanuilov/coco-clip-vit-l-14
收藏Hugging Face2024-03-29 更新2024-06-22 收录
下载链接:
https://hf-mirror.com/datasets/s-emanuilov/coco-clip-vit-l-14
下载链接
链接失效反馈官方服务:
资源简介:
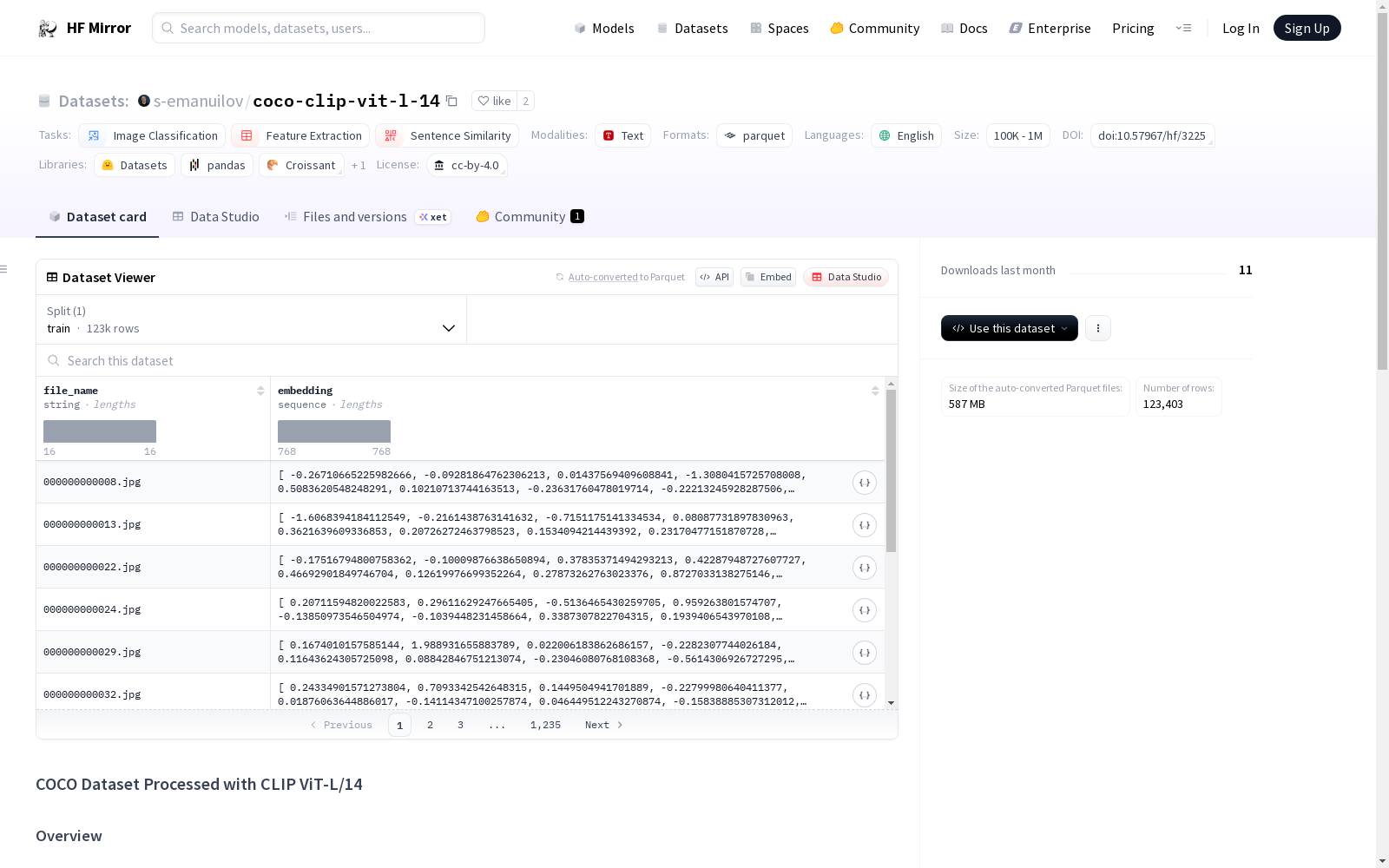
该数据集是使用OpenAI的CLIP ViT-L/14模型处理的COCO数据集的2017 Unlabeled images子集。原始数据集包含123K图像,约19GB大小,处理后生成786维向量。这些向量可用于语义搜索系统、图像相似性评估等应用。处理结果是一个包含每个文件路径及其对应嵌入的parquet文件,嵌入是OpenAI CLIP模型的直接输出,未进行归一化处理。
该数据集是使用OpenAI的CLIP ViT-L/14模型处理的COCO数据集的2017 Unlabeled images子集。原始数据集包含123K图像,约19GB大小,处理后生成786维向量。这些向量可用于语义搜索系统、图像相似性评估等应用。处理结果是一个包含每个文件路径及其对应嵌入的parquet文件,嵌入是OpenAI CLIP模型的直接输出,未进行归一化处理。
提供机构:
s-emanuilov
原始信息汇总
COCO Dataset Processed with CLIP ViT-L/14
概述
该数据集是COCO数据集(COCO Dataset)的“2017未标注图像”子集的加工版本,使用OpenAI的CLIP ViT-L/14模型处理。原始数据集包含约123K张图像,大小约为19GB,经过处理后生成786维向量。这些向量可用于语义搜索系统、图像相似性评估等多种应用。
原始数据集的直接下载链接:COCO 2017 Unlabeled Images
数据集描述
处理结果是一个包含每个文件路径及其对应嵌入的parquet文件。模型输出未进行归一化处理,嵌入是OpenAI CLIP模型的直接结果。
处理细节
我们旨在通过以下脚本生成相同的图像向量。我们的方法使用OpenAI的核心CLIP模型,类似于以下示例:
python import torch import clip from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu" model, preprocess = clip.load("ViT-L/14", device=device)
image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device) text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
with torch.no_grad(): image_features = model.encode_image(image) text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs)
应用
该数据集适用于多种AI驱动的应用,包括但不限于:
- 语义搜索系统
- 图像相似性检测
- 增强图像分类
搜集汇总
数据集介绍
构建方式
在计算机视觉研究领域,s-emanuilov/coco-clip-vit-l-14数据集是一项结合了最新深度学习技术的成果。该数据集由COCO数据集的2017年未标注图像子集经过CLIP ViT-L/14模型处理而成,旨在生成786维向量,这些向量直接来源于OpenAI的CLIP模型输出,未经任何归一化处理。
特点
本数据集的特征在于,它结合了COCO数据集的丰富图像资源和CLIP模型的强大特征提取能力。数据集以parquet文件形式存储,包含了每张图像的路径及其对应的嵌入向量,便于进行图像语义搜索、图像相似性评估等应用。
使用方法
用户可以通过直接下载原始的COCO未标注图像集,并使用提供的Python脚本,基于OpenAI的CLIP模型自行生成图像嵌入向量。该数据集的使用不依赖于特定的硬件环境,支持在具备CUDA或CPU计算能力的设备上运行,为研究者提供了便捷的图像特征处理工具。
背景与挑战
背景概述
在计算机视觉研究领域,图像数据集的构建与处理始终是推动技术发展的关键因素。COCO数据集,作为当代图像识别任务的重要资源,自2014年由Microsoft Research团队推出以来,便以其丰富的标注信息和广泛的应用场景而广受关注。s-emanuilov/coco-clip-vit-l-14数据集,是在2017年COCO数据集基础上,采用OpenAI的CLIP ViT-L/14模型进行处理的版本,旨在通过先进的模型提取图像特征,服务于语义搜索系统、图像相似性评估等AI应用,展现了深度学习技术在图像处理领域的最新进展。
当前挑战
尽管s-emanuilov/coco-clip-vit-l-14数据集提供了强大的图像特征向量,但在实际应用中仍面临诸多挑战。首先,数据集构建过程中的计算资源消耗巨大,对硬件设备提出了较高要求。其次,未经归一化的模型输出可能导致特征向量分布不均,影响后续任务的表现。此外,如何有效地利用这些高维特征向量进行图像分类、检索等任务,是当前研究的一大挑战。同时,数据集的泛化能力、在不同领域的适应性以及标注信息的完整性也是研究人员必须考虑的问题。
常用场景
经典使用场景
在人工智能研究的语境下,s-emanuilov/coco-clip-vit-l-14数据集以其独特的786维向量特性,成为图像分类与特征提取任务中的经典资源。其借助CLIP ViT-L/14模型对COCO数据集中的图像进行处理,不仅保留了图像的丰富信息,而且便于后续的向量运算和模型训练,为图像语义搜索和相似度评估提供了坚实基础。
实际应用
在实际应用层面,s-emanuilov/coco-clip-vit-l-14数据集的支持下,开发者能够构建出更加精确的语义搜索系统,优化图像相似度检测算法,提升图像分类的准确性,从而在电子商务、内容审核、智能监控等多个领域发挥重要作用。
衍生相关工作
基于此数据集,学术界和产业界衍生出众多相关工作,如改进的图像检索算法、跨模态任务的多模型融合研究,以及面向特定领域的图像分析工具开发,这些都进一步拓展了数据集的应用边界,推动了相关技术的进步。
以上内容由遇见数据集搜集并总结生成


